# IO
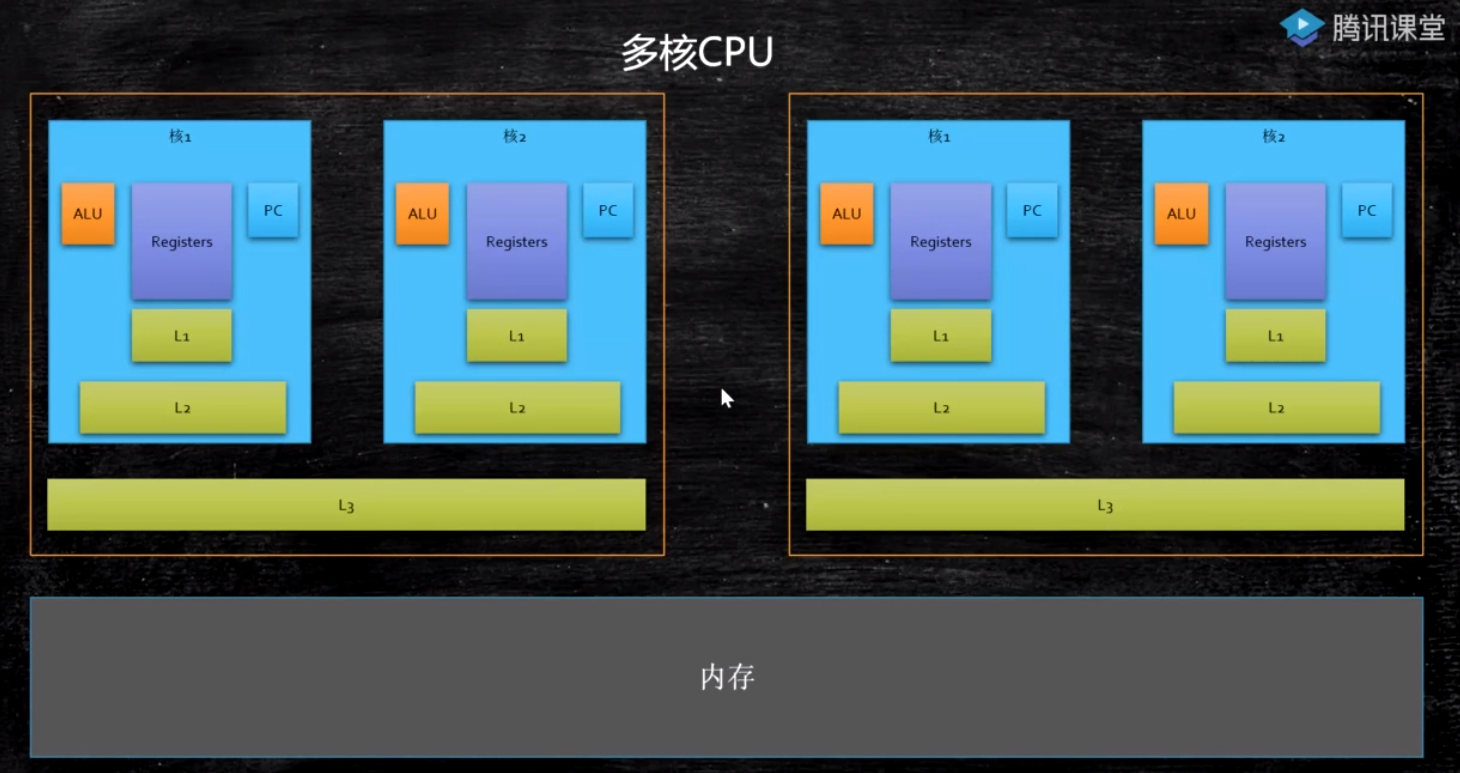
# CPU多级缓存
# CPU读取数据速率

CPU : 内存 = 100 : 1
内存 : 磁盘 = 100,000 : 1
# 按块读取
程序局部性原理,可以提高效率,充分发挥总线CPU针脚等一次性读取更多数据的能力
# CPU读取文件的过程
CPU给DMA发送指令,让磁盘把数据装到内存的某个位置(硬盘和内存直接打交道)。DMA直接内存访问。
# 缓存行对齐
一致性协议:https://www.cnblogs.com/z00377750/p/9180644.html (opens new window)
CPU内部数据同步机制:按缓存行为单位进行数据同步的
缓存行:
缓存行越大,局部性空间效率越高,但读取时间慢 缓存行越小,局部性空间效率越低,但读取时间快 取一个折中值,目前多用:64字节
// 缓存行没有对齐
public class T03_CacheLinePadding {
public static volatile long[] arr = new long[2];
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[0] = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[1] = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
// 缓存行对齐了
// 一个long类型占用8个字节,一个缓存行占用64个字节,故声明一个长度为16的long类型的数组,只有两个值有用
public class T04_CacheLinePadding {
public static volatile long[] arr = new long[16];
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[0] = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[8] = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
**缓存行对齐:**对于有些特别敏感的数字,会存在线程高竞争的访问,为了保证不发生伪共享,可以使用缓存航对齐的编程方式
对于有些特别敏感的数字,会存在线程高竞争的访问,为了保证不发生伪共享,可以使用缓存航对齐的编程方式。
JDK7中,很多采用long padding提高效率
JDK8,加入了@Contended注解(实验)需要加上:JVM -XX:-RestrictContended
# Page Cache(4k,页缓存)
# 处理逻辑
当page cache达到系统配置最大值时,会触发脏的page cache写磁盘,当写完磁盘之后,脏的状态会被清掉。
当新的page cache分配不下的时候(分配的内存不够的时候),会淘汰一些不是脏的page cache
**脏的 page cache:**创建,删除,修改都会标记为脏(只要修改过就是脏的)
# 淘汰策略
只会淘汰不是脏的
page cache
LRU
LFU
# 配置参数解读
# Socket I/O
# 常用命令
netstat -natp
jps
lsof -p jps的进程id号(查看进程的详细信息)
tcpdump -nn -i eth0 port 9090(tcp抓包)
# TCP
# 概念
TCP是一个面向连接的,可靠的传输协议,需要三次握手,之后在内核级开辟资源(客户端和服务端都会开辟资源)
# Socket
内核级的四元组:服务的的ip,服务端的端口,客户端的ip,客户端的端口
即便不进行连接的建立和数据的接收,也会开辟资源
# BIO
这一阶段,内核是阻塞的,连接在内核层面被阻塞,应用程序一次只能拿到一个连接,只能一个一个进行处理(只有开启多线程,才能同时处理多个连接)
特点:
- accept是阻塞的,如果不开启线程去处理请求的话,第二个连接就进不来,就会造成进程的阻塞
- 为了解决这个问题,所以每一个客户端连接都会开启一个线程
存在的问题:
- 线程过多,就意味着CPU频繁的切换
- 线程都有自己独立的堆空间,会造成内存的大量浪费
# NIO
# 第一阶段
这一阶段,内核不是阻塞的了,可以把多个连接一起传给应用程序,应用程序拿着连接进行遍历(也可以开启多线程进行遍历),最终还是有多少个连接,就请求了多少次内核(不管连接是否有读写请求)。有多少个连接,用户空间就要和内核空间交互多少次。
特点:
- 内核发展,进程不用阻塞,可以循环遍历去处理每一个客户端的连接
存在的问题:
- 如果有一万个客户端同时连接,那么就需要进行O(n)次系统调用
- 如果此时只有2个客户端发来数据了,那么就会造成大量的系统调用
# 第二阶段
这一阶段,内核产生了多路复用,应用程序把n个连接传给内核,内核主动轮询遍历,找到哪些连接有读写请求,然后把有读写请求的连接返给应用程序。
select:主动轮训的多路复用,给用户程序返回可读可写的状态
特点:
新增加一个系统调用,内核把可用的文件描述符返回给用户程序
如果有一万个客户端建立了连接(并不是所有客户端都在发送数据),用户程序(API)把一万个客户端的文件描述符一起发给内核,内核会返给用户程序,哪些可读,哪些可写,然后用户程序再进行下一步的处理。
每循环一次的时间复杂度O(1)的select,O(n)的 recvform,会比原来性能好很多。
存在的问题:
- 调用的时候,会传递1万个文件描述,传递的数据很多。如果一个客户端多次发送数据,会产生重复传递/拷贝(每一次文件描述符的传递都会在用户空间和内核控件进行传递,很浪费性能)
- 内核主动遍历,需要自己O(n)次遍历,找到可用的文件描述符,增加内核的资源消耗
# 第三阶段
这一阶段,内核可以开辟一块共享的存储空间(内核和应用程序都可以进行访问),用户把所有的连接放进该共享空间的红黑树结构中,当有读写请求过来以后,会产生中断,然后内核去红黑树结构中找到匹配的连接,放进链表结构中,应用程序只需要从链表结构中拿到有读写请求的连接即可。
epoll:基于事件的多路复用
用户程序通过多路复用器,获知了哪些可以操作,然后自己去操作(同步)
特点:
- 增加 epoll_create 系统调用,用来创建mmap(用户程序和内核共享的内存空间:一块供内核访问,数据结构是红黑树;一块供用户程序访问,数据结构是链表)
- 增加 epoll_ctl(add,del)系统调用,存放客户端连接的文件描述,这个数据结构是红黑树
- 当有网络请求过来之后,内核会把红黑树里面的数据放到链表里面,内核就不用再遍历了
- 增加 epoll_wait 系统调用,用来接收链表返回的结果(因为还是有等待,也就是所谓的轮训接收,所以还是同步(zookeeper只要把监听事件注册上了,就不用管了,什么时候触发,由别人决定,这是异步)
- 客户端连接的文件描述符当有数据发送和接收的时候,是怎么从1号内存空间转移到2号内存空间的?:通过网卡芯片的中断信号,会触发 callback,然后cpu就会从别的进程切换过来,发现数据到达了,就通过epoll的监听事件把文件描述符转移到2号内存空间,不需要遍历。
- epoll_wait 可以是阻塞的,也可以是非阻塞的,
- redis 是非阻塞的:单进程单线程(需要做的事很多:本身的工作线程,LRU内存回收,RDB数据落地、AOF日志落地),所以不可能让 epoll_wait 处于阻塞状态。
- nginx是阻塞的:有守护进程有,工作进程,为了降低轮训带来的性能压力,故使用阻塞方式
redis 启动的时候,先调用 epoll_create 创建一块内存空间5,
其次 redis 还需要调用 socket 也会得到一个文件描述符7,并把这个文件描述符7设置为非阻塞放进5的红黑树里面,
然后 redis 一直在不停的循环遍历 epoll_wait 获取链表中的数据
如果有客户端想要进来,就要和7号(socket)建立连接,7号就会把该连接放进链表里,等待 redis 轮训 epoll_wait 获得返回结果,当 redis 从链表中拿到客户端想要连接后,调用 accept 进行接收会获得一个连接的文件描述符8,并设置成非阻塞然后调用 epoll_ctl 把8放进5的红黑树里面。此时 epoll_wait 的轮训:即有想要连接的请求,也有要发送数据的请求。
当有连接或者数据进来的时候,经过网卡,会产生中断信号,此时cpu就会把7或者8放到链表里(也就是触发了事件),由用户程序 epoll_wait 去循环接收,然后处理。
# ByteBuffer
public void testBuffer() throws Exception {
RandomAccessFile accessFile = new RandomAccessFile("D:\\test1.txt","rw");
accessFile.write("hello world\nhello mashibing\ngood idea".getBytes());
//在指定文件偏移量的位置添加ooxx,原来的数据被替换
accessFile.seek(3);
accessFile.write("ooxx".getBytes());
//在堆上分配空间(在java进程里面,受Xmx配置的影响)
ByteBuffer.allocate(4096);
//在堆外分配空间(在java进程里面)
ByteBuffer.allocateDirect(4096);
FileChannel fileChannel = accessFile.getChannel();
// 在堆外的MMAP上分配(在java进程外面)(只有文件才可以分配这样的区域)
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 13, 4096);
// 会直接落到文件:从给指定偏移的位置开始添加,会替换要添加数据的长度的位置
// 1、如果要添加的数据长度超过了4096,就会报java.nio.BufferOverflowException
// 2、如果小于4096且大于原文件从偏移位置到文件末尾的长度,则会替换从偏移位置开始到文件末尾的所有数据,并从偏移位置开始占有4096个字节
// 3、如果小于4096且小于源文件从偏移位置到文件末尾的长度,则会替换从偏移位置开始,到数据长度的位置结束,后面的不会替换,但是从偏移位置开始仍然占有4096个字节
mappedByteBuffer.put("xxx".getBytes());
}
# MMAP
一种内存映射文件的方法
java把class load到内存其位置实际是在jvm的堆空间。堆空间存放一些object,data等。
内核获取进程外的东西,非常方便;但是要想获取java堆空间的数据,需要先经过jvm,中间多了一层逻辑转换。
java也有堆外空间(使用 unsafe 进行访问),堆外空间只能存储 byte,不需要jvm翻译,比堆内更快
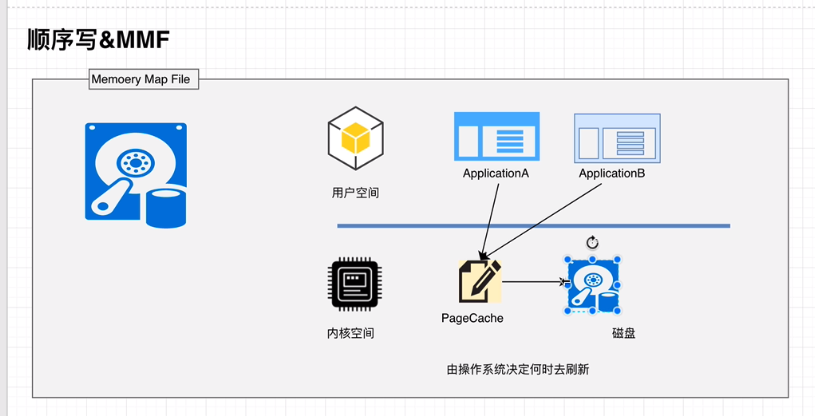
堆外开辟空间,让它和内核共享一块内存,可以使用 mmap来划分,多线程可以同时访问这块区域,同时可以映射到磁盘的文件。使用 mapbuffer(磁盘buffer) 的 put,之后就直接到文件了。
RandomAccesseFile(filepath).map(4096) => mapbuffer.put
kafka:数据从网卡进来,经过内核达到 kafka(recive),增加头部,然后通过mmap直接映射到文件,充分利用磁盘的顺序读写(会形成很多断文件),当缓存中满了,就falsh到磁盘。
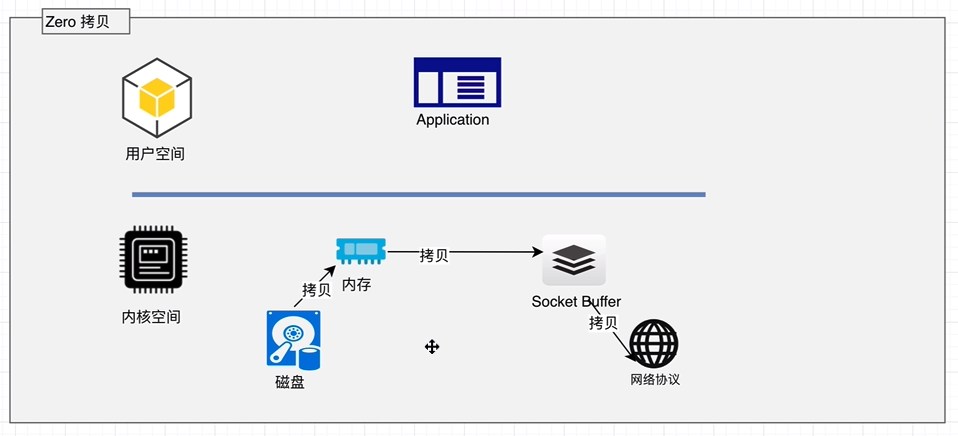
内核有一个 sendfile 的系统调用,可以由用户程序直接调用该系统调用(一般由是由框架封装的API),读取文件的时候,就不需要在经过一个用户空间的拷贝,故称零拷贝。
# 顺序写入、MMAP
Memory Mapped Files(后面简称mmap)也称为内存映射文件,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page实现文件到物理内存的直接映射。完成MMP映射后,用户对内存的所有操作会被操作系统自动的刷新到磁盘上,极大地降低了IO使用率。
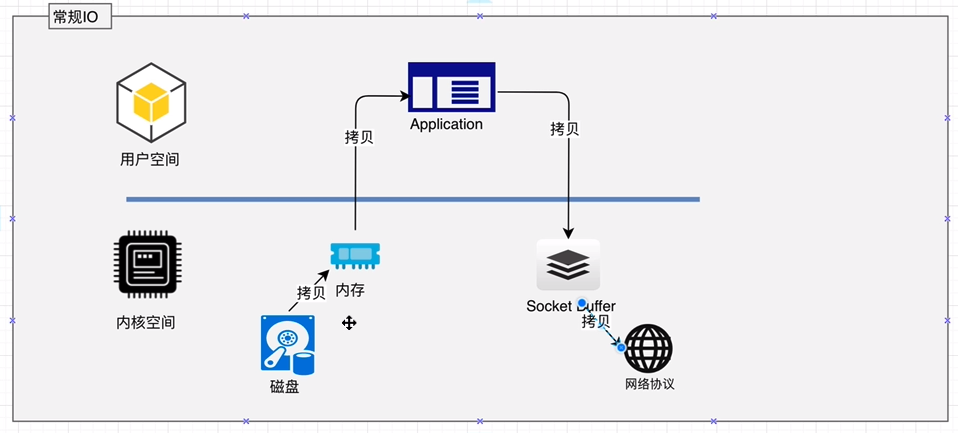
# Zero拷贝
ZeroCopy技术,直接将磁盘无需拷贝到用户空间,而是直接将数据通过内核空间传递输出,数据并没有抵达用户空间。
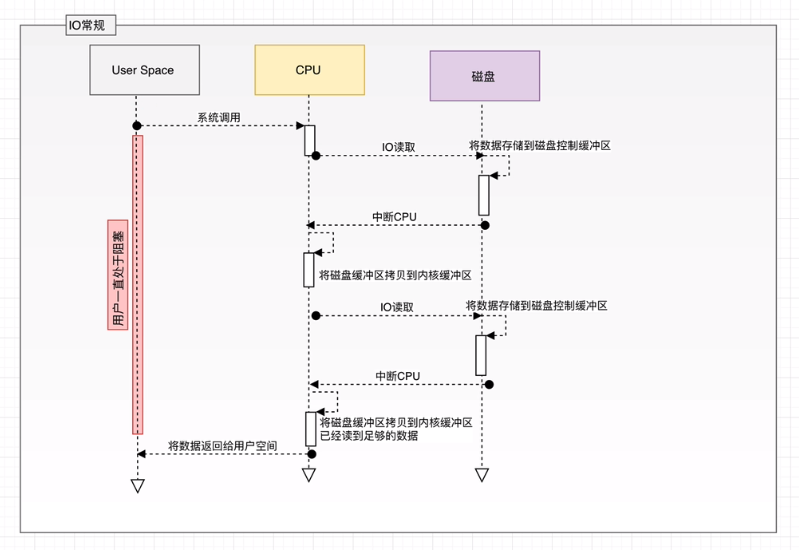
传统IO操作
用户进程调用read等系统调用向操作系统发出IO请求,请求读取数据到自己的内存缓冲区中。自己进入阻塞状态。
操作系统收到请求后,进一步将IO请求发送磁盘。
磁盘驱动器收到内核的IO请求,把数据从磁盘读取到驱动器的缓冲中。此时不占用CPU。当驱动器的缓冲区被读满后,向内核发起中断信号告知自己缓冲区已满。
内核收到中断,使用CPU时间将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。
如果内核缓冲区的数据少于用户申请的读的数据,重复步骤3跟步骤4,直到内核缓冲区的数据足够多为止。
将数据从内核缓冲区拷贝到用户缓冲区,同时从系统调用中返回。完成任务
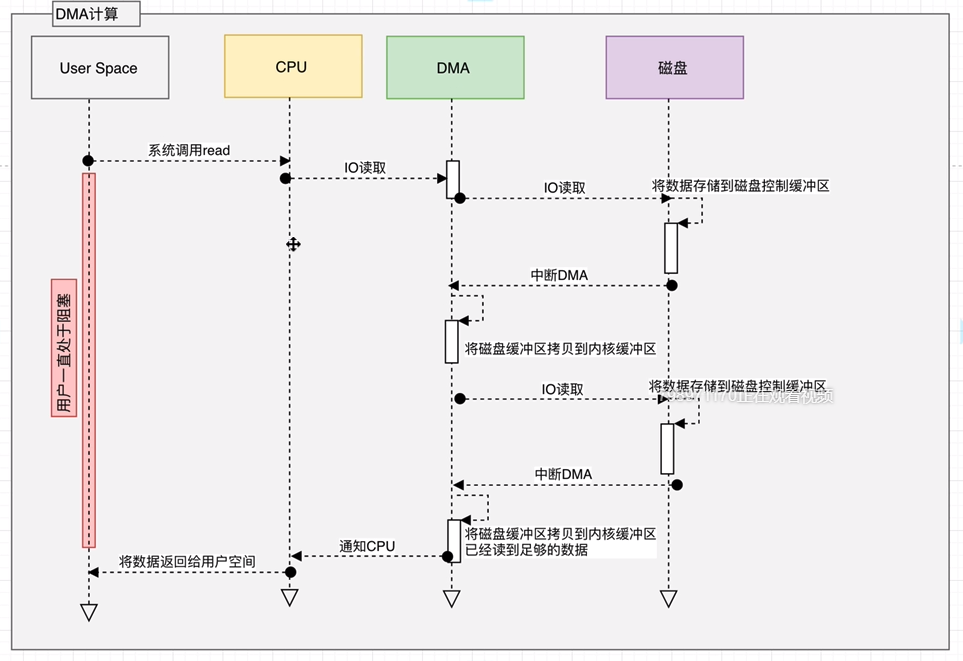
DMA读取
用户进程调用read等系统调用向操作系统发出IO请求,请求读取数据到自己的内存缓冲区中。自己进入阻塞状态。
操作系统收到请求后,进一步将IO请求发送DMA。然后让CPU干别的活去。
DMA进一步将IO请求发送给磁盘。
磁盘驱动器收到DMA的IO请求,把数据从磁盘读取到驱动器的缓冲中。当驱动器的缓冲区被读满后,向DMA发起中断信号告知自己缓冲区已满。
DMA收到磁盘驱动器的信号,将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。此时不占用CPU。这个时候只要内核缓冲区的数据少于用户申请的读的数据,内核就会一直重复步骤3跟步骤4,直到内核缓冲区的数据足够多为止。
当DMA读取了足够多的数据,就会发送中断信号给CPU。
CPU收到DMA的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回。