# Elasticsearch学习笔记
# 帮助文档
# 中文官方文档(较老)
https://www.elastic.co/guide/cn/elasticsearch/guide/current/getting-started.html#getting-started
# 英文最新文档(较新)
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/getting-started.html
# ES核心概念和原理
# 什么是搜索
百度、垂直搜索(站内搜索)。搜索:通过一个关键词或一段描述,得到你想要(相关度高)的结果
# 如何实现搜索功能
关系型数据库:性能差、不可靠、结果不准确(相关度低)
# 倒排索引、Lucene和全文检索
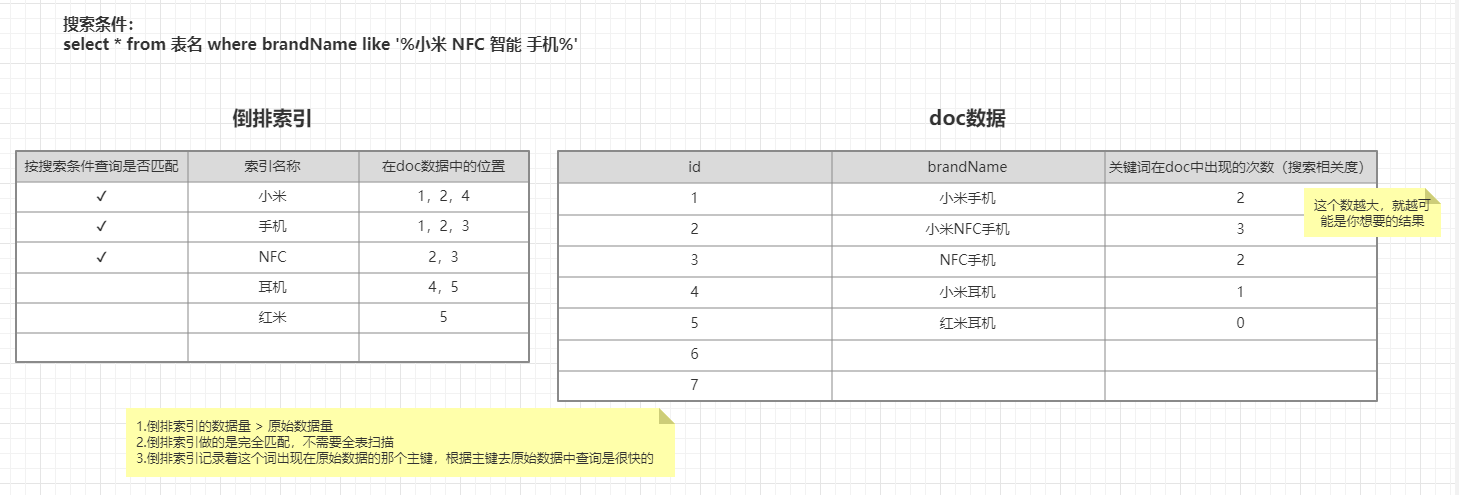
- 倒排索引的数据结构(存储的数据)
- 包含这个关键词的
document list - 关键词在每个doc中出现的次数
TF term frequency - 关键词在整个索引中出现的次数
IDF inverse doc frequency(值越大,代表相关度越低) - 关键词在当前
doc中出现的次数 - 每个
doc的长度,越长相关度越低 - 包含这个关键词的所有
doc的平均长度
- 包含这个关键词的
Lucene:jar包,帮我们创建倒排索引,提供了复杂的API- 如果用
Luncene做集群,会有哪些问题- 节点一旦宕机,节点数据丢失,后果不堪设想,可用性差
- 自己维护,麻烦(自己创建管理索引),单台节点的承载请求的能里是有限的,需要人工做负载。
# 倒排索引的特点
- 倒排索引的数据量 > 原始数据量
- 倒排索引做的是完全匹配,不需要全表扫描
- 倒排索引记录着这个词出现在原始数据的那个主键,根据主键去原始数据中查询是很快的
# Elasticsearch
- 特点
- 分布式
- 高性能
- 高可用
- 可伸缩
- 易维护
- 优点
- 面向开发者友好,屏蔽了Lucene的复杂特性,集群自动发现(cluster discovery)
- 自动维护数据在多个节点上的建立
- 会帮我们做搜索请求的负载均衡
- 自动维护冗余副本,保证了部分节点宕机的情况下仍然不会有任何数据丢失
ES基于Lucene提供了很多高级功能:复合查询、聚合分析、基于地理位置等- 对于大公司,可以构建几百台服务器的大型分布式集群,处理PB级别数据;对于小公司,开箱即用,门槛低上手简单
- 相比传统数据库,提供了全文检索,同义词处理(美丽的 cls > 漂亮的 cls),相关度排名。聚合分析以及海量数据的近实时(NTR)处理,这些传统数据库完全做不到
- 应用领域
- 百度(全文检索,高亮、搜索推荐)
- 各大网站的用户行为日志(用户点击、浏览、收藏、评论)
- BI(business Intelligence商业智能),数据分析,数据挖掘统计
- Github:代码托管平台,几千亿行代码
- ELK:Elasticsearch(数据存储)、Logstash(日志采集)、Kibana(可视化)
# ES 核心概念
cluster(集群):每个集群至少包含两个节点node:集群中的每个节点,一个节点不代表一台服务器field:一个数据字段,与index和type一起,可以定位一个docdocument:es最小的数据单元,通常是以json的形式存储的type:逻辑上的数据分类,es7.x中删除了type的概念index:一类相同或者类似的doc,比如一个员工索引,商品索引shard分片:P分片,R副本- 一个
index包含多个shard,默认5个分片,默认每个分片分配一个副本,分片的数量在创建索引的时候设置,如果想修改,需要重建索引 - 每个
shard都是一个lucene实例,有完整的创建索引的处理请求能力 - es会自动在
nodes上为我们做shard均衡 - 一个
doc是不可能同时存在与多个分片中的,但是可以存在于多个副本中 - 分片和对应的副本不能同时存在于同一个节点,所以最低的可用配置是两个节点,互为主备
- 一个
# 环境安装
# docker 安装配置 es
# 拉取镜像
docker pull elasticsearch:7.6.2
# 启动es
docker run -d -p 9200:9200 -p 9300:9300 --restart=always -e "discovery.type=single-node" --name=elasticsearch elasticsearch:7.6.2
# 修改配置
进入容器
docker exec -it elasticsearch bashvim config/elasticsearch.yml
cluster.name: "my-application" node.name: "node-1" network.host: 0.0.0.0重启容器
docker restart elasticsearch
# 访问地址
http://<IP>:<PORT>
http://192.168.21.123:9200/
# docker 安装配置 kibana
# 拉取镜像
docker pull kibana:7.6.2
# 启动kibana
docker run -d -p 5601:5601 --restart=always --name kibana kibana:7.6.2
# 出现的问题修改配置
如果出现以下页面:Kibana server is not ready yet,说明Kibana没有找到ES节点
进入容器
docker exec -it kibana bashvim config/kibana.yml
# # ** THIS IS AN AUTO-GENERATED FILE ** # # Default Kibana configuration for docker target server.name: kibana server.host: "0" # 中文配置 i18n.locale: "zh-CN" elasticsearch.hosts: [ "http://192.168.21.123:9200" ] xpack.monitoring.ui.container.elasticsearch.enabled: true重启容器
docker restart kibana
# 访问地址
http://<IP>:<PORT>
http://192.168.21.123:5601/
# es 健康检查
http://<IP>:9200/_cluster/health
http://192.168.21.123:9200/_cluster/health
# 集群状态
cluster_name集群名称status集群状态green代表健康;yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;red代表部分主分片不可用,可能已经丢失数据。number_of_nodes代表在线的节点总数量number_of_data_nodes代表在线的数据节点的数量active_shards存活的分片数量active_primary_shards存活的主分片数量 正常情况下shards的数量是pri的两倍relocating_shards迁移中的分片数量,正常情况为 0initializing_shards初始化中的分片数量,正常情况为 0unassigned_shards未分配的分片,正常情况为 0delayed_unassigned_shardsnumber_of_pending_tasks,准备中的任务,任务指迁移分片等,正常情况为 0number_of_in_flight_fetchtask_max_waiting_in_queue_millis任务最长等待时间active_shards_percent_as_number正常分片百分比 正常情况为 100%
# API
/_cat/allocation#查看单节点的shard分配整体情况/_cat/shards#查看各shard的详细情况/_cat/shards/{index}#查看指定分片的详细情况/_cat/master#查看master节点信息/_cat/nodes#查看所有节点信息/_cat/indices#查看集群中所有index的详细信息/_cat/indices/{index}#查看集群中指定index的详细信息/_cat/segments#查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占用大小, 是否刷盘/_cat/segments/{index}#查看指定index的segment详细信息/_cat/count#查看当前集群的doc数量/_cat/count/{index}#查看指定索引的doc数量/_cat/recovery#查看集群内每个shard的recovery过程.调整replica。/_cat/recovery/{index}#查看指定索引shard的recovery过程/_cat/health#查看集群当前状态:红、黄、绿/_cat/pending_tasks#查看当前集群的pending task/_cat/aliases#查看集群中所有alias信息,路由配置等/_cat/aliases/{alias}#查看指定索引的alias信息/_cat/thread_pool#查看集群各节点内部不同类型的threadpool的统计信息,/_cat/plugins#查看集群各个节点上的plugin信息/_cat/fielddata#查看当前集群各个节点的fielddata内存使用情况/_cat/fielddata/{fields}#查看指定field的内存使用情况,里面传field属性对应的值/_cat/nodeattrs#查看单节点的自定义属性/_cat/repositories#输出集群中注册快照存储库/_cat/templates#输出当前正在存在的模板信息
# 健康值状态
- Green:所有Primary和Replica均为active,集群健康
- Yellow:至少一个Replica不可用,但是所有Primary均为active,数据仍然是可以保证完整性的
- Red:至少有一个Primary为不可用状态,数据不完整,集群不可用
# ES节点有哪些类型
# 1. 主节点(Master node)
主节点的主要职责是负责集群层面的相关操作,管理集群变更,如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给哪些相关的节点
主节点也可以作为数据节点,但稳定的主节点对集群的健康是非常重要的,默认情况下任何一个集群中的节点都有可能被选为主节点,索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择
通过配置
node.master: true(默认)使节点具有被选举为Master的资格。主节点是全局唯一的,从有资格成为Master的节点中选举为了防止数据丢失,每个主节点应该知道有资格升为主节点的数量,默认为1,为了避免网络分区出现多主的情况,配置
discovery.zen.minimun_master_nodes原则上最小值应该为:(master_eligible_nodes/2)+1node.master: true node.data: false
# 2. 数据节点(Data node)
数据节点主要是存储索引数据的节点,执行数据相关操作:CRUD、搜索,聚合操作等。数据节点对cpu,内存,I/O要求较高, 在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
通过配置
node.data: true(默认来是一个节点成为数据节点),也可以通过下面配置创建一个数据节点node.master: false node.data: true node.ingest: false
# 3. 预处理节点(ingest node)
这是从5.0版本开始引入的概念。预处理操作运行在索引文档之前,即写入数据之前,通过事先定义好的一系列
processors(处理器)和pipeline(管道),对数据进行某种转换、富化。processors和pipeline拦截bulk和index请求,在应用相关操作后将文档传回给index或bulk API默认情况下,在所有的节点启用
ingest。如果想在某个节点上禁用ingest,则可以填写配置node.ingest: false,也可以通过下面的配置创建一个仅用于预处理的节点:node.master: false node.data: false node.ingest: true
# 4. 协调节点(Coordinating node)
客户端请求可以发送到集群的任何节点,每个节点都知道任意文档所处的位置,然后转发这些请求,收集数据并返回给客户端,处理客户端请求的节点称为协调节点。
协调节点将请求转发给保存数据的数据节点。每个数据节点在本地执行请求,并将结果返回给协调节点。协调节点收集完数据后,将每个数据节点的结果合并为单个全局结果。对结果收集和排序的过程可能需要很多CPU和内存资源。
通过下面配置创建一个仅用于协调的节点:
node.master: false node.data: false node.ingest: false
# 5. 部落节点(Trible node)
tribes功能允许部落节点在多个集群之间充当联合客户端- 部落节点是一个单独的节点,其主要工作是嗅探远程集群的集群状态,并将它们合并在一起。为了做到这一点,它加入了所有的远程集群,使它成为一个非特殊的节点,它不属于自己的集群,而是加入了多个集群。
- 也被称为
跨集群搜索的功能,该功能允许用户不仅跨本地索引,而且跨集群撰写搜索。这意味着可以搜索属于其他远程集群的数据。
# 6. 投票节点(voting node)
node.voting_only: true(仅投票节点,即使配置了data.master: true,也不会参选- 仍然可以作为数据节点
node.data: true
# ES如何实现高可用
- ES在分配单个索引的分片时会将每个分片尽可能分配到更多的节点上。但是,实际情况取决于集群拥有的分片和索引的数量以及它们的大小,不一定总是能均匀地分布
- ES不允许Primary和它的Replica放在同一个节点中,并且同一个节点不接受完全相同的两个Replica
- 同一个节点允许多个索引的分片同时存在
# ES容错机制
- Master选举(假如宕机节点是Master)
- 脑裂:可能会产生多个Master节点
- 解决:discovery.zen.minimum_master_nodes=N/2+1
Replica容错,新的(或者原有)Master节点会将丢失的Primary对应的某个副本提升为Primary- Master节点会尝试重启故障机
- 数据同步,Master会将宕机期间丢失的数据同步到重启机器对应的分片上去
# 如何提高ES分布式系统的可用性及性能最大化
- 每台节点的
shard数量越少,每个shard分配的CPU、内存和IO资源越多,单个shard的性能越好,当一台机器一个shard时,单个shard性能最好 - 稳定的
Master节点对于集群的健康非常重要!理论上讲,应该尽可能的减轻Master节点的压力,分片数量越多,Master节点维护管理shard的任务越重,并且节点可能就要承担更多的数据转发任务,可增加仅协调节点来缓解Master节点和Data节点的压力,但是在集群中添加过多的仅协调节点会增加整个集群的负担,因为选择的主节点必须等待每个节点的集群状态更新确认。 - 反过来说,如果相同资源分配相同的前提下,
shard数量越少,单个shard的体积越大,查询性能越低,速度越慢,这个取舍应根据实际集群状况和结合应用场景等因素综合考虑 data节点和Master节点一定要分开,集群规模越大,这样做的意义也就越大data节点处理与数据相关的操作,例如CRUD,搜索和聚合。这些操作是I/O,内存和CPU密集型的,所以他们需要更高配置的服务器以及更高的带宽,并且集群的性能冗余非常重要- 由于
仅投票节不参与Master竞选,所以和真正的Master节点相比,它需要的内存和CPU较少。但是,所有候选节点以及仅投票节点都可能是数据节点,所以他们都需要快速稳定低延迟的网络 - 高可用性(HA)群集至少需要三个主节点,其中
至少两个不是仅投票节点。即使其中一个节点发生故障,这样的群集也将能够选举一个主节点。生产环境最好设置3台仅Master候选节点(node.master = true node.data = true) - 为确保集群仍然可用,集群不能同时停止投票配置中的一半或更多节点。只要有一半以上的投票节点可用,集群仍可以正常工作。这意味着,如果存在三个或四个主节点合格的节点,则集群可以容忍其中一个节点不可用。如果有两个或更少的主机资格节点,则它们必须都保持可用
# Master选举流程
# findMaster
# 简单CURD
# 创建索引
# 格式
PUT /{indexName}?pretty
# demo
PUT /product?pretty
# 查询索引状态
GET /_cat/indices?v
# 删除索引
# 格式
DELETE /{indexName}?pretty
# demo
DELETE /product?pretty
# 查看索引信息
# 查看索引 map 映射信息
GET /product
# 查看索引数据
GET /product/_search
# 插入数据
PUT /product/_doc/1
{
"name" : "xiaomi phone",
"desc" : "shouji zhong de zhandouji",
"price" : 3999,
"tags": [ "xingjiabi", "fashao", "buka" ]
}
PUT /product/_doc/2
{
"name" : "xiaomi nfc phone",
"desc" : "zhichi quangongneng nfc,shouji zhong de jianjiji",
"price" : 4999,
"tags": [ "xingjiabi", "fashao", "gongjiaoka" ]
}
PUT /product/_doc/3
{
"name" : "nfc phone",
"desc" : "shouji zhong de hongzhaji",
"price" : 2999,
"tags": [ "xingjiabi", "fashao", "menjinka" ]
}
PUT /product/_doc/4
{
"name" : "xiaomi erji",
"desc" : "erji zhong de huangmenji",
"price" : 999,
"tags": [ "low", "bufangshui", "yinzhicha" ]
}
PUT /product/_doc/5
{
"name" : "hongmi erji",
"desc" : "erji zhong de kendeji",
"price" : 399,
"tags": [ "lowbee", "xuhangduan", "zhiliangx" ]
}
# 查询数据
# 查询单个document
# 格式
GET /{indexName}/_doc/{id}
# demo
GET /product/_doc/1
# 查看所有的document
# 格式
GET /{indexName}/_search
# demo
GET /product/_search
# 查询多个结果的排序
# 格式
GET /{indexName}/_search?sort=排序的字段:<asc><desc>
# demo
GET /product/_search?sort=price
GET /product/_search?sort=price:asc
GET /product/_search?sort=price:desc
GET /product/_search?q=price:2999&sort=price:desc
# 更新数据
# 全量更新(完全覆盖)
# 格式
PUT /{indexName}/_doc/{id}
json格式的数据
# demo
PUT /product/_doc/1
{
"name" : "xiaomi phone",
"desc" : "shouji zhong de zhandouji",
"price" : 3999,
"tags": [ "xingjiabi", "fashao", "buka" ]
}
# 增量更新
# 格式
POST /{indexName}/_doc/{id}/_update
{
"doc": json格式的数据
}
# demo
POST /product/_doc/1/_update
{
"doc":{
"price" : 23999
}
}
# 删除数据
先逻辑删除,没有立即删除,后续才会物理删除
# 格式
DELETE /{indexName}/_doc/{id}
# demo
DELETE /product/_doc/1
# ES 常用查询
# 1. search timeout
- 设置:默认没有
timeout,如果设置了timeout,那么会执行timeout机制 timeout机制:假设用户查询结果有1W条数据,但是需要10s才能查询完毕,但是用户设置了1s的timeout,那么不管当前一共查询到了多少数据,都会在1s后停止查询,并返回当前数据- 用法:GET /product/_search?timeout=1s/ms/m
# 2. query_string
- 查询所有:GET /product/_search
- 带参数:GET /product/_search?q=name:xiaomi
- 分页+排序:GET /product/_search?from=0&size=2&sort=price:asc
# 3. match_all:匹配所有
GET /product/_search
{
"query":{
"match_all": {}
}
}
# 4. match:name中包含“nfc”
GET /product/_search
{
"query": {
"match": {
"name": "nfc"
}
}
}
# 5. sort:按照加个倒序排序
GET /product/_search
{
"query": {
"multi_match": {
"query": "nfc",
"fields": ["name","desc"]
}
},
"sort": [
{
"price": "desc"
}
]
}
# 6. multi_match:根据多个字段查询一个关键词
name和desc中包含“nfc”
GET /product/_search
{
"query": {
"multi_match": {
"query": "nfc",
"fields": ["name","desc"]
}
},
"sort": [
{
"price": "desc"
}
]
}
# 7. _source:元数据,想要查询多个字段
① 例子中为只查询“name”和“price”字段。
GET /product/_search
{
"query":{
"match": {
"name": "nfc"
}
},
"_source": ["name","price"]
}
# 8. 分页:查询第一页(每页两条数据)
GET /product/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"price": "asc"
}
],
"from": 0,
"size": 2
}
# 9. 全文检索:term:不会被分词
查询不会被分词,eq相等匹配倒排索引;文档内容会被分词,相当于eq的是倒排索引
GET /product/_search
{
"query": {
"term": {
"name": "nfc"
}
}
}
GET /product/_search
{
"query": {
"term": {
"name": "nfc phone" 这里因为没有分词,所以查询没有结果
}
}
}
# 10. 全文检索:match:会被分词
GET /product/_search
{
"query": {
"match": {
"name": "xiaomi nfc zhineng phone"
}
}
}
#验证分词
GET /_analyze
{
"analyzer": "standard",
"text":"xiaomi nfc zhineng phone"
}
# 11. 短语搜索:match_phrase:和全文检索相反
GET /product/_search
{
"query": {
"match_phrase": {
"name": "nfc phone"
}
}
}
# 12. 查询过滤
bool:可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值must:必须满足(子查询必须出现在匹配的文档中,并将有助于得分)should:可能满足or(子查询可能会出现在匹配的文档中)must_not:必须不满足不计算相关度分数not(子查询不得出现在匹配的文档中,子句在过滤器上下文中执行,这意味着计分被忽略,并且子句被视为用于缓存)filter:过滤器不计算相关度分数,cache(子查询必须出现在匹配的文档中,但是不像must查询的分数将忽略。filter子句在filter上下文中优先执行,这意味着计分被忽略,并且子句被考虑用于缓存)minimum_should_match:参数指定should返回的文档必须匹配的子句的数量或百分比。如果bool查询包含至少一个should子句,而没有must或filter子句,则默认值为1。否则,默认值为0
# 1. bool单条件查询
首先筛选
name包含xiaomi phone并且价格大于1999的数据(不排序),然后搜索name包含xiaomianddesc包含shouji
GET /product/_search
{
"query": {
"bool":{
"must": [
{"match": { "name": "xiaomi"}},
{"match": {"desc": "shouji"}}
],
"filter": [
{"match_phrase":{"name":"xiaomi phone"}},
{"range": {
"price": {
"gt": 1999
}
}}
]
}
}
}
# 2. bool多条件
name包含xiaomi 不包含erji 描述里包不包含nfc都可以,价钱要大于等于4999
GET /product/_search
{
"query": {
"bool": {
# name中必须包含"xiaomi"
"must": [
{
"match": {"name": "xiaomi"}
}
],
# name中必须不能包含"erji"
"must_not": [
{
"match": {"name": "erji"}
}
],
# should中至少满足0个条件,参见下面的 minimum_should_match 的解释
"should": [
{
"match": {"desc": "nfc"}
}
],
# 筛选价格大于4999的doc
"filter": [
{
"range": {
"price": {"gt": 4999}
}
}
]
}
}
}
# 3. minimum_should_match的嵌套查询
GET /product/_search
{
"query": {
"bool":{
"must": [
{"match": { "name": "nfc"}}
],
"should": [
{"range": {
"price": {"gt":1999}
}},
{"range": {
"price": {"gt":3999}
}}
],
"minimum_should_match": 1
}
}
}
# demo
GET /product/_search
{
"query": {
"bool": {
"filter": {
"bool": {
"should": [
{ "range": {"price": {"gt": 1999}}},
{ "range": {"price": {"gt": 3999}}}
],
"must": [
{ "match": {"name": "nfc"}}
]
}
}
}
}
}
- 当
bool处在query上下文中时,如果must或者filter匹配了doc,那么should即便一条都不满足也可以召回doc- 当
bool处在父bool的filter上下文中时 或者bool处在query上下文且没有must/filter子句的时候,should至少匹配1个才能召回doc如果需要类似这种查询:where name='nfc phone' and (price='2999' or desc='shouji zhong de hongzhaji'),就有2种做法:
# 走嵌套bool,让should进入filter上下文:
GET /product/_search
{
"query": {
"bool": {
"filter": [
[
{"match_phrase": {"name": "nfc phone"}},
{"term": {"name": "nfc"}}
],
{
"bool": {
"should": [
{ "match_phrase": {"price": "2999"}},
{ "match_phrase": {"desc": "shouji zhong de hongzhaji"}}
]
}
}
]
}
}
}
# 走单bool,query上下文,需要显式指定minimum_should_match=1
GET /product/_search
{
"query": {
"bool": {
"filter": [
[
{"match_phrase": {"name": "nfc phone"}},
{"term": {"name": "nfc"}}
]
],
"should": [
{ "match_phrase": {"price": "2999"}},
{ "match_phrase": {"desc": "shouji zhong de hongzhaji"}}
],
"minimum_should_match": 1
}
}
}
# 其实作为一个可扩展的查询接口,一般来说嵌套bool表达力更丰富,扩展性更好,所以不建议用第二种方式开发业务
# 4. constant_score:不计算得分
当我们不关心检索词频率
TF(Term Frequency)对搜索结果排序的影响时,可以使用constant_score将查询语句query或者过滤语句filter包装起来
GET /product/_search
{
"query": {
"constant_score":{
"filter": {
"bool": {
"should":[
{"term":{"name":"xiaomi"}},
{"term":{"name":"nfc"}}
],
"must_not":[
{"term":{"name":"erji"}}
]
}
},
"boost": 1.2
}
}
}
# 13. Compound queries组合查询
想要一台带
NFC功能的 或者 小米的手机 但是不要耳机
SELECT * from product where (`name` like "%xiaomi%" or `name` like '%nfc%') AND `name` not LIKE '%erji%'
GET /product/_search
{
"query": {
"constant_score":{
"filter": {
"bool": {
"should":[
{"term":{"name":"xiaomi"}},
{"term":{"name":"nfc"}}
],
"must_not":[
{"term":{"name":"erji"}}
]
}
},
"boost": 1.2
}
}
}
搜索一台xiaomi nfc phone或者一台满足 是一台手机 并且 价格小于等于2999
SELECT * FROM product WHERE NAME LIKE '%xiaomi nfc phone%' OR (NAME LIKE '%phone%' AND price > 399 AND price <=999);
GET /product/_search
{
"query": {
"constant_score": {
"filter": {
"bool":{
"should":[
{
"match_phrase": {
"name":"xiaomi nfc phone"
}
},
{
"bool":{
"must":[
{"term":{"name":"phone"}},
{"range":{"price":{"lte":"2999"}}}
]
}
}
]
}
}
}
}
}
# 14. Highlight search高亮查询
GET /product/_search
{
"query" : {
"match_phrase" : {
"name" : "nfc phone"
}
},
"highlight":{
"fields":{
"name":{}
}
}
}
# 15. Deep paging
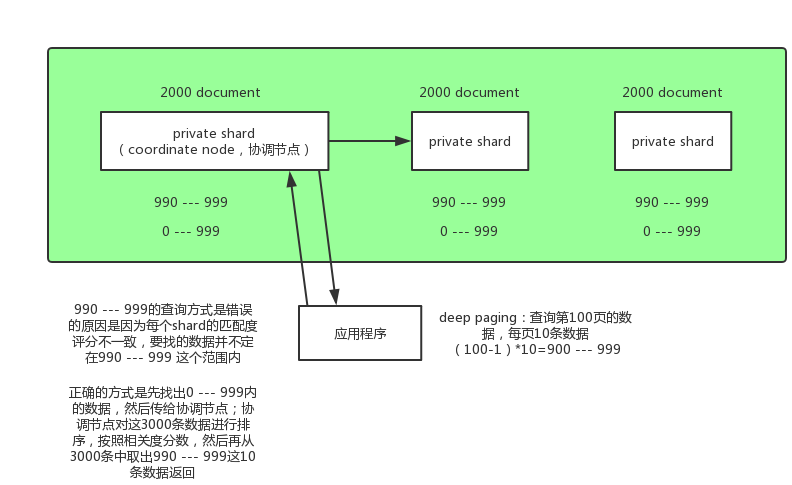
# 1. deep paging概念
查询的很深,比如一个索引有三个 primary shard,分别存储了6000条数据,我们要得到第100页的数据(每页10条),类似这种情况就叫deep paging
GET /product/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"price": "asc"
}
],
"from": 0,
"size": 2
}
# 2. 查询原理:如何得到第100页的10条数据?
# 错误的做法
在每个 shard 中搜索990到999这10条数据,然后用这30条数据排序,排序之后取10条数据就是要搜索的数据,这种做法是错的;因为3个 shard 中的数据的 _score 分数不一样,可能这某一个 shard 中第一条数据的 _score 分数比另一个 shard 中第1000条都高,所以在每个 shard 中搜索990到999这10条数据然后排序的做法是不正确的。
# 正确的做法
正确的做法是每个 shard 把0到999条数据全部搜索出来(按排序顺序),然后全部返回给 coordinate node,由 coordinate node 按 _score 分数排序后,取出第100页的10条数据,然后返回给客户端
# 3. 性能问题
- 消耗网络带宽,因为所搜过深的话,各
shard要把数据传递给coordinate node,这个过程是有大量数据传递的,消耗网络 - 消耗内存,各
shard要把数据传送给coordinate node,这个传递回来的数据,是被coordinate node保存在内存中的,这样会大量消耗内存 - 消耗
cup,coordinate node要把传回来的数据进行排序,这个排序过程很消耗cpu
# 4. 结论
鉴于deep paging的性能问题,所有应尽量减少使用
# 16. Scroll search
GET /product/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": [
{
"price": "desc"
}
],
"size": 2
}
GET /_search/scroll
{
# 每次查询更新scroll的时间,相当于延期
"scroll":"1m"
"scroll_id": ""
}
# 1. 基于scroll滚动技术实现大数据量搜索
如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scroll滚动查询,一批一批的查,直到所有数据都查询完为止。
scroll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的采用基于
_doc(不使用_score)进行排序的方式,性能较高每次发送
scroll请求,我们还需要指定一个scroll参数,指定一个时间窗口,每次搜索请求只要在这个事件窗口内能完成就可以了# sort默认是相关度排序("sort":[{"FIELD":{"order":"desc"}}]),不按_score排序,按_doc排序 # size设置的是每页显示的记录数 # 第一次查询会生成快照 GET /lib3/user/_search?scroll=1m #这一批查询在一分钟内完成 { "query":{ "match":{} }, "sort":[ "_doc" ], "size":3 } # 第二次查询通过第一次的快照ID来查询,后面以此类推 GET /_search/scroll { "scroll":"1m", "scroll_id":"" }
# 2. 基于 scroll 解决深度分页问题
原理上是对某次查询生成一个游标 scroll_id , 后续的查询只需要根据这个游标去取数据,直到结果集中返回的 hits 字段为空,就表示遍历结束。
注意:scroll_id 的生成可以理解为建立了一个临时的历史快照,在此之后的增删改查等操作不会影响到这个快照的结果。
使用 curl 进行分页读取过程如下:
- 先获取第一个 scroll_id,url 参数包括 /index/_type/ 和 scroll,scroll 字段指定了scroll_id 的有效生存期,以分钟为单位,过期之后会被es 自动清理。如果文档不需要特定排序,可以指定按照文档创建的时间返回会使迭代更高效
- 后续的文档读取上一次查询返回的
scroll_id来不断的取下一页,如果srcoll_id的生存期很长,那么每次返回的scroll_id都是一样的,直到该scroll_id过期,才会返回一个新的scroll_id。请求指定的scroll_id时就不需要 /index/_type 等信息了。每读取一页都会重新设置scroll_id的生存时间,所以这个时间只需要满足读取当前页就可以,不需要满足读取所有的数据的时间,1 分钟足以。 - 所有文档获取完毕之后,需要手动清理掉
scroll_id。虽然es会有自动清理机制,但是srcoll_id的存在会耗费大量的资源来保存一份当前查询结果集映像,并且会占用文件描述符。所以用完之后要及时清理。使用es提供的CLEAR_API来删除指定的scroll_id
# 3. 基于 search_after 实现深度分页
search_after 是 ES5.0 及之后版本提供的新特性,search_after 有点类似 scroll,但是和 scroll 又不一样,它提供一个活动的游标,通过上一次查询最后一条数据来进行下一次查询。search_after 分页的方式和 scroll 有一些显著的区别:首先它是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。
第一页的请求和正常的请求一样
GET /order/info/_search { "size": 10, "query": { "match_all" : { } }, "sort": [ {"date": "asc"} ] } # 返回结果 { "_index": "zmrecall", "_type": "recall", "_id": "60310505115909", "_score": null, "_source": { ... "date": 1545037514 }, "sort": [ 1545037514 ] }第二页的请求,使用第一页返回结果的最后一个数据的值,加上
search_after字段来取下一页。注意:使用search_after的时候要将from置为 0 或 -1。curl -XGET 127.0.0.1:9200/order/info/_search { "size": 10, "query": { "match_all" : { } }, "search_after": [1545037514], # 这个值与上次查询最后一条数据的sort值一致,支持多个 "sort": [ {"date": "asc"} ] }
# 4. 需要注意的点
- 如果
search_after中的关键字为654,那么654323的文档也会被搜索到,所以在选择search_after的排序字段时需要谨慎,可以使用比如文档的id或者时间戳等 search_after适用于深度分页+ 排序,因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求。- 返回的始终是最新的数据,在分页过程中数据的位置可能会有变更。这种分页方式更加符合
moa的业务场景
# 5. 番外篇:MOA业务场景
- 医疗大数据 看病更便捷
- 金融大数据 赚钱更给力
- 交通大数据 出行更方便
- 环保大数据 治污更给力
- 舆情大数据 网络管理利器
# 17. filter缓存原理
# ES 查询相关
# 1. 前缀搜索
以
xx开头的搜索,不计算相关度评分,和filter比,没有bitcache(filter的缓存,为了增加性能)。前缀搜索,尽量把前缀长度设置的更长,性能差。搜索原理:搜索的是倒排索引;搜索的关键字需要进行分词,分词后的每一个词都要进行全表扫描倒排索引进行匹配,引性能特别慢。index_prefixes: 默认min_chars:2,max_chars:5
# 前缀搜索
POST /my_index/_bulk
{ "index": { "_id": "1"} }
{ "text": "城管打电话喊商贩去摆摊摊" }
{ "index": { "_id": "2"} }
{ "text": "笑果文化回应商贩老农去摆摊" }
{ "index": { "_id": "3"} }
{ "text": "老农耗时17年种出椅子树" }
{ "index": { "_id": "4"} }
{ "text": "夫妻结婚30多年AA制,被城管抓" }
{ "index": { "_id": "5"} }
{ "text": "黑人见义勇为阻止抢劫反被铐住" }
# 查不出结果的原因是:使用了es的默认分词器,对中文支持的不太友好,这个分词器会把中文一个字一个字的拆开
GET my_index/_search
{
"query": {
"prefix": {
"text": {
"value": "城管"
}
}
}
}
# 测试默认中文分词器
GET /_analyze
{
"text": "城管打电话喊商贩去摆摊摊",
"analyzer": "standard"
}
# 前缀搜索
POST /my_index/_bulk
{ "index": { "_id": "1"} }
{ "text": "my english" }
{ "index": { "_id": "2"} }
{ "text": "my english is good" }
{ "index": { "_id": "3"} }
{ "text": "my chinese is good" }
{ "index": { "_id": "4"} }
{ "text": "my japanese is nice" }
{ "index": { "_id": "5"} }
{ "text": "my disk is full" }
# 英文默认分词器是好用的
GET /_analyze
{
"text": "my chinese is good",
"analyzer": "standard"
}
# 英文的前缀搜索是好用的
GET my_index/_search
{
"query": {
"prefix": {
"text": "ch"
}
}
}
# 设置默认的 启动索引 加快前缀搜索速度 index_prefixes: 默认min_chars:2, max_chars:5;es 会根据设置的参数建立倒排索引
PUT my_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"index_prefixes": {
"min_chars":2,
"max_chars":4
}
}
}
}
}
# 2. 通配符搜索
GET my_index/_search
{
"query": {
"wildcard": {
"text": {
"value": "eng?ish"
}
}
}
}
# 数据还是用的之前的 product 索引的数据
# 匹配的是倒排索引
GET product/_search
{
"query": {
"wildcard": {
"name": {
"value": "xia?mi"
}
}
}
}
# 数据还是用的之前的 product 索引的数据
# 匹配的是文档数据
GET product/_search
{
"query": {
"wildcard": {
"name.keyword": {
"value": "xiaomi*nfc*",
"boost": 1.0
}
}
}
}
# 3. 正则搜索
regexp查询的性能可以根据提供的正则表达式而有所不同。为了提高性能,应避免使用通配符模式,如.*或 .*?+未经前缀或后缀。flags参数值:
ALL(Default):启用所有可选操作符。COMPLEMENT:启用~操作符。可以使用~对下面最短的模式进行否定。例如:- a~bc # matches 'adc' and 'aec' but not 'abc'
INTERVAL:启用<>操作符。可以使用<>匹配数值范围。例如:foo<1-100> # matches 'foo1', 'foo2' ... 'foo99', 'foo100'
foo<01-100> # matches 'foo01', 'foo02' ... 'foo99', 'foo100'
INTERSECTION:启用&操作符,它充当AND操作符。如果左边和右边的模式都匹配,则匹配成功。例如:- aaa.+&.+bbb # matches 'aaabbb'
ANYSTRING:启用@操作符。您可以使用@来匹配任何整个字符串。您可以将@操作符与&和~操作符组合起来,创建一个“everything except”逻辑。例如:- @&~(abc.+) # matches everything except terms beginning with 'abc'
# 正则搜索
GET product/_search
{
"query": {
"regexp": {
"name": {
"value": "[\\s\\S]*nfc[\\s\\S]*",
"flags": "ALL",
"max_determinized_states": 10000,
"rewrite": "constant_score"
}
}
}
}
# 更新数据
PUT /product/_doc/1
{
"testid":"123456",
"text":"shouji zhong 2020-05-20 de zhandouji"
}
GET /_analyze
{
"text": "shouji zhong 2020-05-20 de zhandouji",
"analyzer": "ik_max_word"
}
# 为什么没有结果,因为默认的标准分词器会把2020-05-20分成3个词,倒排索引中没有2020-05-20
GET product/_search
{
"query": {
"regexp": {
"text": {
"value": ".*2020-05-20.*",
"flags": "ALL"
}
}
}
}
# 这样就可以查出来结果,但是不建议使用这种方式,性能特别慢
GET product/_search
{
"query": {
"regexp": {
"text.keyword": {
"value": ".*2020-05-20.*",
"flags": "ALL"
}
}
}
}
# 创建索引时设置分词器
PUT my_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
# 插入数据
PUT /my_index/_doc/1
{
"testid":"123456",
"text":"shouji zhong 2020-05-20 de zhandouji"
}
# 使用ik分词器进行查询方式二
GET /my_index/_search
{
"query": {
"regexp": {
"text": {
"value": ".*2020-05-20.*",
"flags": "ALL"
}
}
}
}
# flags:INTERVAL方式查询
GET my_index/_search
{
"query": {
"regexp": {
"text": {
"value": ".*<1-4>.*",
"flags": "INTERVAL"
}
}
}
}
GET product/_search
{
"query": {
"regexp": {
"desc": {
"value": ".*zh~eng.*",
"flags": "INTERVAL"
}
}
}
}
# 4. 模糊搜索:fuzzy
# 模糊的几种情况
- 混淆字符 (box → fox)
- 缺少字符 (black → lack)
- 多出字符 (sic → sick)
- 颠倒次序 (act → cat)
# fuzzy的参数
value:要搜索的关键字fuzziness:(可选,字符串)最大误差 并非越大越好,召回率高 但是结果不准确两段文本之间的
Damerau-Levenshtein距离是使一个字符串与另一个字符串匹配所需的插入、删除、替换和调换的数量- 距离公式:
Levenshtein是lucene的,es改进版:Damerau-Levenshtein,
axe=>aexLevenshtein=2Damerau-Levenshtein=1- 距离公式:
max_expansions:(可选,整数)匹配的最大词项数量。默认为50prefix_length:创建扩展时保留不变的开始字符数。默认为0避免在
max_expansions参数中使用较高的值,尤其是当prefix_length参数值为时0。max_expansions由于检查的变量数量过多,参数中的高值 可能导致性能不佳transpositions:(可选,布尔值)指示编辑是否包括两个相邻字符的变位(ab→ba)。默认为truerewrite:(可选,字符串)用于重写查询的方法:https://www.elastic.co/cn/blog/found-fuzzy-search#performance-considerations
# 查询语句
GET /my_index/_search
{
"query": {
"fuzzy": {
"text": {
"value": "shouai",
"fuzziness": 2
}
}
}
}
# shouai容错的搜索结果
{
"_source" : {
"testid" : "123456",
"text" : "shouji zhong 2020-05-20 de zhandouji"
}
}
GET /my_index/_search
{
"query": {
"fuzzy": {
"text": {
"value": "shouai",
"fuzziness": "AUTO"
}
}
}
}
# 5. match_phrase_prefix讲解
match_phrase_prefix与match_phrase相同,但是它多了一个特性,就是它允许在文本的最后一个词项(term)上的前缀匹配;如果 是一个单词,比如a,它会匹配文档字段所有以a开头的文档,如果是一个短语,比如 this is ma,他会先在倒排索引中做以ma做前缀搜索,然后在匹配到的doc中做match_phrase查询,(网上有的说是先match_phrase,然后再进行前缀搜索, 是不对的)
# 参数
analyzer指定何种分析器来对该短语进行分词处理max_expansions限制匹配的最大词项boost用于设置该查询的权重slop允许短语间的词项(term)间隔
slop参数告诉match_phrase查询词条相隔多远时仍然能将文档视为匹配 什么是相隔多远? 意思是说为了让查询和文档匹配你需要移动词条多少次?
# ES 查询总结
# match、term、match_phrase、query_string的区别 (opens new window)
# 准备数据
# 插入数据
PUT /product/_doc/1
{
"name" : "xiaomi phone",
"desc" : "shouji zhong de zhandouji",
"price" : 3999,
"tags": [ "xingjiabi", "fashao", "buka" ]
}
PUT /product/_doc/2
{
"name" : "xiaomi nfc phone",
"desc" : "zhichi quangongneng nfc,shouji zhong de jianjiji",
"price" : 4999,
"tags": [ "xingjiabi", "fashao", "gongjiaoka" ]
}
PUT /product/_doc/3
{
"name" : "nfc phone",
"desc" : "shouji zhong de hongzhaji",
"price" : 2999,
"tags": [ "xingjiabi", "fashao", "menjinka" ]
}
PUT /product/_doc/4
{
"name" : "xiaomi erji",
"desc" : "erji zhong de huangmenji",
"price" : 999,
"tags": [ "low", "bufangshui", "yinzhicha" ]
}
PUT /product/_doc/5
{
"name" : "hongmi erji",
"desc" : "erji zhong de kendeji",
"price" : 399,
"tags": [ "lowbee", "xuhangduan", "zhiliangx" ]
}
# match
# 查询所有
GET /product/_search
{
"query":{
"match_all": {}
}
}
# match分词,text也分词,只要match的分词结果和text的分词结果有相同的就匹配
# nfc phone会被分成两个词,分别匹配倒排索引
GET /product/_search
{
"query": {
"match": {
"name": "nfc phone"
}
}
}
# match会被分词,而keyword不会被分词,match的需要跟keyword的完全匹配可以
GET /product/_search
{
"query": {
"match": {
"name.keyword": "xiaomi nfc phone"
}
}
}
# term
# term 查询关键字不会被分词,倒排所用中没有'nfc phone'这个词,所以查询不到结果
GET /product/_search
{
"query": {
"term": {
"name": "nfc phone"
}
}
}
# text字段会分词,而term 查询关键字不会被分词,所以term查询的条件必须是text字段分词后的某一个才可以
GET /product/_search
{
"query": {
"term": {
"name": "nfc"
}
}
}
# term 查询关键字不会被分词,而keyword字段也不分词。需要完全匹配才可
GET /product/_search
{
"query": {
"term": {
"name.keyword": "nfc phone"
}
}
}
# match_phrase
# match_phrase是分词的,text也是分词的。match_phrase的分词结果必须在text字段分词中都包含(且不支持前缀搜索),而且顺序必须相同,而且必须都是连续的
GET /product/_search
{
"query": {
"match_phrase": {
"desc": "shouji zhong"
}
}
}
# match_phrase是分词的,而keyword字段不分词。需要完全匹配才可
GET /product/_search
{
"query": {
"match_phrase": {
"desc.keyword": "shouji zhong"
}
}
}
# query_string
# query_string是分词的,text也是分词的。分词之后,每一个词可支持前缀搜索,故不要求顺序
GET /product/_search
{
"query": {
"query_string": {
"query": "zhong shouji",
"fields": ["desc"]
}
}
}
# query_string是分词的,而keyword字段不分词。需要完全匹配才可
GET /product/_search
{
"query": {
"query_string": {
"query": "shouji zhong de zhandouji",
"fields": ["desc.keyword"]
}
}
}
# Mapping
# 1. 概念
mapping就是ES数据字段field的type元数据,ES在创建索引的时候,dynamic mapping会自动为不同的数据指定相应mapping,mapping中包含了字段的类型、搜索方式(exact value或者full text)、分词器等。
# 2. 查看mapping
GET /product/_mappings
# 3. 动态mapping
- Elasticsearch:text / keyword
- 123456 => long ?为什么不是
integer - 123.123 => double 实际是
float类型 - true false => boolean
- 2020-05-20 => date
为啥
123456是long类型而不是integer?因为es的mapping_type是由JSON分析器检测数据类型,而Json没有隐式类型转换(integer=>longorfloat=>double),所以dynamic mapping会选择一个比较宽的数据类型。
# 4. 搜索方式
- exact value 精确匹配:在倒排索引过程中,分词器会将
field作为一个整体创建到索引中 - full text全文检索: 分词、近义词同义词、混淆词、大小写、词性、过滤、时态转换等
# 搜索所有字段包含de的doc
GET /product/_search?q=de
# 搜索name字段包含de的doc
GET /product/_search?q=name:de
# name.keyword 不会被分词,有点儿类似 match_phrase 短语搜索,eq文档doc的属性
GET /product/_search
{
"query": {
"match": {
"name.keyword": "xiaomi phone"
}
}
}
GET /product/_search
{
"query": {
"match_phrase": {
"name": "xiaomi phone"
}
}
}
# 全文检索可能会搜索出多条结果 eq倒排索引
GET /product/_search
{
"query": {
"match": {
"name": "xiaomi phone"
}
}
}
# 5. ES数据类型
# 1. 核心类型
数字类型
- long
- integer
- short
- byte
- double
- float
- half_float
- scaled_float
- 在满足需求的情况下,尽可能选择范围小的数据类型
字符串
keyword:适用于索引结构化的字段,可以用于过滤、排序、聚合。
keyword类型的字段只能通过精确值搜索列。ID应该用keywordtext:当一个字段是要被全文搜索的,比如
Email内容、产品描述,这些字段应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引之前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。解释一下为啥不会为
text创建索引:字段数据会占用大量堆空间,尤其是在加载高基数text字段时。字段数据一旦加载到堆中,就在该段的生命周期内保持在那里。同样,加载字段数据是一个昂贵的过程,可能导致用户遇到延迟问题。这就是默认情况下禁用字段数据的原因。有时,在同一字段中同时具有全文本
text和关键字keyword版本会很有用:一个用于全文本搜索,另一个用于聚合和排序date(时间类型):exact value
boolean(布尔类型)
binary(二进制):binary
range(区间类型):integer_range、float_range、long_range、double_range、date_range
# 2. 复杂类型
- Object:用于单个JSON对象
- Nested:用于JSON对象数组
# 3. 地理位置
- Geo-point:纬度 / 经度积分
- Geo-shape:用于多边形等复杂形状
# 4. 特有类型
- IP地址:ip 用于IPv4和IPv6地址
- Completion:提供自动完成建议
- Tocken_count:计算字符串中令牌的数量
- Murmur3 (opens new window):在索引时计算值的哈希并将其存储在索引中
- Annotated-text (opens new window):索引包含特殊标记的文本(通常用于标识命名实体)
- Percolator (opens new window):接受来自query-dsl的查询
- Join:为同一索引内的文档定义父/子关系
- Rank features (opens new window):记录数字功能以提高查询时的点击率。
- Dense vector (opens new window):记录浮点值的密集向量。
- Sparse vector (opens new window):记录浮点值的稀疏向量。
- Search-as-you-type (opens new window):针对查询优化的文本字段,以实现按需输入的完成
- Alias (opens new window):为现有字段定义别名。
- Flattened (opens new window):允许将整个JSON对象索引为单个字段。
- Shape (opens new window):shape 对于任意笛卡尔几何。
- Histogram (opens new window):histogram 用于百分位数聚合的预聚合数值。
- Constant keyword (opens new window):keyword当所有文档都具有相同值时的情况的 专业化。
# 5. Array(数组)
在Elasticsearch中,数组不需要专用的字段数据类型。默认情况下,任何字段都可以包含零个或多个值,但是,数组中的所有值都必须具有相同的数据类型。
# 6. ES7新增
- Date_nanos:date plus 纳秒
- Features:
- Vector:as
# 6. 手工创建Mapping
# 格式
PUT /{indexName}
{
"mappings": {
"properties": {
"field": {
"mapping_parameter": "parameter_value"
}
}
}
}
# 手工创建 mappings
PUT /product3
{
"mappings": {
"properties": {
"date": {
"type": "text"
},
"desc": {
"type": "text",
"analyzer": "english"
},
"name": {
"type": "text",
"index": "false"
},
"price": {
"type": "long"
},
"tags": {
"type": "text",
"index": "true"
},
"parts": {
"type": "object"
},
"partlist": {
"type": "nested"
}
}
}
}
# 查看 mapping
GET /product3/_mapping
# 插入数据
PUT /product3/_doc/1
{
"name": "xiaomi phone",
"desc": "shouji zhong de zhandouji",
"count": 123456,
"price": 3999,
"date": "2020-05-20",
"isdel": false,
"tags": [
"xingjiabi",
"fashao",
"buka"
],
"parts": {
"name": "adapter",
"desc": "5V 2A"
},
"partlist": [
{
"name": "adapter",
"desc": "5V 2A"
},
{
"name": "USB-C",
"desc": "5V 2A 1.5m"
},
{
"name": "erji",
"desc": "boom"
}
]
}
# 查看数据
GET /product3/_search
{
"query": {
"match_all": {}
}
}
# 7. Mapping parameters
index:是否对创建对当前字段创建索引,默认true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在source元数据中展示analyzer:指定分析器(character filter、tokenizer、Token filters)。boost:对当前字段相关度的评分权重,默认1coerce:是否允许强制类型转换 true “1”=> 1 false “1”=< 1copy_to:"field": { "type": "text", "copy_to": "other_field_name" }doc_values:为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间(不支持text和annotated_text)dynamic:控制是否可以动态添加新字段- true 新检测到的字段将添加到映射中。(默认)
- false 新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中。这些字段不会添加到映射中,必须显式添加新字段。
- strict 如果检测到新字段,则会引发异常并拒绝文档。必须将新字段显式添加到映射中
eager_global_ordinals:用于聚合的字段上,优化聚合性能。Frozen indices(冻结索引):有些索引使用率很高,会被保存在内存中,有些使用率特别低,宁愿在使用的时候重新创建,在使用完毕后丢弃数据,Frozen indices的数据命中频率小,不适用于高搜索负载,数据不会被保存在内存中,堆空间占用比普通索引少得多,Frozen indices是只读的,请求可能是秒级或者分钟级。eager_global_ordinals不适用于Frozen indices
enable:是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,仍然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。PUT my_index { "mappings": { "enabled": false } } PUT my_index { "mappings": { "properties": { "session_data": { "type": "object", "enabled": false } } } }注意:enable只能在最顶层,并且type为object的时候设置才生效。
fielddata:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建正排索引doc_values并保存到JVM的堆中,一定要慎用。fields:给field创建多字段,用于不同目的(全文检索或者聚合分析排序)format:格式化"date": { "type": "date", "format": "yyyy-MM-dd" }ignore_above:超过长度将被忽略ignore_malformed:忽略类型错误PUT my_index{ "mappings": { "properties": { "number_one": { "type": "integer", "ignore_malformed": true }, "number_two": { "type": "integer" } } } } PUT my_index/_doc/1{ "text": "Some text value", "number_one": "foo" //虽然有异常 但是不抛出 } PUT my_index/_doc/2{ "text": "Some text value", "number_two": "foo" //数据格式不对 }index_options:控制将哪些信息添加到反向索引中以进行搜索和突出显示。仅用于text字段Index_phrases:提升exact_value查询速度,但是要消耗更多磁盘空间Index_prefixes:前缀搜索min_chars:前缀最小长度,>0,默认2(包含)max_chars:前缀最大长度,<20,默认5(包含)"index_prefixes": { "min_chars" : 1, "max_chars" : 10 }
meta:附加元数据normalizer:norms:是否禁用评分(在filter和聚合字段上应该禁用)null_value:为null值设置默认值("null_value": "NULL")position_increment_gap:proterties:除了mapping还可用于object的属性设置search_analyzer:设置单独的查询时分析器PUT my_index{ "settings": { "analysis": { "filter": { "autocomplete_filter": { "type": "edge_ngram", "min_gram": 1, "max_gram": 20 } }, "analyzer": { "autocomplete": { "type": "custom", "tokenizer": "standard", "filter": [ "lowercase", "autocomplete_filter" ] } } } }, "mappings": { "properties": { "text": { "type": "text", "analyzer": "autocomplete", "search_analyzer": "standard" } } } } PUT my_index/_doc/1{ "text": "Quick Brown Fox" } GET my_index/_search{ "query": { "match": { "text": { "query": "Quick Br", "operator": "and" } } } }similarity:为字段设置相关度算法,支持BM25、claassic(TF-IDF)、booleanstore:设置字段是否仅查询term_vector:
# 聚合查询
# 1. bucket 和 metirc == group by
| bucket(item) | metirc(count) |
|---|---|
| 北京 | 100 |
| 天津 | 99 |
| 河北 | 98 |
# 2. 语法
"aggs": {
code...
}
# 3. 以tag维度每个产品的数量,即每个标签
GET /product/_search
{
"aggs": {
"tag_agg_group": {
"terms": {
"field": "tags.keyword"
}
}
},
# 不加这个会把原始的doc也查出来
"size": 0
}
# 4. 在 3 的基础上增加:价格大于1999的数据
GET /product/_search
{
"query": {
"bool": {
"filter": [
{
"range": {"price": {"gt": 1999}}
}
]
}
},
"aggs": {
"tag_agg_group": {
"terms": {
"field": "tags.keyword"
}
}
},
# 不加这个会把原始的doc也查出来
"size": 0
}
# 5. 价格大于1999的每个tag产品的平均价格
GET /product/_search
{
"aggs": {
"tag_agg_avg": {
"terms": {
"field": "tags.keyword",
"order": {
"avg_price": "desc"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
},
# 不加这个会把原始的doc也查出来
"size":0
}
# 6. 自定义聚合
按照千元机:1000以下 中端机:2000-3000 高端机:3000以上分组聚合,分别计算数量
GET /product/_search
{
"aggs": {
"tag_agg_group": {
"range": {
"field": "price",
"ranges": [
{
"from": 100,
"to": 1000
},
{
"from": 1000,
"to": 3000
},
{
"from": 3000
}
]
},
"aggs": {
"price_agg": {
"avg": {
"field": "price"
}
}
}
}
},
# 不加这个会把原始的doc也查出来
"size": 0
}
# 7. mget:批量查询
# 语法
GET /_mget
GET /<index>/_mget
# demo
# 批量查询不同索引的结果
GET /_mget
{
"docs": [
{
"_index": "product",
"_id": 2
},
{
"_index": "product",
"_id": 3
}
]
}
# 批量查询同一个索引的不同ID
#封装,把索引名(product提取出来)
GET /product/_mget
{
"docs": [
{
"_id": 2
},
{
"_id": 3
}
]
}
GET /product/_mget
{
"ids":[2,3]
}
#include包含哪些字段 exclude排除哪些字段
GET /product/_mget
{
"docs": [
{
"_id": 2,
"_source": false
},
{
"_id": 3,
"_source": [
"name",
"price"
]
},
{
"_id": 4,
"_source": {
"include": [
"name"
],
"exclude":[
"price"
]
}
}
]
}
# 8. bulk:批量增删改
# 语法格式
POST /_bulk
POST /<index>/_bulk
{"action": {"metadata"}}
{"data"}
- Operate:
create:如果id已经存在,则报错;不存在,则插入delete:删除(lazy delete原理)index:可以是创建,也可以是全量替换update:执行partial update(全量替换,部分替换)- 这么做的好处是为了节省内存,普通的插入方式会在
es内部序列化反序列化成一个个对象,采用bulk方式不需要序列化反序列化对象,从而节省了内存的开销
#手动指定id和自动生成(正常方式)
PUT /test_index/_doc/1/
{
"field":"test"
}
PUT /test_index/_doc/1/_create
{
"field":"test"
}
PUT /test_index/_create/1/
{
"field":"test"
}
#自动生产id(guid)
POST /test_index/_doc
{
"field":"test"
}
# bulk方式操作数据
POST /_bulk
{"create":{"_index":"product2", "_id":"1", "retry_on_conflict":"3"}}
{"name":"_buld create1"}
{"create":{"_index":"product2", "_id":"12"}}
{"name":"_buld create12"}
{"delete":{"_index":"product2", "_id":"11"}}
{"update":{"_index":"product2", "_id":"12"}}
{"doc":{"name":"_buld create22"}}
{"index":{"_index":"product2", "_id":"12"}}
{"doc":{"name":"_buld create2222222"}}
{"index":{"_index":"product2", "_id":"11"}}
{"doc":{"name":"_buld create111"}}
# retry_on_conflict:冲突重试
# index 存在则全量替换,不存在则创建
# POST /_bulk?filter_path=items.*.error 只显示失败的结果
# 9. ES 并发冲突问题
悲观锁:各种情况,都加锁,读写锁、行级锁、表级锁。使用简单,但是并发能力很低
乐观锁:并发能力高,操作麻烦,每次
no-query操作都需要比对version?version=2&&version_type=external # `if_seq_no` and `if_primary_term`
# ES底层原理
# 图解正排索引和倒排索引

如果使用倒排索引做聚合操作,会对倒排索引进行多次全表扫描,从而降低了查询效率
# 正排索引doc_values和倒排索引的区别
- 倒排索引的优势在于查找包含某个项的文档,即用于搜索查询;相反正排索引的优势是确定哪些项是否存在单个文档里
- 倒排索引和正排索引均是在
index-time时创建,保存再Lucene文件中(序列化到磁盘) doc_values使用非JVM内存,gc友好- 不分词的
field会在index-time时生成正排索引,聚合时直接使用正排索引,而分词的field在创建索引时是没有正排索引的,如果没有创建doc_values的字段需要做聚合查询时,name需要将fielddata打开,设置为true。此时会在执行查询的时候,动态在JVM的堆内存空间创建正排索引。
# 正排索引doc_values和fielddata
- 与
doc_value不同,当没有doc_value的字段需要聚合时,需要打开fielddata,然后临时在内存中建立正排索引,fielddata的构建和管理发生在JVM Heap中 fielddata默认是不器用的,因为text的字段比较长,一般只做关键字分词和搜索,很少拿他来进行全文匹配、聚合、排序等操作ES采用了circuit breaker熔断机制避免fielddata一次性超过物理内存大小而导致内存溢出,如果触发熔断,查询会被终止并返回异常fielddata使用的是JVM内存,doc_value在内存不足时会静静的待在磁盘中,而当内存充足时,会缓存到内存里以提升性能
# ES 流程核心概念
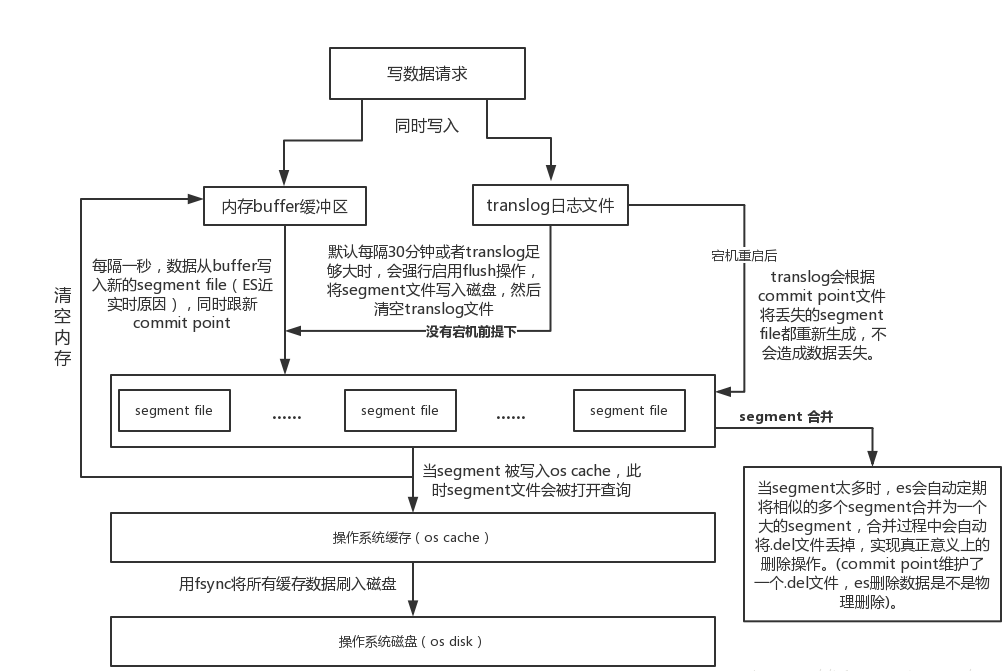
index buffer:内存缓冲区;一个node只有一块index buffer,所有shard共用。数据会在index buffer中排序、压缩index segment file:存储倒排索引的文件,每个segment本质上就是一个倒排索引,每秒都会生成一个segment文件,当文件过多时es会自动进行segment merge(合并文件),合并时会同时将已经标注删除的文档物理删除commit point:记录当前所有可用的segment(已经被fsync以后的数据,不包括在page cache的部分),每个commit point都会维护一个.del文件(es删除数据本质是不属于物理删除),当es做删改操作时首先会在.del文件中声明某个document已经被删除,文件内记录了在某个segment内某个文档已经被删除,当查询请求过来时在segment中被删除的文件是能够查出来的,但是当返回结果时会根据commit point维护的那个.del文件把已经删除的文档过滤掉(真正落磁盘的可能有多份数据,这个记录那个被删掉了)translog:为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会在每次写入数据的同时写到translog日志中(图中会有详解)。shard级别,一个translog对应一个shardfsync:translog会每隔5s或者在一个变更请求完成之后执行一次fsync操作,将translog从缓存刷入磁盘,这个操作比较耗时,如果对数据一致性要求不是很高时建议将索引改为异步,如果节点宕机时会有5s的数据丢失refresh:es接收数据请求时先存入内存中,默认每隔一秒会从内存buffer中将数据写入page cache,这个过程叫做refreshflush:es默认每隔30分钟会将page cache中的数据刷入磁盘同时清空translog日志文件,这个过程叫做flush
# ES 写流程
# ES Scripting
# 1. 使用script执行更新操作
POST product2/_update/4
{
"script": {
"source": "ctx._source.price-=1"
}
}
#可以简写
POST product2/_update/4
{
"script": "ctx._source.price-=1"
}
# 2. 使用script执行脚本命令
POST product2/_update/3
{
"script": {
"lang": "painless",
"source": "ctx._source.tags.add('无线充电')"
}
}
#传参
POST product2/_update/3
{
"script": {
"lang": "painless",
"source": "ctx._source.tags.add(params.tag_name)",
"params": {
"tag_name": "无线充电"
}
}
}
# 3. 使用script执行删除操作
# delete
POST product2/_update/15
{
"script": {
"lang": "painless",
"source": "ctx.op='delete'"
}
}
# 4. 使用script执行插入更新操作
# upsert smartison update insert
#如果数据存在,执行partial update操作,如果数据不存在,那么执行create操作
GET /product2/_doc/15
POST product2/_update/15
{
"script": {
"source": "ctx._source.price += params.param1",
"lang": "painless",
"params": {
"param1": 100
}
},
"upsert": {
"name": "小米10",
"price": 1999
}
}
# 5. 使用script执行 _bulk 操作
# 错误的实例,需要改写成下面的语句
POST _bulk
{
"update":{
"_index":"product2",
"_id":"15",
"retry_on_conflict":3
}
}
{
"script": {
"source": "ctx._source.price += params.param1",
"lang": "painless",
"params": {
"param1": 100
}
},
"upsert": {
"name": "小米10",
"price": 1999
}
}
#改成_bulk批量操作呢
POST _bulk
{ "update" : { "_id" : "0", "_index" : "product2", "retry_on_conflict" : 3} }
{ "script" : { "source": "ctx._source.price += params.param1", "lang" : "painless", "params" : {"param1" : 100}}, "upsert" : {"price" : 1999}}
# 6. script的其他语言支持
- GET查询 除了
painless(默认) ES还支持: Groovy:ES1.4.X——ES5.0expression:每个文档的开销较低:表达式的作用更多,可以非常快速地执行,甚至比编写native脚本还要快,支持javascript语法的子集:单个表达式。缺点:只能访问数字,布尔值,日期和geo_point字段,存储的字段不可用mustache:提供模板参数化查询javaPainless:Painless是一种专门用于Elasticsearch的简单,用于内联和存储脚本,类似于Java,也有注释、关键字、类型、变量、函数等,安全的脚本语言。它是Elasticsearch的默认脚本语言,可以安全地用于内联和存储脚本
#这些语言应用场景更窄,但是可能性能更好
GET product2/_search
{
"script_fields": {
"test_field": {
"script": {
"lang": "expression",
"source": "doc['price']"
}
}
}
}
GET product2/_search
{
"script_fields": {
"test_field": {
"script": {
"lang": "painless",
"source": "doc['price'].value"
}
}
}
}
# 7. script脚本语言性能比较
- Elasticsearch首次执行脚本时,将对其进行编译并将编译后的版本存储在缓存中。编译过程比较消耗性能。
- 如果需要将变量传递到脚本中,则应以命名形式传递变量,
params而不是将值硬编码到脚本本身中。例如,如果您希望能够将字段值乘以不同的乘数,请不要将乘数硬编码到脚本中
#看took消耗
GET product2/_search
{
"script_fields": {
"test_field": {
"script": {
"lang": "expression",
"source": "doc['price'] * 9"
}
}
}
}
GET product2/_search
{
"script_fields": {
"test_field": {
"script": {
"lang": "painless",
"source": "doc['price'].value * 9"
}
}
}
}
#更换num的值 对比took消耗
GET product2/_search
{
"script_fields": {
"test_field": {
"script": {
"lang": "expression",
"source": "doc['price'] * num",
"params": {
"num": 6
}
}
}
}
}
#doc['price'] * num只编译一次而doc['price'] * 9 会随着数字改变而一直编译,ES默认每分钟支持15次编译
# 8. script多脚本支持
#例如 打8折价格
GET product2/_search
{
"script_fields": {
"discount_price": {
"script": {
"lang": "painless",
"source": "doc['price'].value * params.discount",
"params": {
"discount": 0.8
}
}
}
}
}
# 原始价格 和 多个打折价格
GET product2/_search
{
"script_fields": {
"price": {
"script": {
"lang": "painless",
"source": "doc['price'].value"
}
},
"discount_price": {
"script": {
"lang": "painless",
"source": "[doc['price'].value * params.discount_8,doc['price'].value * params.discount_7,doc['price'].value * params.discount_6,doc['price'].value * params.discount_5]",
"params": {
"discount_8": 0.8,
"discount_7": 0.7,
"discount_6": 0.6,
"discount_5": 0.5
}
}
}
}
}
GET product2/_search
{
"script_fields": {
"discount_price": {
"script": {
"lang": "painless",
"source": "doc.price.value * params.discount",
"params": {
"discount": 0.8
}
}
}
}
}
# 那么遇到复杂脚本,写很多行怎么办呢
POST product2/_update/1
{
"script": {
"lang": "painless",
"source": """
ctx._source.name += params.name;
ctx._source.price -= 1
""",
"params": {
"name": "无线充电",
"price": "1"
}
}
}
# 9. Stored scripts:script模板
- 可以理解为
script模板,缓存在集群的cache中,作用域为整个集群 - 默认缓存大小是
100MB,可以通过script.cache.max_size设置缓存大小 - 没有过期时间,可以通过
script.cache.expire设置过期时间 - 脚本最大
64MB,可以通过script.max_size_in_bytes设置脚本大小;有发生变更时会重新编译
这里的post需要使用doc获取属性,因为这个最值是给get方法使用的
# 格式
# /_scripts/{id} 类似存储过程 计算折扣 作用域为整个集群
# 增加 script 模板
POST _scripts/calculate-discount
{
"script": {
"lang": "painless",
"source": "doc['price'].value * params.discount"
}
}
# 查看 script 模板
GET _scripts/calculate-discount
# 删除 script 模板
DELETE _scripts/calculate-discount
# 使用 script 模板
GET product2/_search
{
"script_fields": {
"discount_price": {
"script": {
"id":"calculate-discount",
"params": {
"discount": 0.8
}
}
}
}
}
# 10. Dates:日期的使用
ZonedDateTime类型,因此它们支持诸如之类的方法getYear,getDayOfWeek或例如从1970年开始到该时间的毫秒数getMillis。要在脚本中使用它们,请省略get前缀并首字母小写的驼峰标识。
- getMonth()
- getDayOfMonth()
- getDayOfWeek()
- getDayOfYear()
- getHour()
- getMinute()
- getSecond()
- getNano()
# 时间类型的使用
GET product2/_search/1
{
"script_fields": {
"test_year": {
"script": {
"source": "doc.createtime.value.year"
}
}
}
}
# 11. script正则表达式的支持
需要先启用配置:`script.painless.regex.enabled: true;会影响查询性能
POST product2/_update/1
{
"script": {
"lang": "painless",
"source": """
if (ctx._source.name =~ /[\s\S]*phone[\s\S]*/) {
ctx._source.name += "***|";
} else {
ctx.op = "noop";
}
"""
}
}
#[0-9]{4}-[0-9]{2}-[0-9]{2}匹配出来的不一定是日期 比如 9999-99-99 但是日期一定能匹配上
POST product2/_update/1
{
"script": {
"lang": "painless",
"source": """
if (ctx._source.createtime ==~ /[0-9]{4}-[0-9]{2}-[0-9]{2}/) {
ctx._source.name += "|***";
} else {
ctx.op = "noop";
}
"""
}
}
# 12. 使用script进行聚合查询
#统计所有小于1000商品tag的 数量 不考虑去重
GET /product/_search
GET /product/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"price": {
"lt": 1000
}
}
}
]
}
},
"aggs": {
"tag_agg_group": {
"sum": {
"script": {
"lang": "painless",
"source": """
int total = 0;
for (int i = 0; i < doc['tags.keyword'].length; i++) {
total++;
}
return total;
"""
}
}
}
},
"size": 0
}
# 13. script关于上下文件对象
doc['field'].value和params['_source']['field']:理解之间的区别是很重要的,doc['field'].value和params['_source']['field']。首先,使用doc关键字,将导致该字段的条件被加载到内存(缓存),这将导致更快的执行,但更多的内存消耗。此外,doc[...]符号只允许简单类型(不能返回一个复杂类型(JSON对象或者nested类型)),只有在非分析或单个词条的基础上有意义。但是,doc如果可能,使用仍然是从文档访问值的推荐方式,因为_source每次使用时都必须加载并解析。使用_source非常缓慢
在 post 的请求当中, 使用
ctx._source.<field-name>获取属性的值在 get 的请求当中,使用
doc['<field-name>']获取属性的值在 expression 语言中使用
doc['<field-name>']获取属性的值在 painless 语言中使用
doc['<field-name>'].value获取属性的值在 painless 语言中,当数组中有对象时,使用
params['_source']['field-name']获取属性的值doc['field-name'].value => params['_source']['field-name']
# 分词器
# 作用
- 分词
normalization(提升recall召回率:能搜索到的结果比率)
# 分析器
# 1. character filter(mapping)
分词之前预处理:过滤无用字符、标签等,转换一些&=>and,《Elasticsearch》=> Elasticsearch
HTML Strip Character Filter (opens new window):
html_strip;- 参数:
escaped_tags需要保留的html标签
# character filter # HTML Strip Character Filter PUT my_index { "settings": { "analysis": { "char_filter": { "my_char_filter": { "type": "html_strip", "escaped_tags": ["a"] } }, "analyzer": { "my_analyzer": { "tokenizer": "keyword", "char_filter": ["my_char_filter"] } } } } } POST my_index/_analyze { "analyzer": "my_analyzer", "text": "<p>I'm so <a>happy</a>!</p>" }- 参数:
Mapping Character Filter (opens new window):type mapping
# Mapping Character Filter PUT my_index2 { "settings": { "analysis": { "char_filter": { "my_char_filter": { "type": "mapping", "mappings": [ "٠ => 0", "١ => 1", "٢ => 2", "٣ => 3", "٤ => 4", "٥ => 5", "٦ => 6", "٧ => 7", "٨ => 8", "٩ => 9" ] } }, "analyzer": { "my_analyzer": { "tokenizer": "keyword", "char_filter": [ "my_char_filter" ] } } } } } POST my_index2/_analyze { "analyzer": "my_analyzer", "text": "My license plate is ٢٥٠١٥" }Pattern Replace Character Filter (opens new window):type pattern_replace
# Pattern Replace Character Filter PUT my_index3 { "settings": { "analysis": { "char_filter": { "my_char_filter": { "type": "pattern_replace", "pattern": "(\\d+)-(?=\\d)", "replacement": "$1_" } }, "analyzer": { "my_analyzer": { "tokenizer": "standard", "char_filter": ["my_char_filter"] } } } } } POST my_index3/_analyze { "analyzer": "my_analyzer", "text": "123-456-789" }
# 2. tokenizer(分词器)
GET _analyze
{
"tokenizer" : "standard",
"filter" : ["lowercase"],
"text" : "THE Quick FoX JUMPs"
}
GET /_analyze
{
"tokenizer": "standard",
"filter": [
{
"type": "condition",
"filter": [ "lowercase" ],
"script": {
"source": "token.getTerm().length() < 5"
}
}
],
"text": "THE QUICK BROWN FOX"
}
# 3. token filter
停用词、时态转换、大小写转换、同义词转换、语气词处理等。比如:has => have him => he apples => apple the / oh / a=>干掉
PUT /my_index4
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"type":"standard",
"stopwords":"_english_"
}
}
}
}
}
# 使用自定义analysis
GET my_index4/_analyze
{
"analyzer": "my_analyzer",
"text": "Teacher Ma is in the restroom"
}
# 使用系统自带analysis
GET my_index4/_analyze
{
"tokenizer": "standard",
"filter":["lowercase"],
"text": "Teacher Ma is in the restroom"
}
# ES 内置分词器(7.6有15种自带分词器)
standard analyzer:默认分词器,中文支持的不理想,会逐字拆分max_token_length:最大令牌长度。如果看到令牌超过此长度,则将其max_token_length间隔分割。默认为255
- Pattern Tokenizer (opens new window):以正则匹配分隔符,把文本拆分成若干词项
- Simple Pattern Tokenizer (opens new window):以正则匹配词项,速度比Pattern Tokenizer (opens new window)快
whitespace analyzer:以空白符分隔Tim_cookie
# 自定义分析器
tokenizer:内置或自定义分词器。(需要)char_filter:内置或自定义字符过滤器 (opens new window)filter:内置或自定义token filterposition_increment_gap:在为文本值数组建立索引时,Elasticsearch在一个值的最后一项和下一个值的第一项之间插入一个假的“空白”,以确保词组查询与来自不同数组元素的两项不匹配。默认为100。查看position_increment_gap (opens new window)更多。
# 自定义 analysis
# 设置type为custom告诉Elasticsearch我们正在定义一个定制分析器。将此与配置内置分析器的方式进行比较: type将设置为内置分析器的名称,如 standard或simple
PUT /test_analysis
{
"settings": {
"analysis": {
"char_filter": {
"test_char_filter": {
"type": "mapping",
"mappings": [
"& => and",
"| => or"
]
}
},
"filter": {
"test_stopwords": {
"type": "stop",
"stopwords": ["is","in","at","the","a","for"]
}
},
"tokenizer": {
"punctuation": {
"type": "pattern",
"pattern": "[ .,!?]"
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"html_strip",
"test_char_filter"
],
"tokenizer": "standard",
"filter": ["lowercase","test_stopwords"]
}
}
}
}
}
GET /test_analysis/_analyze
{
"text": "Teacher ma & zhang also thinks [mother's friends] is good | nice!!!",
"analyzer": "my_analyzer"
}
# 中文分词器
IK分词:ES的安装目录 不要有中文和空格- 下载:https://github.com/medcl/elasticsearch-analysis-ik
- 创建插件文件夹
cd your-es-root/plugins/ && mkdir ik - 将插件解压缩到文件夹
your-es-root/plugins/ik - 重新启动
es
两种
analyzerik_max_word:细粒度ik_smart:粗粒度
GET _analyze { "analyzer": "ik_smart", "text" : "我爱中华人民共和国" } GET _analyze { "analyzer": "ik_max_word", "text" : "我爱中华人民共和国" } GET _analyze { "analyzer": "standard", "text" : "我爱中华人民共和国" }IK文件描述IKAnalyzer.cfg.xml:IK分词配置文件- 主词库:
main.dic - 英文停用词:
stopword.dic,不会建立在倒排索引中 - 特殊词库:
quantifier.dic:特殊词库:计量单位等suffix.dic:特殊词库:后缀名surname.dic:特殊词库:百家姓preposition:特殊词库:语气词
- 自定义词库:比如当下流行词:857、emmm...、渣女、舔屏、996
- 热更新
- 修改
ik分词器源码(最好是通过扩展的方式,不要硬改源码) - 基于
ik分词器原生支持的热更新方案,部署一个web服务器,提供一个http接口,通过modified和tag两个http响应头,来提供词语的热更新