# JUC
# 一、线程相关
# 线程启动的几种方式
# 1. 继承 Thread
class TestThread extends Thread {
@Override
public void run() {
System.out.println("继承 Thread 方式的线程开始执行......");
}
}
new TestThread().start();
# 2. 实现 Runnable 接口
class TestRunnable implements Runnable {
@Override
public void run() {
System.out.println("实现 Runnable 接口的线程开始执行......");
}
}
new Thread(new TestRunnable()).start();
# 3. 使用 Lambda 表达式
new Thread(()->{System.out.println("使用 lambda 方式的线程开始执行......");}).start();
# 4. 使用线程池启动
Executors.newCachedThreadPool().submit(()->{System.out.println("使用 线程池 方式的线程开始执行......");});
# 线程的基本方法
# 1. Thread.sleep(1000)
使当前正在运行的线程以指定的毫秒数暂停一段时间,也就是暂时停止执行,进入阻塞状态,不会释放CPU资源。
- 在指定时间内让当前正在执行的线程暂停执行,但不会释放“锁标志”,在指定时间内不会执行
- sleep()方法给其他线程运行机会时不考虑线程的优先级
# 2. Thread.yield();
使当前正在运行线程由执行状态,进入就绪状态(进入一个等待队列中),释放CPU资源,在下一次CPU进行调度的时候,此线程有可能被执行,也有可能没有被执行。
- yield()只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行
- 调用yield方法并不会让线程进入阻塞状态,而是让线程重回就绪状态
- yield()方法只会给相同优先级或更高优先级的线程有执行的机会
# 3. 线程对象.join();
当前线程进入阻塞状态,等待调用 join 的线程对象所执行的线程执行完成之后,当前线程才会继续执行。
# 线程的状态
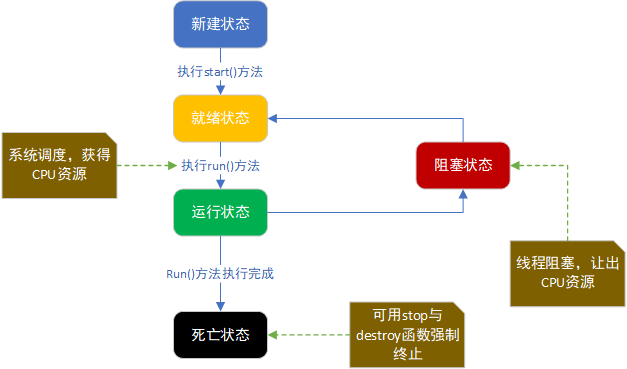
# 1. 新建状态
使用 new 关键字和 Thread 类或其子类建立一个线程对象后,该线程对象就处于新建状态。它保持这个状态直到程序 start() 这个线程。
# 2. 就绪状态
当线程对象调用了start()方法之后,该线程就进入就绪状态。就绪状态的线程处于就绪队列中,要等待JVM里线程调度器的调度。
# 3. 运行状态
如果就绪状态的线程获取 CPU 资源,就可以执行 run(),此时线程便处于运行状态。处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
# 4. 阻塞状态
如果一个线程执行了sleep(睡眠)、suspend(挂起)等方法,失去所占用资源之后,该线程就从运行状态进入阻塞状态。在睡眠时间已到或获得设备资源后可以重新进入就绪状态。可以分为三种:
- 等待阻塞:运行状态中的线程执行 wait() 方法,使线程进入到等待阻塞状态。
- 同步阻塞:线程在获取 synchronized 同步锁失败(因为同步锁被其他线程占用)。
- 其他阻塞:通过调用线程的 sleep() 或 join() 发出了 I/O请求时,线程就会进入到阻塞状态。当sleep() 状态超时,join() 等待线程终止或超时,或者 I/O 处理完毕,线程重新转入就绪状态。
# 5. 死亡状态
一个运行状态的线程完成任务或者其他终止条件发生时,该线程就切换到终止状态。
# 线程的挂起
线程的挂起操作实质上就是使线程进入“非可执行”状态下,在这个状态下CPU不会分给线程时间片,进入这个状态可以用来暂停一个线程的运行;在线程挂起后,可以通过重新唤醒线程来使之恢复运行。当一个线程进入“非可执行”状态,即挂起状态时,必然存在某种原因使其不能继续运行,这些原因可能是如下几种情况:
# 1. sleep():不推荐使用
通过调用sleep()方法使线程进入休眠状态,线程在指定时间内不会运行,当时间到了之后,依然会继续运行。
这里必须说明一下的是sleep方法,虽然它也能将线程挂起,但是它会产生
InterruptedException异常,当sleep一定时间后它将会自动执行后面的方法,也可以通过interrupt方法进行主动打断sleep方法进行线程唤醒。
# 2. join:不推荐使用
通过调用join()方法使线程挂起,如果某个线程在另一个线程t上调用t.join(),这个线程将被挂起,直到线程t执行完毕为止。(线程的继续运行不受人为控制)
# 3. suspend()与resume()方法:已被废弃
thread.suspend():线程被挂起;thread.resume():挂起的线程继续执行;线程 thread 在运行到suspend()之后被强制挂起,暂停运行,直到主线程调用 thread.resume() 方法时才被重新唤醒。
Java2中已经废弃了suspend()和resume()方法,因为使用这两个方法可能会产生死锁,所以应该使用同步对象调用wait()和notify()的机制来代替suspend()和resume()进行线程控制
# 4. wait():推荐使用
这个是Java中常用的线程挂起方法,当调用wait方法的时候线程会自动的释放掉占有的线程资源锁,然后通过notify或notifyAll方法进行wait方法的唤醒,因此在这个地方不会出现死锁。
# 5. park/unpark:推荐使用
park的字面量意思是指停车场的意思,使用park来挂起线程后需要调用unpark来进行唤醒,这个没有先后顺序的区分,如果你提前进行了unpark,然后在进行park也是可以的,但是提前了的多个unpark只能看做是一个unpark,不能进行重复叠加,如果再次park的话需要新的unpark来进行唤醒操作,这个比如你在停车场进行停车操作,你如果提前进行了预约停车,你在未进入停车场之前都是可以进行多次预约的,这所有的预约只扣一次钱(unpark),但是这所有的预约操作都看作是你这一次进入停车场停车(park)的凭证,如果你离开了通过缴费凭证(unpark)一旦你想进行下一次停车,那么已经使用过的预约都不能进行作数了,你只能再次预约或者直接进入停车场,一旦要离开只能再次缴费(unpark)。
调用park/unpark使用的是LockSupport.park()/LockSupport.unpark()。
使用park/unpark的使用使用synchronized关键字也会出现死锁的情况,因为它并不释放线程所占用的锁资源,所以使用的时候也需要注意。
# 二、锁
# (1) synchronized
synchronized关键字是用来控制线程同步的,就是在多线程的环境下,控制synchronized代码段不被多个线程同时执行。锁的是对象,而不是代码
修饰的对象有以下几种:
- 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象
- 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象
- 修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象
- 修改一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象
# 1. 简单使用
// 以下两个方法要锁的对象是等效的
// 修饰方法
private synchronized void exe11(){
}
private void exe12(){
// 修改代码块
synchronized (this) {
}
}
// 以下两个静态方法要锁的对象是等效的
// 修饰静态方法
private synchronized static void exe21(){
}
private static void exe22(){
// 修改代码块
synchronized (TestSynchronized01.class) {
}
}
# 2. 锁的特点
- 既能保证原子性,又能保证可见性
- 不能保证指令重排序,所以某些场景需要结合 volatile 使用
- 在执行同步方法的时候,可以调用非同步方法
- 写加锁,读不加锁,会产生脏读。(看业务是否有严格要求,不加锁比加锁慢了100倍)
- 可重入锁:在执行同步方法的时候,可以调用其他的同步方法(两个方法的锁必须是一把锁)
- 程序中如果出现异常,一般情况下,锁将会被释放(没有进行异常的捕捉及处理时)
- 要锁的对象不能用 String 和 Integer、Long等基础数据类型
# 3. 锁升级
锁升级过程:无锁——>偏向锁——>轻量级锁(CAS)——>重量级锁
JDK早期,是重量级锁,需要找OS申请锁
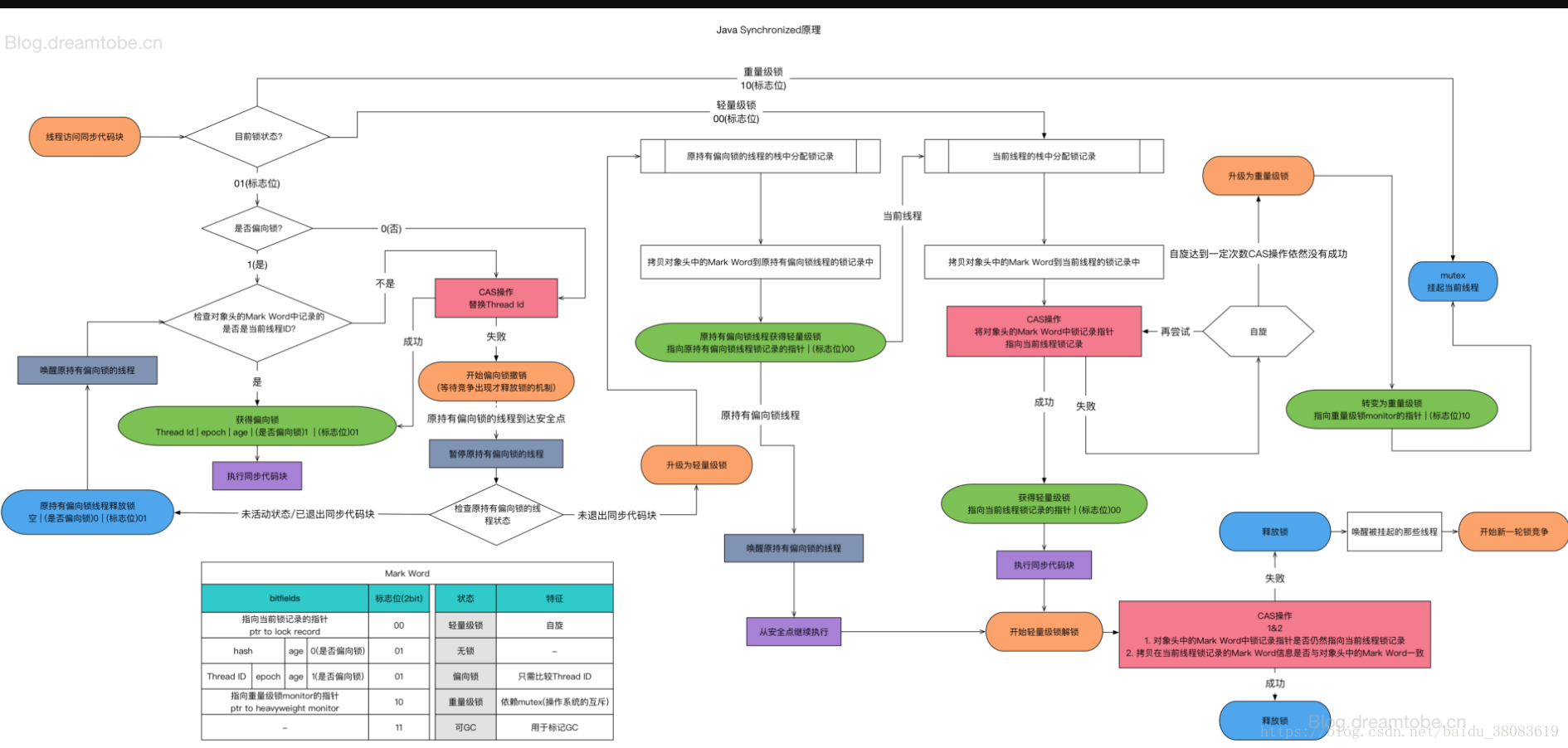
# 1. 偏向锁
大多数情况下,锁总是由同一个线程多次获得。当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,偏向锁是一个可重入的锁。如果锁对象头的Mark Word里存储着指向当前线程的偏向锁,无需重新进行CAS操作来加锁和解锁。当有其他线程尝试竞争偏向锁时,持有偏向锁的线程(不处于活动状态)才会释放锁。偏向锁无法使用自旋锁优化,因为一旦有其他线程申请锁,就破坏了偏向锁的假定进而升级为轻量级锁
# 2. 自旋锁(CAS):有时间和次数的限制
让不满足条件的线程等待一会看能不能获得锁,通过占用处理器的时间来避免线程切换带来的开销。自旋等待的时间或次数是有一个限度的,如果自旋超过了定义的时间仍然没有获取到锁,则该线程应该被挂起。在 JDK1.6 之后,引入了自适应自旋锁,自适应意味着自旋的次数不是固定不变的,而是根据前一次在同一个锁上自旋的时间以及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
# 3. 轻量级锁
减少无实际竞争情况下,使用重量级锁产生的性能消耗。JVM会现在当前线程的栈桢中创建用于存储锁记录的空间 LockRecord,将对象头中的 Mark Word 复制到 LockRecord 中并将 LockRecord 中的 Owner 指针指向锁对象。然后线程会尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针,成功则当前线程获取到锁,失败则表示其他线程竞争锁当前线程则尝试使用自旋的方式获取锁。自旋获取锁失败则锁膨胀升级为重量级锁。
# 4. 重量级锁
通过对象内部的监视器(monitor)实现,其中monitor的本质是依赖于底层操作系统的Mutex Lock实 现,操作系统实现线程之间的切换需要从用户态到内核态的切换,切换成本非常高。线程竞争不使用自旋,不会消耗CPU。但是线程会进入阻塞等待被其他线程被唤醒,响应时间缓慢。
# 5. 锁的优缺点
- 执行时间长或者线程数量多的尽量用系统锁
- 执行时间短且线程数量少的情况下,适合使用自旋锁,因为自旋为一直占用CPU
# 6. 可重入
public class SynchronizedLockTest {
synchronized void m1() {
for(int i=0; i<10; i++) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(i);
if(i == 2) m2();
}
}
synchronized void m2() {
System.out.println("m2 ...");
}
public static void main(String[] args) {
SynchronizedLockTest synchronizedLockTest = new SynchronizedLockTest();
new Thread(synchronizedLockTest::m1).start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
# (2) ReentrantLock:可重入锁
public class ReentrantLockTest {
Lock lock = new ReentrantLock();
void m1() {
try {
lock.lock();
for(int i=0; i<10; i++) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(i);
if(i == 2) m2();
}
}finally {
lock.unlock();
}
}
void m2() {
try {
lock.lock();
System.out.println("m2 ...");
}finally {
lock.unlock();
}
}
public static void main(String[] args) {
ReentrantLockTest reentrantLockTest = new ReentrantLockTest();
new Thread(reentrantLockTest::m1).start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
# 比synchronized有更好用的API
# 1. 尝试获取锁
lock.tryLock()
使用tryLock进行尝试锁定,不管锁定与否,方法都将继续执行 可以根据tryLock的返回值来判定是否锁定 也可以指定tryLock的时间,由于tryLock(time)抛出异常,所以要注意unclock的处理,必须放到finally中
# 2. 可以被打断的锁
lock.lockInterruptibly()
如果当前线程未被中断,则可以获取锁,如果已被中断则会排除 InterruptedException 异常。但是使用lock.lock()时,当前线程被中断,不会报错。打断线程的方法:线程对象.interrupt()
# 3. 可以指定为公平锁
默认为不公平锁
// 指定为公平锁
Lock lock = new ReentrantLock(true);
公平锁则在于每次都是依次从队首取值,严格按照线程启动的顺序来执行的,不允许插队。
首先判断当前AQS的state是否等于0,锁是否被占用,如果没有被占用的话,继续判断队列中是否有排在前面的线程在等待锁,没有的话就修改statte状态;然后将当前线程记录为独占锁的线程,继续判断当前线程是否为独断锁的线程,ReentrantLock是可重入的,线程可以不停地Lock来增加state的值,对应的需要unlock来解锁,减少state的值, 如果上面的条件判断失败,即获取锁失败,则将线程加入到等待线程队列队尾,然后阻塞线程,等待被唤醒。
非公平锁在等待锁的过程中, 如果有任意新的线程妄图获取锁,都是有很大的几率直接获取到锁的,允许插队。
非公平锁逻辑基本跟公平锁一致,最本质的区别是,当前的锁状态没有被占用时,当前线程可以直接占用,而不需要判断当前队列中是否有等待线程。
ReentrantLock默认使用非公平锁是基于性能考虑,公平锁为了保证线程规规矩矩地排队,需要增加阻塞和唤醒的时间开销。如果直接插队获取非公平锁,跳过了对队列的处理,速度会更快。
# (3) CountDownLatch:倒数计时器
CountDownLatch是一个计数器,线程完成一个记录一个,计数器递减,只能只用一次
是通过一个计数器来实现的,计数器的初始值是线程的数量。每当一个线程执行完毕后,计数器的值就-1,当计数器的值为0时,表示所有线程都执行完毕,然后在闭锁上等待的线程就可以恢复工作了。
public class CountDownLatchTest {
public static void main(String[] args) {
usingCountDownLatch();
}
private static void usingCountDownLatch() {
Thread[] threads = new Thread[100];
CountDownLatch latch = new CountDownLatch(threads.length);
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
int result = 0;
for (int j = 0; j < 10000; j++) result += j;
latch.countDown();
});
}
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("end latch");
}
}
# countDown()
将count值减1(原子性操作)。
# await()
调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行。
# await(long timeout, TimeUnit unit)
和await()类似,只不过等待一定的时间后count值还没变为0的话就会继续执行。
# (4) CyclicBarrier:循环栅栏
它的作用就是会让所有线程都等待完成后才会继续下一步行动。
举个例子,就像生活中我们会约朋友们到某个餐厅一起吃饭,有些朋友可能会早到,有些朋友可能会晚到,但是这个餐厅规定必须等到所有人到齐之后才会让我们进去。这里的朋友们就是各个线程,餐厅就是 CyclicBarrier。
深入理解:CyclicBarrier https://blog.csdn.net/qq_39241239/article/details/87030142 (opens new window)
public class CyclicBarrierTest {
public static void main(String[] args) {
// parties 是参与线程的个数
// Runnable 参数,这个参数的意思是最后一个到达后,线程要做的任务
CyclicBarrier barrier = new CyclicBarrier(20, () -> System.out.println("满人"));
for(int i=0; i<100; i++) {
new Thread(()->{
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
}
}
# await()
线程调用 await() 表示自己已经到达栅栏
# await(long timeout, TimeUnit unit)
和await()类似,只不过等待一定的时间后到达的线程个数少于指定的线程个数时也会继续执行。
# (5) Phaser:阶段栅栏的作用(1.7加入的)
深入理解:Phaser
public class PhaserTest {
MarriagePhaser phaser = new MarriagePhaser();
public static void main(String[] args) {
new PhaserTest().testPhaser();
}
private void testPhaser(){
phaser.bulkRegister(5);
for(int i=0; i<5; i++) {
final int nameIndex = i;
new Thread(()->{
Person p = new Person("person " + nameIndex);
p.arrive();
phaser.arriveAndAwaitAdvance();
p.eat();
phaser.arriveAndAwaitAdvance();
p.leave();
phaser.arriveAndAwaitAdvance();
}).start();
}
}
class MarriagePhaser extends Phaser {
@Override
protected boolean onAdvance(int phase, int registeredParties) {
switch (phase) {
case 0:
System.out.println("所有人到齐了!");
return false;
case 1:
System.out.println("所有人吃完了!");
return false;
case 2:
System.out.println("所有人离开了!");
System.out.println("婚礼结束!");
return true;
default:
return true;
}
}
}
class Person {
String name;
Random r = new Random();
public Person(String name) {
this.name = name;
}
public void arrive() {
milliSleep(r.nextInt(1000));
System.out.printf("%s 到达现场!\n", name);
}
public void eat() {
milliSleep(r.nextInt(1000));
System.out.printf("%s 吃完!\n", name);
}
public void leave() {
milliSleep(r.nextInt(1000));
System.out.printf("%s 离开!\n", name);
}
void milliSleep(int milli) {
try {
TimeUnit.MILLISECONDS.sleep(milli);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Phaser2Test {
MarriagePhaser phaser = new MarriagePhaser();
public static void main(String[] args) {
new Phaser2Test().testPhaser();
}
private void testPhaser(){
phaser.bulkRegister(7);
for(int i=0; i<5; i++) {
new Thread(new Person("p" + i)).start();
}
new Thread(new Person("新郎")).start();
new Thread(new Person("新娘")).start();
}
class MarriagePhaser extends Phaser {
@Override
protected boolean onAdvance(int phase, int registeredParties) {
switch (phase) {
case 0:
System.out.println("所有人到齐了!" + registeredParties);
System.out.println();
return false;
case 1:
System.out.println("所有人吃完了!" + registeredParties);
System.out.println();
return false;
case 2:
System.out.println("所有人离开了!" + registeredParties);
System.out.println();
return false;
case 3:
System.out.println("婚礼结束!新郎新娘抱抱!" + registeredParties);
return true;
default:
return true;
}
}
}
class Person implements Runnable {
String name;
Random r = new Random();
public Person(String name) {
this.name = name;
}
public void arrive() {
milliSleep(r.nextInt(1000));
System.out.printf("%s 到达现场!\n", name);
phaser.arriveAndAwaitAdvance();
}
public void eat() {
milliSleep(r.nextInt(1000));
System.out.printf("%s 吃完!\n", name);
phaser.arriveAndAwaitAdvance();
}
public void leave() {
milliSleep(r.nextInt(1000));
System.out.printf("%s 离开!\n", name);
phaser.arriveAndAwaitAdvance();
}
private void hug() {
if(name.equals("新郎") || name.equals("新娘")) {
milliSleep(r.nextInt(1000));
System.out.printf("%s 洞房!\n", name);
phaser.arriveAndAwaitAdvance();
} else {
phaser.arriveAndDeregister();
}
}
void milliSleep(int milli) {
try {
TimeUnit.MILLISECONDS.sleep(milli);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void run() {
arrive();
eat();
leave();
hug();
}
}
}
# arriveAndAwaitAdvance()
到达并等待下一个任务的开始
# arriveAndDeregister()
到达就完成,不再参与下一个任务了
# onAdvance()
在Phaser类中,在每个线程中,每个线程完成一个阶段后都会等待其他线程完成后再一起进行,当所有线程都完成了一个任务的时候,会调用Phaser的onAdvance方法。如果我们想在每个阶段,所有线程都完成他们的阶段工作后做点啥事的话,那就得继承Phaser类来重写Onadvance这个方法来实现我们的目的,
# (6) ReentrantReadWriteLock:读写锁
public class ReentrantReadWriteLockTest {
static Lock lock = new ReentrantLock();
private static int value;
static ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
static Lock readLock = readWriteLock.readLock();
static Lock writeLock = readWriteLock.writeLock();
public static void read(Lock lock) {
try {
lock.lock();
Thread.sleep(1000);
System.out.println("read over!");
//模拟读取操作
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public static void write(Lock lock, int v) {
try {
lock.lock();
Thread.sleep(1000);
value = v;
System.out.println("write over!");
//模拟写操作
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
//Runnable readR = ()-> read(lock);
Runnable readR = () -> read(readLock);
//Runnable writeR = ()->write(lock, new Random().nextInt());
Runnable writeR = () -> write(writeLock, new Random().nextInt());
for (int i = 0; i < 18; i++) new Thread(readR).start();
for (int i = 0; i < 2; i++) new Thread(writeR).start();
}
}
# 共享锁
当一个线程进行读取的时候,其他线程如果是读请求,则可以直接进行读取,如果是写锁,则需要等待所有的读请求完成之后,才允许写
# 排他锁
当一个线程进行写操作时,其他线程无论是读还是写,都将被阻塞,只有等写线程完成之后,才允许其他线程获得锁
# (7) Semaphore:信号灯(限流、收费站)
public class SemaphoreTest {
public static void main(String[] args) {
// 允许 n 个线程同时执行
// 是否公平锁,默认非公平锁
Semaphore semaphore = new Semaphore(1, true);
new Thread(()->{
try {
semaphore.acquire();
System.out.println("T1 running...");
Thread.sleep(200);
System.out.println("T1 running...");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}).start();
new Thread(()->{
try {
semaphore.acquire();
System.out.println("T2 running...");
Thread.sleep(200);
System.out.println("T2 running...");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
# semaphore.acquire();
获取执行的许可:每次执行,信号量-1,如果减到0,后面的线程将会被阻塞
# semaphore.release();
每次执行,信号量+1,加1以后,后面阻塞的线程将有机会被执行
# (8) Exchanger:两者交换
public class ExchangerTest {
public static void main(String[] args) {
Exchanger<String> exchanger = new Exchanger<>();
new Thread(()->{
String s = "T1";
try {
// 阻塞,直到另外一个线程执行了 exchange 进行交换后,会继续执行
s = exchanger.exchange(s);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " " + s);
}, "t1").start();
new Thread(()->{
String s = "T2";
try {
// 阻塞,直到另外一个线程执行了 exchange 进行交换后,会继续执行
s = exchanger.exchange(s);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " " + s);
}, "t2").start();
}
}
# exchange
阻塞,直到另外一个线程执行了 exchange 进行交换后,会继续执行
# (9) LockSupport
LockSupport是一个线程阻塞工具类,所有的方法都是静态方法,可以让线程在任意位置阻塞,当然阻塞之后肯定得有唤醒的方法。
public class LockSupportTest {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
for (int i = 0; i < 10; i++) {
System.out.println(i);
if(i == 5) {
LockSupport.park();
}
}
});
t.start();
Thread.sleep(2000);
LockSupport.unpark(t);
}
}
# LockSupport.park(Object blocker)
暂停当前线程
# LockSupport.parkNanos(Object blocker, long nanos)
暂停当前线程,不过有超时时间的限制
# LockSupport.parkUntil(Object blocker, long deadline)
暂停当前线程,直到某个时间
# LockSupport.park()
无期限暂停当前线程
# LockSupport.parkNanos(long nanos)
暂停当前线程,不过有超时时间的限制
# LockSupport.parkUntil(long deadline)
暂停当前线程,直到某个时间
# LockSupport.unpark(t)
恢复当前线程
# (10) Object.wait()、Object.notify()
- 当前线程必须拥有当前对象锁
- wait()和notify()必须在synchronized函数或synchronized代码块中进行调用
- wait()让当前线程等待,会释放锁,从而使别的线程有机会抢占该锁
- 唤醒当前对象锁的等待线程使用notify或notifyAll方法,也必须拥有相同的对象锁
- notify()不会释放锁
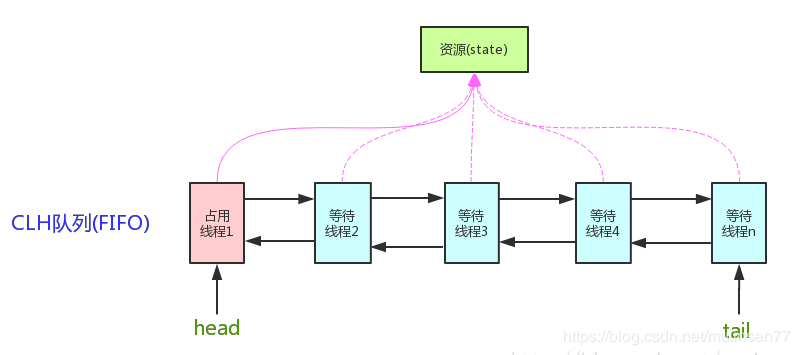
# (11) AbstractQueuedSynchronizer: AQS
AQS的核心思想是:如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并将共享资源设置为锁定状态,如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。 AQS是将每一条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node),来实现锁的分配。 用大白话来说,AQS就是基于CLH队列,用volatile修饰共享变量state,线程通过CAS去改变状态符,成功则获取锁成功,失败则进入等待队列,等待被唤醒。 AQS是自旋锁:在等待唤醒的时候,使用自旋(while(!cas()))的方式,不停地尝试获取锁,直到被其他线程获取成功。
核心数据结构:双向链表 + (volatile)state(锁状态)
底层操作:CAS
# 重要的API
# 1. isHeldExclusively()
该线程是否正在独占资源。只有用到condition才需要去实现它。
# 2. tryAcquire(int)
独占方式。尝试获取资源,成功则返回true,失败则返回false。
# 3. tryRelease(int)
独占方式。尝试释放资源,成功则返回true,失败则返回false。
# 4. tryAcquireShared(int)
共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
# 5. tryReleaseShared(int)
共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。
# 6. addWaiter(Node)
将当前线程加入上面锁的双向链表(等待队列)中
private Node addWaiter(Node mode) {
// 要加入的节点
Node node = new Node(Thread.currentThread(), mode);
// 一个中间变量指向最后一个节点
Node pred = tail;
if (pred != null) {
// 当前节点的前一个节点指向中间变量(也就是最后一个节点)
node.prev = pred;
// CAS操作
if (compareAndSetTail(pred, node)) {
// 中间变量的下一个节点指向当前节点(加入队列成功)
pred.next = node;
return node;
}
}
enq(node);
return node;
}
# 7. acquireQueued(Node, int)
通过自旋,判断当前队列节点是否可以获取锁。
// 公平锁的获取
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
// 死循环,每个节点都有机会执行下面的逻辑
for (;;) {
// 获取当前节点的前一个节点
final Node p = node.predecessor();
// 前一个节点是头节点,并且已经获取到锁的时候
if (p == head && tryAcquire(arg)) {
// 把当前节点设置为头结点
setHead(node);
// 设置为空,help GC
p.next = null;
failed = false;
return interrupted;
}
// 进入阻塞状态,进行等待
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
# 8. VarHandle:变量句柄
VarHandle 的出现替代了java.util.concurrent.atomic和sun.misc.Unsafe的部分操作。并且提供了一系列标准的内存屏障操作,用于更加细粒度的控制内存排序。在安全性、可用性、性能上都要优于现有的API。
int STATE = MethodHandles.lookup().findVarHandle(Class, "state", int.class);
- JKD9发布的新特性
- 可以对普通属性做一些原子性操作
- 比反射快,直接操作二进制码
# 实现了AQS的锁有
- 自旋锁
- 互斥锁
- 读锁写锁
- 条件产量
- 信号量
- 栅栏
# 三、volatile
用来确保将变量的更新操作通知到其他线程。当把变量声明为 volatile 类型后,编译器与运行时都会注意到这个变量是共享的,因此不会将该变量上的操作与其他内存操作一起重排序。volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取volatile类型的变量时总会返回最新写入的值。
# 1. Java内存模型
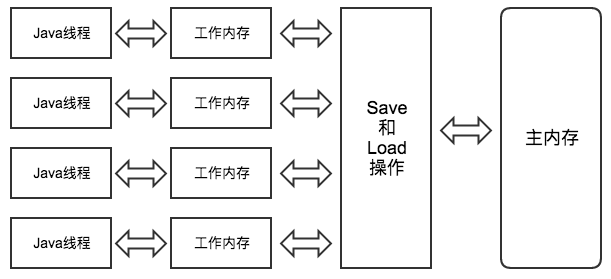
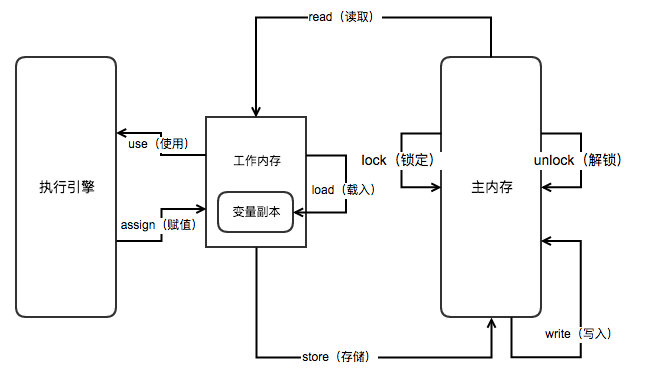
# 2. 内存间的交互动作
| 动作 | 作用 |
|---|---|
| lock(锁定) | 作用于主内存变量,把一个变量标示为一条线程独占的状态 |
| unlock(解锁) | 作用于主内存的变量,把一个处于锁定状态的变量释放出来, 释放后的变量才可以被其他线程锁定 |
| read(读取) | 作用于主内存的变量,把一个变量的值从主内存传输到线程的工作内存中, 以便随后的load动作使用 |
| load(载入) | 作用于工作内存的变量,把read操作从主存中得到的变量值放入工作内存的变量副本中 |
| use(使用) | 作用于工作内存的变量,把工作内存中一个变量的值传递给执行引擎, 每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作 |
| assign(赋值) | 作用于工作内存的变量,把一个从执行引擎接收到的值赋给工作内存中的变量, 每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作 |
| store(存储) | 作用于工作内存的变量,把工作内存中一个变量的值传送到主内存中, 以便随后的write操作使用 |
| write(写入) | 作用于主内存的变量,把store操作从工作内存中得到的变量的值放入主内存的变量中 |
# 3. volatile 的特点
在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此volatile变量是一种比sychronized关键字更轻量级的同步机制。
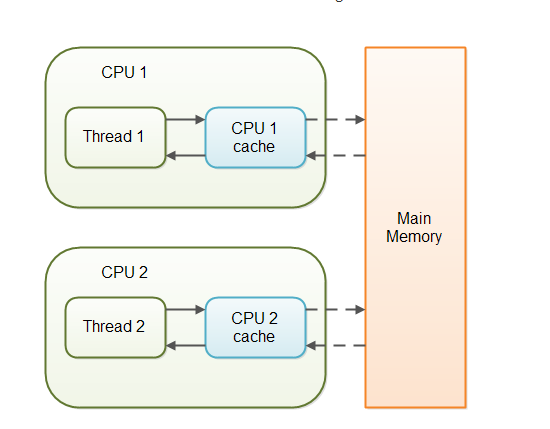
当对非 volatile 变量进行读写的时候,每个线程先从内存拷贝变量到CPU缓存中。如果计算机有多个CPU,每个线程可能在不同的CPU上被处理,这意味着每个线程可以拷贝到不同的 CPU cache 中。而声明变量是 volatile 的,JVM 保证了每次读变量都从内存中读,跳过 CPU cache 这一步。
# 1. 保证线程可见性
当一个线程修改了这个变量的值,volatile 保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。但普通变量做不到这点,普通变量的值在线程间传递均需要通过主内存来完成。
# 2. 禁止指令重排序
在虚拟机层面,为了尽可能减少内存操作速度远慢于CPU运行速度所带来的CPU空置的影响,虚拟机会按照自己的一些规则(这规则后面再叙述)将程序编写顺序打乱——即写在后面的代码在时间顺序上可能会先执行,而写在前面的代码会后执行——以尽可能充分地利用CPU。
在硬件层面,CPU会将接收到的一批指令按照其规则重排序,同样是基于CPU速度比缓存速度快的原因,和上一点的目的类似,只是硬件处理的话,每次只能在接收到的有限指令范围内重排序,而虚拟机可以在更大层面、更多指令范围内重排序。
new 一个对象的指令会分成三步
- 给这个对象申请内存,此时对象的成员变量是一个默认值
- 给对象的成员变量初始化
- 把这块内存赋值给外部变量
# 内存屏障
# 1. LoadLoad屏障
对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
# 2. StoreStore屏障
对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
# 3. LoadStore屏障
对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
# 4. StoreLoad屏障
对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
# 3. 不能保证原子性
以i++为例,其包括读取、操作、赋值三个操作,下面是两个线程的操作顺序
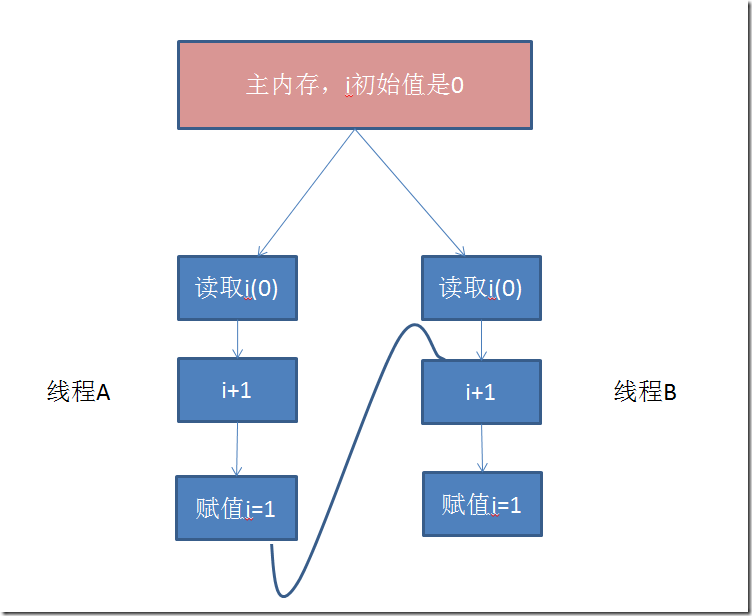
假如说线程A在做了i+1,但未赋值的时候,线程B就开始读取i,那么当线程A赋值i=1,并回写到主内存,而此时线程B已经不再需要i的值了,而是直接交给处理器去做+1的操作,于是当线程B执行完并回写到主内存,i的值仍然是1,而不是预期的2。也就是说,volatile缩短了普通变量在不同线程之间执行的时间差,但仍然存有漏洞,依然不能保证原子性。
# 4. 缓存一致性协议:MESI
# 四、CAS:无锁优化、自旋锁、乐观锁
CAS操作是CPU原语的支持,中间的指令不会被打断
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。 如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。
使用 Unsafe 进行CAS操作。
Unsafe.getUnsafe().compareAndSwapInt();
Unsafe.getUnsafe().compareAndSwapLong();
Unsafe.getUnsafe().compareAndSwapObject();
Unsafe 可直接操作JVM中的内存
# 1. CAS存在的问题
# 1. ABA问题
因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A。
从Java1.5开始JDK的atomic包里提供了一个类 AtomicStampedReference 来解决ABA问题。这个类的compareAndSet 方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
如果是基础数据类型,无所谓,影响不大
如果是引用类型,就需要注意里面的属性是否已经发生了变化
# 2. 循环时间长开销大
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
# 3. 只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
# 2. 使用CAS操作的 JDK 内部类
- AtomicInteger
- AtomicLong
- AtomicBoolean
# 3. LongAdder
LongAdder在高并发的场景下会比它的前辈——AtomicLong 具有更好的性能,代价是消耗更多的内存空间。
在并发量较低的环境下,线程冲突的概率比较小,自旋的次数不会很多。但是,高并发环境下,N个线程同时进行自旋操作,会出现大量失败并不断自旋的情况,此时AtomicLong的自旋会成为瓶颈。
LongAdder的基本思路就是分散热点,将value值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。(分段锁)
这种做法有没有似曾相识的感觉?没错,ConcurrentHashMap 中的“分段锁”其实就是类似的思路。
# 五、两个线程之间等待输出
# 1. LockSupport方式
public class Demo1 {
private Thread t1 = null;
private Thread t2 = null;
public static void main(String[] args) {
Demo1 demo = new Demo1();
demo.execute();
}
private void execute() {
t1 = new Thread(() -> {
for (int i = 0; i < 10; i++) {
System.out.println(i);
ThreadSleepUtil.sleepSeconds(1);
if (i == 5) {
LockSupport.unpark(t2);
LockSupport.park();
}
}
});
t2 = new Thread(() -> {
LockSupport.park();
System.out.println("............");
LockSupport.unpark(t1);
});
t1.start();
t2.start();
}
}
# 2. CountDownLatch的方式
public class Demo2 {
private Thread t1 = null;
private Thread t2 = null;
private CountDownLatch countDownLatch1 = new CountDownLatch(1);
private CountDownLatch countDownLatch2 = new CountDownLatch(1);
public static void main(String[] args) {
Demo2 demo = new Demo2();
demo.execute();
}
private void execute() {
t1 = new Thread(() -> {
for (int i = 0; i < 10; i++) {
System.out.println(i);
ThreadSleepUtil.sleepSeconds(1);
if (i == 5) {
countDownLatch1.countDown();
try {
countDownLatch2.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t2 = new Thread(() -> {
try {
countDownLatch1.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("............");
countDownLatch2.countDown();
});
t1.start();
t2.start();
}
}
# 3. Object.wait()、Object.notify()方式
public class Demo3 {
private Thread t1 = null;
private Thread t2 = null;
private Object o1 = new Object();
public static void main(String[] args) {
Demo3 demo = new Demo3();
demo.execute();
}
private void execute() {
t1 = new Thread(() -> {
for (int i = 0; i < 10; i++) {
System.out.println(i);
ThreadSleepUtil.sleepSeconds(1);
if (i == 5) {
synchronized (o1) {
try {
o1.notify();
o1.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
});
t2 = new Thread(() -> {
synchronized (o1) {
try {
o1.wait();
System.out.println("............");
o1.notify();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
t2.start();
}
}
# 4. Semaphore方式
public class Demo4 {
private Thread t1 = null;
private Thread t2 = null;
private Semaphore semaphore = new Semaphore(1);
public static void main(String[] args) {
Demo4 demo = new Demo4();
demo.execute();
}
private void execute() {
t1 = new Thread(() -> {
try {
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < 6; i++) {
System.out.println(i);
ThreadSleepUtil.sleepSeconds(1);
}
semaphore.release();
try {
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 6; i < 10; i++) {
System.out.println(i);
ThreadSleepUtil.sleepSeconds(1);
}
semaphore.release();
});
t2 = new Thread(() -> {
try {
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("............");
semaphore.release();
});
t1.start();
t2.start();
}
}
# 六、生产者消费者问题
写一个固定容量同步容器,拥有get和put方法,以及getCount方法,能够支持2个生产者和10个消费者线程的阻塞调用
# 1. ReentrantLock.newCondition方式
public class Demo8 {
final private LinkedList<String> lists = new LinkedList<>();
//最多10个元素
final private int MAX = 10;
private Lock lock = new ReentrantLock();
private Condition producer = lock.newCondition();
private Condition consumer = lock.newCondition();
public static void main(String[] args) {
Demo8 c = new Demo8();
//启动消费者线程
for (int i = 0; i < 10; i++) {
new Thread(() -> {
while (true) {
c.get();
}
}, "c" + i).start();
}
//启动生产者线程
for (int i = 0; i < 2; i++) {
new Thread(() -> {
while (true) {
c.put(Thread.currentThread().getName());
}
}, "p" + i).start();
}
}
public void put(String str) {
try {
lock.lock();
//想想为什么用while而不是用if?
while (lists.size() == MAX) {
producer.await();
}
lists.add(str);
System.out.println("生产者生产完成后剩余:" + lists.size());
ThreadSleepUtil.sleepMilliSeconds(300);
consumer.signalAll(); //通知消费者线程进行消费
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void get() {
try {
lock.lock();
while (lists.size() == 0) {
consumer.await();
}
lists.removeFirst();
System.out.println("消费者消费完成后剩余:" + lists.size());
ThreadSleepUtil.sleepSeconds(1);
producer.signalAll(); //通知生产者进行生产
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
# 七、强软弱虚引用
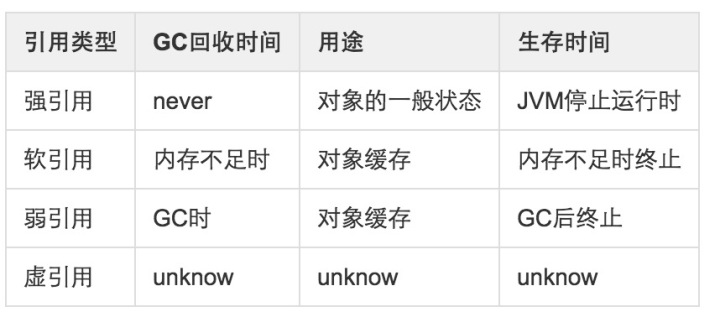
# 1. 概述
JDK1.2之后,Java对引用的概念进行了扩充,分为强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)、虚引用(Phantom Reference)4中,这4种引用强度逐渐减弱。
# 2. 强引用
强引用虽然在开发过程中并不怎么提及,但是无处不在。平时我们编程的时候例如:Object object=new Object();那object就是一个强引用了。当内存空 间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
public class ObjectTest {
public static void main(String[] args) throws IOException {
M m = new M();
m = null;
System.gc(); //DisableExplicitGC
System.in.read();
}
}
对GC知识比较熟悉的可以知道,HotSpot JVM目前的垃圾回收算法一般默认是可达性算法,即在每一轮GC的时候,选定一些对象作为GC ROOT,然后以它们为根发散遍历,遍历完成之后,如果一个对象不被任何GC ROOT引用,那么它就是不可达对象,则在接下来的GC过程中很可能会被回收。
强引用最重要的就是它能够让引用变得强(Strong),这就决定了它和垃圾回收器的交互。具体来说,如果一个对象通过一串强引用链接可到达(Strongly reachable),它是不会被回收的。如果你不想让你正在使用的对象被回收,这就正是你所需要的。
# 3. 软引用:SoftReference
如果一个对象只具有软引用,如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
// 启动参数增加堆内存的大小限制
public class SoftReferenceTest {
public static void main(String[] args) {
SoftReference<byte[]> m = new SoftReference<>(new byte[1024 * 1024 * 10]);
//m = null;
System.out.println(m.get());
System.gc();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(m.get());
//再分配一个数组,heap将装不下,这时候系统会垃圾回收,先回收一次,如果不够,会把软引用干掉
byte[] b = new byte[1024 * 1024 * 15];
System.out.println(m.get());
}
}
软引用是用来描述一些还有用但是并非必须的对象。对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收返回之后进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常
# 4. 弱引用:WeakReference
弱引用与软引用的区别在于:弱引用的对象拥有更短暂的生命周期。在垃圾回收器进行线程扫描的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
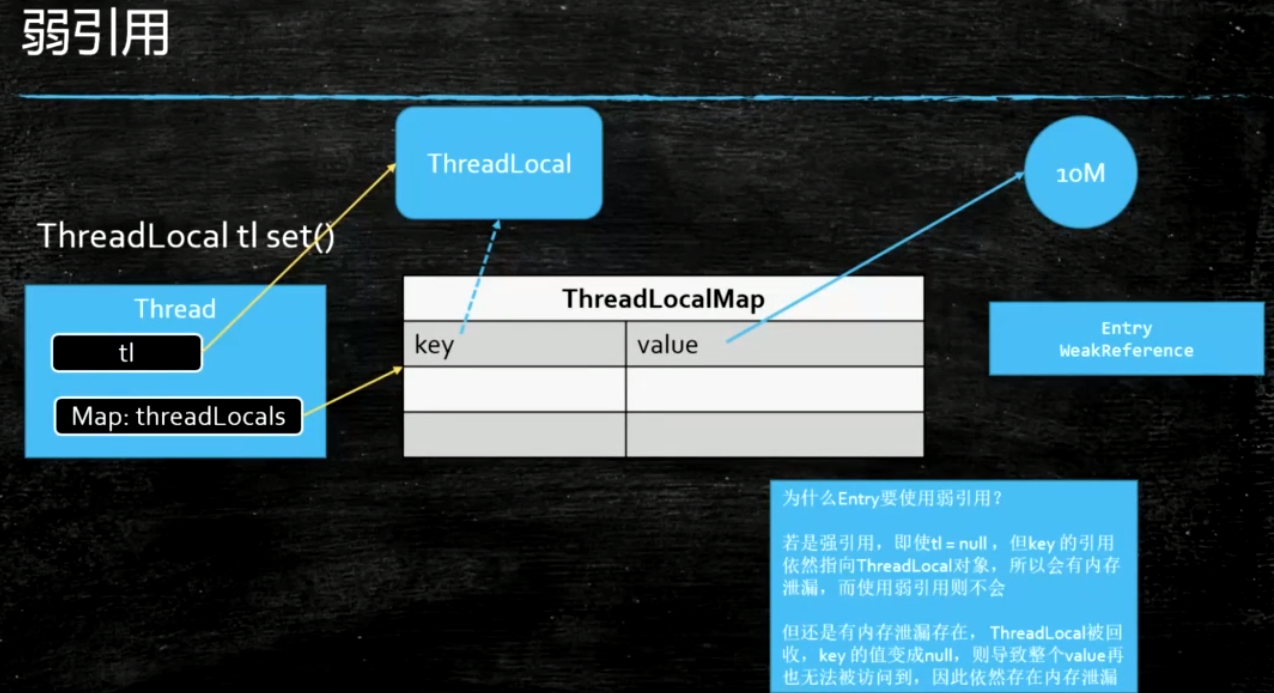
ThreadLocal使用了弱引用
public class WeakReferenceTest {
public static void main(String[] args) {
WeakReference<M> m = new WeakReference<>(new M());
System.out.println(m.get());
System.gc();
System.out.println(m.get());
ThreadLocal<M> tl = new ThreadLocal<>();
tl.set(new M());
tl.remove();
}
}
# 5. 虚引用:PhantomReference
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。 虚引用主要用来跟踪对象被垃圾回收的活动。虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
一般用来管理堆外内存
public class PhantomReferenceTest {
private static final List<Object> LIST = new LinkedList<>();
private static final ReferenceQueue<M> QUEUE = new ReferenceQueue<>();
public static void main(String[] args) {
PhantomReference<M> phantomReference = new PhantomReference<>(new M(), QUEUE);
new Thread(() -> {
while (true) {
LIST.add(new byte[1024 * 1024]);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
System.out.println(phantomReference.get());
}
}).start();
new Thread(() -> {
while (true) {
Reference<? extends M> poll = QUEUE.poll();
if (poll != null) {
System.out.println("--- 虚引用对象被jvm回收了 ---- " + poll);
}
}
}).start();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
虚引用也成为幽灵引用或者幻影引用,它是最弱的一种引用关系。一个瑞祥是否有虚引用的存在,完全不会对其生存时间造成影响,也无法通过虚引用来取得一个对象的实例。为一个对象设置虚引用关联的唯一目的就是在这个对象被GC时收到一个系统通知。
# 八、ThreadLocal
ThreadLocal叫做线程变量,意思是ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的。ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。
# 1. 应用示例
public class ThreadLocalTest {
public static void main(String[] args) {
new ThreadLocalTest().testThreadLocal();
}
private void testThreadLocal(){
ThreadLocal<Person> tl = new ThreadLocal<>();
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(tl.get());
}).start();
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
tl.set(new Person());
}).start();
}
class Person {
String name = "zhangsan";
}
}
# 2. 私有变量存储在哪里
# 1. ThreadLocal存储数据的容器
在代码中,我们使用ThreadLocal实例提供的set/get方法来存储/使用value,但ThreadLocal实例其实只是一个引用,真正存储值的是一个Map,其key实ThreadLocal实例本身,value是我们设置的值,分布在堆区。这个Map的类型是ThreadL.ThreadLocalMap(ThreadLocalMap是ThreadLocal的内部类),其key的类型是ThreadLocal,value是Object,类定义如下:
static class ThreadLocalMap {
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
// 继承了软引用,说明Entry是一个软引用,垃圾回收一旦触发,就会回收这块内存
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
}
那么当我们重写init或者调用set/get的时候,内部的逻辑是怎样的呢,按照上面的说法,应该是将value存储到了ThreadLocalMap中,或者从已有的ThreadLocalMap中获取value,我们来通过代码分析一下。
# 2. ThreadLocal.set(T value)
set的逻辑比较简单,就是获取当前线程的ThreadLocalMap,然后往map里添加KV,K是this,也就是当前ThreadLocal实例,V是我们传入的value。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
其内部实现首先需要获取关联的Map,我们看下getMap和createMap的实现
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
可以看到,getMap就是返回了当前Thread实例的map(t.threadLocals),create也是创建了Thread的map(t.threadLocals),也就是说对于一个Thread实例,ThreadLocalMap是其内部的一个属性,在需要的时候,可以通过ThreadLocal创建或者获取,然后存放相应的值。我们看下Thread类的关键代码:
public class Thread implements Runnable {
ThreadLocal.ThreadLocalMap threadLocals = null;
}
可以看到,Thread中定义了属性threadLocals,但其初始化和使用的过程,都是通过ThreadLocal这个类来执行的。
# 3. ThreadLocal.get()
get是获取当前线程的对应的私有变量,是我们之前set或者通过initialValue指定的变量,其代码如下
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
// 这是一个软引用,垃圾回收一旦触发,就会回收这块内存
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
可以看到,其逻辑也比较简单清晰:
- 获取当前线程的ThreadLocalMap实例
- 如果不为空,以当前ThreadLocal实例为key获取value
- 如果ThreadLocalMap为空或者根据当前ThreadLocal实例获取的value为空,则执行setInitialValue()
setInitialValue()内部如下:
- 调用我们重写的initialValue得到一个value
- 将value放入到当前线程对应的ThreadLocalMap中
- 如果map为空,先实例化一个map,然后赋值KV
# 4. 关键设计小结
代码分析到这里,其实对于ThreadLocal的内部主要设计以及其和Thread的关系比较清楚了:
- 每个线程,是一个Thread实例,其内部拥有一个名为threadLocals的实例成员,其类型是ThreadLocal.ThreadLocalMap
- 通过实例化ThreadLocal实例,我们可以对当前运行的线程设置一些线程私有的变量,通过调用ThreadLocal的set和get方法存取
- ThreadLocal本身并不是一个容器,我们存取的value实际上存储在ThreadLocalMap中,ThreadLocal只是作为TheadLocalMap的key
- 每个线程实例都对应一个TheadLocalMap实例,我们可以在同一个线程里实例化很多个ThreadLocal来存储很多种类型的值,这些ThreadLocal实例分别作为key,对应各自的value
- 当调用ThreadLocal的set/get进行赋值/取值操作时,首先获取当前线程的ThreadLocalMap实例,然后就像操作一个普通的map一样,进行put和get
当然,这个ThreadLocalMap并不是一个普通的Map(比如常用的HashMap),而是一个特殊的,key为弱引用的map。
# 3. ThreadLocal 内存模型
通过上一节的分析,其实我们已经很清楚ThreadLocal的相关设计了,对数据存储的具体分布也会有个比较清晰的概念。下面的图是网上找来的常见到的示意图,我们可以通过该图对ThreadLocal的存储有个更加直接的印象。
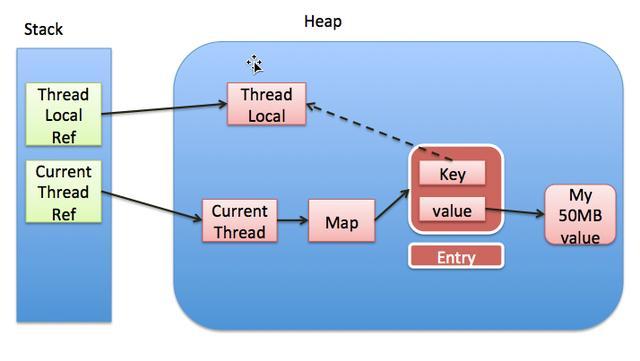
我们知道Thread运行时,线程的的一些局部变量和引用使用的内存属于Stack(栈)区,而普通的对象是存储在Heap(堆)区。根据上图,基本分析如下:
- 线程运行时,我们定义的TheadLocal对象被初始化,存储在Heap,同时线程运行的栈区保存了指向该实例的引用,也就是图中的ThreadLocalRef
- 当ThreadLocal的set/get被调用时,虚拟机会根据当前线程的引用也就是CurrentThreadRef找到其对应在堆区的实例,然后查看其对用的TheadLocalMap实例是否被创建,如果没有,则创建并初始化
- Map实例化之后,也就拿到了该ThreadLocalMap的句柄,然后如果将当前ThreadLocal对象作为key,进行存取操作
- 图中的虚线,表示key对ThreadLocal实例的引用是个弱引用
# 4. 可能的内存泄露分析
# 1. 内存泄露分析
根据上一节的内存模型图我们可以知道,由于ThreadLocalMap是以弱引用的方式引用着ThreadLocal,换句话说,就是ThreadLocal是被ThreadLocalMap以弱引用的方式关联着,因此如果ThreadLocal没有被ThreadLocalMap以外的对象引用,则在下一次GC的时候,ThreadLocal实例就会被回收,那么此时ThreadLocalMap里的一组KV的K就是null了,因此在没有额外操作的情况下,此处的V便不会被外部访问到,而且只要Thread实例一直存在,Thread实例就强引用着ThreadLocalMap,因此ThreadLocalMap就不会被回收,那么这里K为null的V就一直占用着内存。
综上,发生内存泄露的条件是:
- ThreadLocal实例没有被外部强引用,比如我们假设在提交到线程池的task中实例化的ThreadLocal对象,当task结束时,ThreadLocal的强引用也就结束了
- ThreadLocal实例被回收,但是在ThreadLocalMap中的V没有被任何清理机制有效清理
- 当前Thread实例一直存在,则会一直强引用着ThreadLocalMap,也就是说ThreadLocalMap也不会被GC
换句话说,如果Thread实例还在,但是ThreadLocal实例却不在了,则ThreadLocal实例作为key所关联的value无法被外部访问,却还被强引用着,因此出现了内存泄露。ThreadLocal如果使用的不当,是有可能引起内存泄露的,虽然触发的场景不算很容易。
这里要额外说明一下,这里说的内存泄露,是因为对其内存模型和设计不了解,且编码时不注意导致的内存管理失联,而不是有意为之的一直强引用或者频繁申请大内存。比如如果编码时不停的人为塞一些很大的对象,而且一直持有引用最终导致OOM,不能算作ThreadLocal导致的“内存泄露”,只是代码写的不当而已!
# 2. TheadLocal本身的优化
进一步分析ThreadLocalMap的代码,可以发现ThreadLocalMap内部也是做了一定的优化的
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
可以看到,在set值的时候,有一定的几率会执行replaceStaleEntry(key, value, i)方法,其作用就是将当前的值替换掉以前的key为null的值,重复利用了空间。
# 5. ThreadLocal使用建议
通过前面几节的分析,我们基本弄清楚了ThreadLocal相关设计和内存模型,对于是否会发生内存泄露做了分析,下面总结下几点建议:
- 当需要存储线程私有变量的时候,可以考虑使用ThreadLocal来实现
- 当需要实现线程安全的变量时,可以考虑使用ThreadLocal来实现
- 当需要减少线程资源竞争的时候,可以考虑使用ThreadLocal来实现
- 注意Thread实例和ThreadLocal实例的生存周期,因为他们直接关联着存储数据的生命周期
- 如果频繁的在线程中new ThreadLocal对象,在使用结束时,最好调用ThreadLocal.remove来释放其value的引用,避免在ThreadLocal被回收时value无法被访问却又占用着内存
- 在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束
- 进行事务操作,用于存储线程事务信息
- 数据库连接,Session会话管理
# 6. ThreadLocal需要注意的点
上面这张图详细的揭示了ThreadLocal和Thread以及ThreadLocalMap三者的关系。
- Thread中有一个map,就是ThreadLocalMap
- ThreadLocalMap的key是ThreadLocal,值是我们自己设定的
- ThreadLocal是一个弱引用,当为null时,会被当成垃圾回收
- 重点来了,如果ThreadLocal是null了,也就是要被垃圾回收器回收了,但是此时我们的ThreadLocalMap生命周期和Thread的一样,它不会回收,这时候就出现了一个现象。那就是ThreadLocalMap的key没了,但是value还在,这就造成了内存泄漏(永远不会被回收)。
- 解决办法:使用完ThreadLocal后,执行remove操作,避免出现内存溢出情况。
# 九、队列的接口
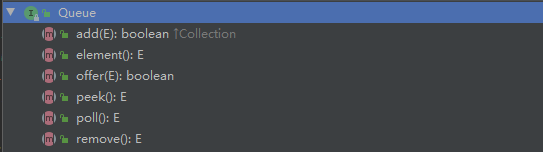
# (1). Queue:队列
# add(E)
增加一个元索;如果队列已满,则抛出一个IIIegaISlabEepeplian异常
# element()
返回队列头部的元素;如果队列为空,则抛出一个NoSuchElementException异常
# offer(E)
添加一个元素并返回true;如果队列已满,则返回false
# peek()
返回队列头部的元素;如果队列为空,则返回null
# poll()
移除并返回队列头部的元素;如果队列为空,则返回null
# remove()
移除并返回队列头部的元素;如果队列为空,则抛出一个NoSuchElementException异常
# (2). Deque:双端队列(extends Queue)
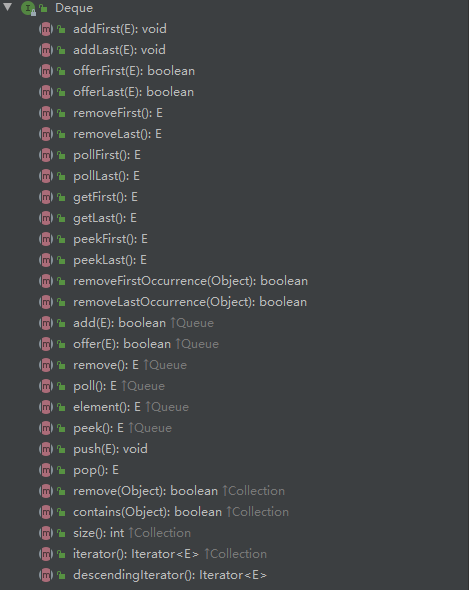
# addFirst(E)
在双端队列的前面增加一个元索;如果队列已满,则抛出一个IIIegaISlabEepeplian异常。当使用容量限制的deque时,通常最好使用方法offerFirst(E)。
# addLast(E);
在双端队列的后面增加一个元索;如果队列已满,则抛出一个IIIegaISlabEepeplian异常。当使用容量限制的deque时,通常最好使用方法offerLast(E)。
# offerFirst(E);
在双端队列的前面添加一个元素并返回true;如果队列已满,则返回false
# offerLast(E);
在双端队列的后面添加一个元素并返回true;如果队列已满,则返回false
# removeFirst()
移除并返回队列头部的元素;如果队列为空,则抛出一个NoSuchElementException异常
# removeLast()
移除并返回队列尾部的元素;如果队列为空,则抛出一个NoSuchElementException异常
# pollFirst()
移除并返回队列头部的元素;如果队列为空,则返回null
# pollLast()
移除并返回队列尾部的元素;如果队列为空,则返回null
# getFirst()
返回队列头部的元素;如果队列为空,则抛出一个NoSuchElementException异常
# getLast()
返回队列尾部的元素;如果队列为空,则抛出一个NoSuchElementException异常
# peekFirst()
返回队列头部的元素;如果队列为空,则返回null
# peekLast()
返回队列尾部的元素;如果队列为空,则返回null
# removeFirstOccurrence(Object)
删除指定元素第一次出现的位置所在的元素,删除成功返回true,否则返回false
# removeLastOccurrence(Object)
删除指定元素最后一次出现的位置所在的元素,删除成功返回true,否则返回false
# push(E)
将元素推送到此双端队列的头部;如果队列已满,则抛出一个IIIegaISlabEepeplian异常。此方法相当于addFirst(E)。
# pop()
从这个双端队列中弹出一个元素,也就是说删除并返回此双端队列的第一个元素;如果队列为空,则抛出一个NoSuchElementException异常。 此方法相当于removeFirst() 。
# (3). BlockingQueue:阻塞队列(extends Queue)
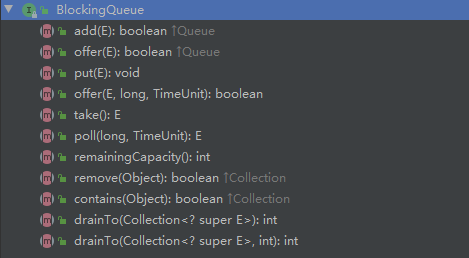
# put(E)
将指定的元素插入到此队列中,如果队列已满,则进行阻塞等待
# take()
移除并返回队列头部的元素;如果队列为空,则进行阻塞等待
# (4). BlockingDeque:阻塞的双端队列(extends BlockingQueue, Deque)
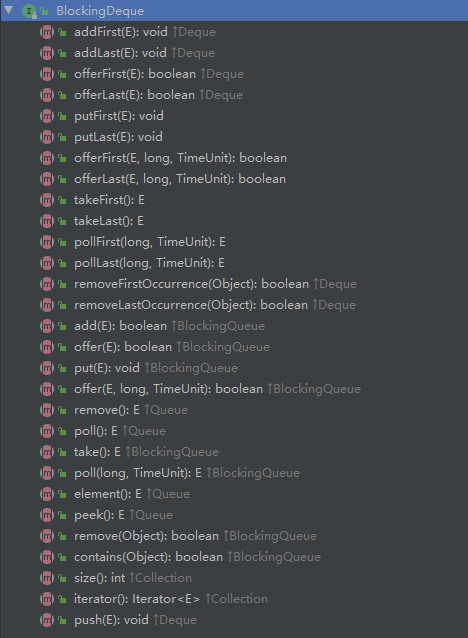
# offer(E e, long timeout, TimeUnit unit)
添加一个元素到双端队列的尾部。如果队列不满,则直接返回true;如果队列满了,在指定的时间内,队列依然是满的,则返回false,否则返回true。
# offerFirst(E e, long timeout, TimeUnit unit)
添加一个元素到双端队列的头部。如果队列不满,则直接返回true;如果队列满了,在指定的时间内,队列依然是满的,则返回false,否则返回true。
# offerLast(E e, long timeout, TimeUnit unit)
添加一个元素到双端队列的尾部。如果队列不满,则直接返回true;如果队列满了,在指定的时间内,队列依然是满的,则返回false,否则返回true。
# poll(long timeout, TimeUnit unit)
移除并返回队列头部的元素;如果队列为空,在指定的时间内,队列依然是空的,则返回null,否则返回指定的元素。
# pollFirst(long timeout, TimeUnit unit)
移除并返回队列头部的元素;如果队列为空,在指定的时间内,队列依然是空的,则返回null,否则返回指定的元素。
# pollLast(long timeout, TimeUnit unit)
移除并返回队列尾部的元素;如果队列为空,在指定的时间内,队列依然是空的,则返回null,否则返回指定的元素。
# putFirst(E e)
将指定的元素插入到此双端队列的头部,如果队列已满,则进行阻塞等待
# putLast(E e)
将指定的元素插入到此双端队列的尾部,如果队列已满,则进行阻塞等待
# takeFirst()
移除并返回队列头部的元素;如果队列为空,则进行阻塞等待
# takeLast()
移除并返回队列尾部的元素;如果队列为空,则进行阻塞等待
# (5). TransferQueue
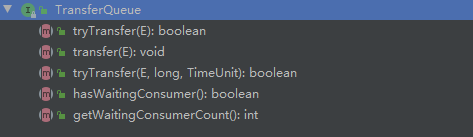
# tryTransfer(E e)
如果存在一个消费者已经等待接收它,则立即传送指定的元素,否则返回false,并且不进入队列。
# tryTransfer(E e, long timeout, TimeUnit unit)
在上述方法的基础上设置超时时间
# transfer(E e)
如果存在一个消费者已经等待接收它,则立即传送指定的元素,否则等待直到元素被消费者接收。
# hasWaitingConsumer()
如果至少有一位消费者在等待,则返回true
# getWaitingConsumerCount()
获取所有等待获取元素的消费线程数量
# 十、BlockingQueue的实现类
# (1). ArrayBlockingQueue
# 1. 概述
根据 ArrayBlockingQueue 的名字我们都可以看出,它是一个队列,并且是一个基于数组的阻塞队列。同时也是一个有界队列,有界也就意味着,它不能够存储无限多数量的对象。所以在创建 ArrayBlockingQueue 时,必须要给它指定一个队列的大小。
# 2. 使用场景
- 先进先出队列(队列头的是最先进队的元素;队列尾的是最后进队的元素)
- 有界队列(即初始化时指定的容量,就是队列最大的容量,不会出现扩容,容量满,则阻塞进队操作;容量空,则阻塞出队操作)
- 队列不支持空元素
# 3. 锁类型
单锁 + 两个condition
# (2). LinkedBlockingQueue
内部存储是基于链表的无界阻塞队列,由于使用了两个ReentrantLock来实现出入队列的线程安全,比ArrayBlockingQueue的吞吐量要高很多。
# 1. 概述
LinkedBlockingQueue不同于ArrayBlockingQueue,它如果不指定容量,默认为Integer.MAX_VALUE,也就是无界队列。所以为了避免队列过大造成机器负载或者内存爆满的情况出现,我们在使用的时候建议手动传一个队列的大小。
# 2. 源码剖析
# 1. 属性
/**
* 节点类,用于存储数据
*/
static class Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}
/** 阻塞队列的大小,默认为Integer.MAX_VALUE */
private final int capacity;
/** 当前阻塞队列中的元素个数 */
private final AtomicInteger count = new AtomicInteger();
/**
* 阻塞队列的头结点
*/
transient Node<E> head;
/**
* 阻塞队列的尾节点
*/
private transient Node<E> last;
/** 获取并移除元素时使用的锁,如take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** notEmpty条件对象,当队列没有数据时用于挂起执行删除的线程 */
private final Condition notEmpty = takeLock.newCondition();
/** 添加元素时使用的锁如 put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** notFull条件对象,当队列数据已满时用于挂起执行添加的线程 */
private final Condition notFull = putLock.newCondition();
从上面的属性我们知道,每个添加到LinkedBlockingQueue队列中的数据都将被封装成Node节点,添加的链表队列中,其中head和last分别指向队列的头结点和尾结点。与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制,也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。
这里如果不指定队列的容量大小,也就是使用默认的Integer.MAX_VALUE,如果存在添加速度大于删除速度时候,有可能会内存溢出,这点在使用前希望慎重考虑。
另外,LinkedBlockingQueue对每一个lock锁都提供了一个Condition用来挂起和唤醒其他线程。
# 2. 构造函数
public LinkedBlockingQueue() {
// 默认大小为Integer.MAX_VALUE
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
count.set(n);
} finally {
putLock.unlock();
}
}
默认的构造函数和最后一个构造函数创建的队列大小都为Integer.MAX_VALUE,只有第二个构造函数用户可以指定队列的大小。第二个构造函数最后初始化了last和head节点,让它们都指向了一个元素为null的节点。
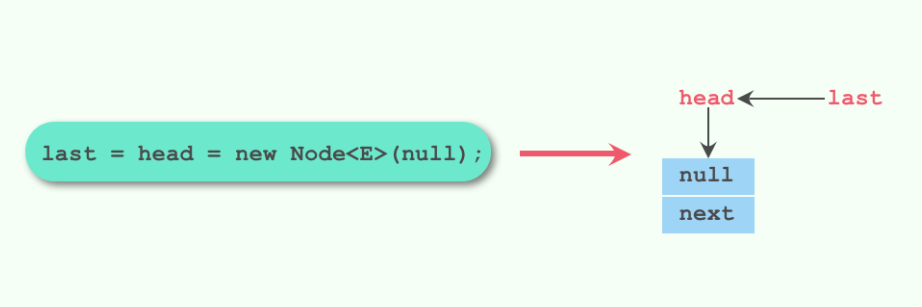
最后一个构造函数使用了putLock来进行加锁,但是这里并不是为了多线程的竞争而加锁,只是为了放入的元素能立即对其他线程可见。
# 3. 入队方法
LinkedBlockingQueue提供了多种入队操作的实现来满足不同情况下的需求,入队操作有如下几种:
# 1. put(E e)
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
// 获取锁中断
putLock.lockInterruptibly();
try {
//判断队列是否已满,如果已满阻塞等待
while (count.get() == capacity) {
notFull.await();
}
// 把node放入队列中
enqueue(node);
c = count.getAndIncrement();
// 再次判断队列是否有可用空间,如果有唤醒下一个线程进行添加操作
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// 如果队列中有一条数据,唤醒消费线程进行消费
if (c == 0)
signalNotEmpty();
}
小结put方法来看,它总共做了以下情况的考虑:
- 队列已满,阻塞等待。
- 队列未满,创建一个node节点放入队列中,如果放完以后队列还有剩余空间,继续唤醒下一个添加线程进行添加。如果放之前队列中没有元素,放完以后要唤醒消费线程进行消费。
# 2. enqueue(Node node)
我们来看看该方法中用到的几个其他方法,先来看看enqueue(Node node)方法:
private void enqueue(Node<E> node) {
last = last.next = node;
}
该方法可能有些同学看不太懂,我们用一张图来看看往队列里依次放入元素A和元素B,毕竟无图无真相:
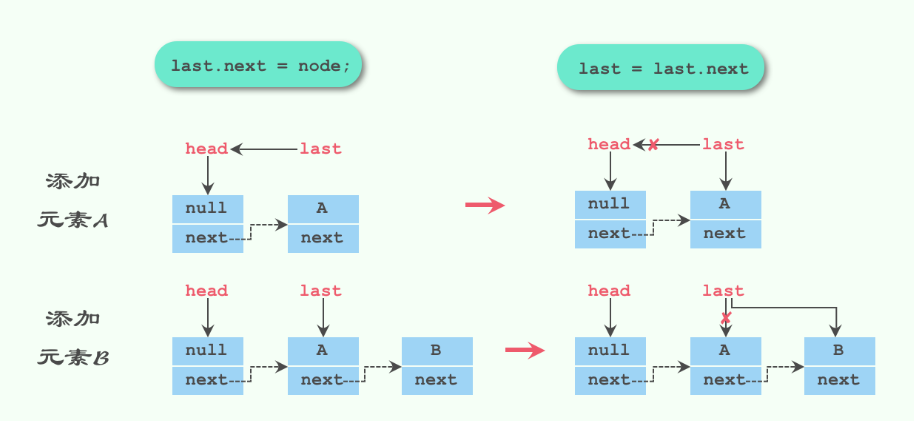
接下来我们看看signalNotEmpty,顺带着看signalNotFull方法:
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
private void signalNotFull() {
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
notFull.signal();
} finally {
putLock.unlock();
}
}
为什么要这么写?因为signal的时候要获取到该signal对应的Condition对象的锁才行。
# 3. offer(E e)
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final AtomicInteger count = this.count;
if (count.get() == capacity)
return false;
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
// 队列有可用空间,放入node节点,判断放入元素后是否还有可用空间,
// 如果有,唤醒下一个添加线程进行添加操作。
if (count.get() < capacity) {
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
}
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return c >= 0;
}
可以看到offer仅仅对put方法改动了一点点,当队列没有可用元素的时候,不同于put方法的阻塞等待,offer方法直接方法false。
# 4. offer(E e, long timeout, TimeUnit unit)
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (e == null) throw new NullPointerException();
long nanos = unit.toNanos(timeout);
int c = -1;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
// 等待超时时间nanos,超时时间到了返回false
while (count.get() == capacity) {
if (nanos <= 0)
return false;
nanos = notFull.awaitNanos(nanos);
}
enqueue(new Node<E>(e));
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return true;
}
该方法只是对offer方法进行了阻塞超时处理,使用了Condition的awaitNanos来进行超时等待,这里为什么要用while循环?因为awaitNanos方法是可中断的,为了防止在等待过程中线程被中断,这里使用while循环进行等待过程中中断的处理,继续等待剩下需等待的时间。
# 4. 出队方法
LinkedBlockingQueue提供了多种出队操作的实现来满足不同情况下的需求
# 1. take()
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
// 队列为空,阻塞等待
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
// 队列中还有元素,唤醒下一个消费线程进行消费
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
// 移除元素之前队列是满的,唤醒生产线程进行添加元素
if (c == capacity)
signalNotFull();
return x;
}
take方法看起来就是put方法的逆向操作,它总共做了以下情况的考虑:
- 队列为空,阻塞等待。
- 队列不为空,从队首获取并移除一个元素,如果消费后还有元素在队列中,继续唤醒下一个消费线程进行元素移除。如果放之前队列是满元素的情况,移除完后要唤醒生产线程进行添加元素。
# 2. dequeue()
我们来看看dequeue方法
private E dequeue() {
// 获取到head节点
Node<E> h = head;
// 获取到head节点指向的下一个节点
Node<E> first = h.next;
// head节点原来指向的节点的next指向自己,等待下次gc回收
h.next = h; // help GC
// head节点指向新的节点
head = first;
// 获取到新的head节点的item值
E x = first.item;
// 新head节点的item值设置为null
first.item = null;
return x;
}
可能有些童鞋链表算法不是很熟悉,我们可以结合注释和图来看就清晰很多了。
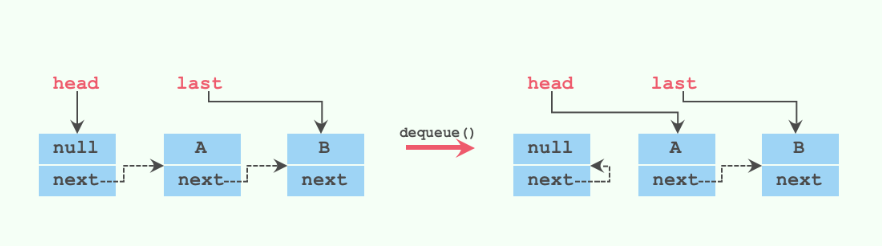
其实这个写法看起来很绕,我们其实也可以这么写:
private E dequeue() {
// 获取到head节点
Node<E> h = head;
// 获取到head节点指向的下一个节点,也就是节点A
Node<E> first = h.next;
// 获取到下下个节点,也就是节点B
Node<E> next = first.next;
// head的next指向下下个节点,也就是图中的B节点
h.next = next;
// 得到节点A的值
E x = first.item;
first.item = null; // help GC
first.next = first; // help GC
return x;
}
# 3. poll()
public E poll() {
final AtomicInteger count = this.count;
if (count.get() == 0)
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
if (count.get() > 0) {
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
}
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
poll方法去除了take方法中元素为空后阻塞等待这一步骤,这里也就不详细说了。同理,poll(long timeout, TimeUnit unit)也和offer(E e, long timeout, TimeUnit unit)一样,利用了Condition的awaitNanos方法来进行阻塞等待直至超时。这里就不列出来说了。
# 5. 获取元素方法
public E peek() {
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
Node<E> first = head.next;
if (first == null)
return null;
else
return first.item;
} finally {
takeLock.unlock();
}
}
加锁后,获取到head节点的next节点,如果为空返回null,如果不为空,返回next节点的item值。
# 6. 删除元素方法
public boolean remove(Object o) {
if (o == null) return false;
// 两个lock全部上锁
fullyLock();
try {
// 从head开始遍历元素,直到最后一个元素
for (Node<E> trail = head, p = trail.next;
p != null;
trail = p, p = p.next) {
// 如果找到相等的元素,调用unlink方法删除元素
if (o.equals(p.item)) {
unlink(p, trail);
return true;
}
}
return false;
} finally {
// 两个lock全部解锁
fullyUnlock();
}
}
void fullyLock() {
putLock.lock();
takeLock.lock();
}
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}
因为remove方法使用两个锁全部上锁,所以其他操作都需要等待它完成,而该方法需要从head节点遍历到尾节点,所以时间复杂度为O(n)。我们来看看unlink方法。
void unlink(Node<E> p, Node<E> trail) {
// p的元素置为null
p.item = null;
// p的前一个节点的next指向p的next,也就是把p从链表中去除了
trail.next = p.next;
// 如果last指向p,删除p后让last指向trail
if (last == p)
last = trail;
// 如果删除之前元素是满的,删除之后就有空间了,唤醒生产线程放入元素
if (count.getAndDecrement() == capacity)
notFull.signal();
}
# 7. 看源码的时候,我给自己抛出了一个问题
- 为什么dequeue里的h.next不指向null,而指向h?
- 为什么unlink里没有p.next = null或者p.next = p这样的操作?
这个疑问一直困扰着我,直到我看了迭代器的部分源码后才豁然开朗,下面放出部分迭代器的源码:
private Node<E> current;
private Node<E> lastRet;
private E currentElement;
Itr() {
fullyLock();
try {
current = head.next;
if (current != null)
currentElement = current.item;
} finally {
fullyUnlock();
}
}
private Node<E> nextNode(Node<E> p) {
for (;;) {
// 解决了问题1
Node<E> s = p.next;
if (s == p)
return head.next;
if (s == null || s.item != null)
return s;
p = s;
}
}
迭代器的遍历分为两步,第一步加双锁把元素放入临时变量中,第二部遍历临时变量的元素。也就是说remove可能和迭代元素同时进行,很有可能remove的时候,有线程在进行迭代操作,而如果unlink中改变了p的next,很有可能在迭代的时候会造成错误,造成不一致问题。这个解决了问题2。
而问题1其实在nextNode方法中也能找到,为了正确遍历,nextNode使用了 s == p的判断,当下一个元素是自己本身时,返回head的下一个节点。
# 8. 总结
LinkedBlockingQueue是一个阻塞队列,内部由两个ReentrantLock来实现出入队列的线程安全,由各自的Condition对象的await和signal来实现等待和唤醒功能。它和ArrayBlockingQueue的不同点在于:
- 队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE),对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
- 数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
- 由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
- 两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
# 9. 锁类型
双锁 + 每个condition
参考:https://blog.csdn.net/tonywu1992/article/details/83419448 (opens new window)
# (3). SynchronousQueue
# 1. 概述
SynchronousQueue是无界的,同时也是一个同步阻塞队列,但它的特别之处在于它内部没有容器。每一个 put操作都必须等待一个take操作。每一个take操作也必须等待一个put操作。
SynchronousQueue是没有容量的,无法存储元素节点信息,不能通过peek方法获取元素,peek方法会直接返回null。由于没有元素,所以不能被迭代,它的iterator方法会返回一个空的迭代器Collections.emptyIterator();
# 2. 用途
SynchronousQueue比较适合线程通信、传递信息、状态切换等应用场景,一个线程必须等待另一个线程传递某些信息给他才可以继续执行。
# 3. 数据结构
# 1. 堆栈
先进后出(LIFO),非公平模式,TransferStack
# 2. 队列
先进先出(FIFO),公平模式,TransferQueue
// Transferer有两个实现类:TransferQueue 和 TransferStack
public SynchronousQueue() {
this(false);
}
//构造函数指定公平策略。默认是非公平
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
# 3. Transferer
Transferer是SynchronousQueue的内部抽象类,双栈和双队列算法共享该类。他只有一个transfer方法,用于转移元素,从生产者转移到消费者;或者消费者调用该方法从生产者取数据。
abstract static class Transferer<E> {
abstract E transfer(E e, boolean timed, long nanos);
}
- e:若不为空,就是put数据,但是当前线程需要等待消费者取走数据才可以返回。若为空,就是消费者来取数据,如果没有数据可以取就阻塞。他取走的数据就是生产者put进来的数据。
- timed:是否设置超时时间
- nanos:超时时间
- transfer方法返回值如果为空,代表超时或者中断
transfer的基本思想:循环处理下面两种情况
- 如果队列是空的,或者队列中都是相同模式(same-mode)的节点,则将当前节点添加到等待队列。等待完成或取消,然后返回匹配的item
- 如果队列中已经存在等待的节点,并且等待的节点与当前节点的模式不同,则将等待队列对头节点出队,返回匹配项。
解释
由于SynchronousQueue是同步阻塞队列,他又不存储任何的数据(等待队列中存的是线程,不是数据队列),那么当队列空时,来了一个put请求,那么他就入队,等待take将数据取走。如果一个put请求来时,队列中已经存在了很多的put线程等待,那么这个线程直接入队,如果已经有很多take线程等待,说明有很多线程等着取数据,那么直接将数据给等待的第一个线程即可,反之亦然。
这里隐含告诉我们:如果队列不为空,那么他们的模式(读还是写)肯定相同。
# 4. 简单demo
public class SynchronousQueueTest2 {
static class SynchronousQueueProducer implements Runnable {
protected BlockingQueue<String> blockingQueue;
public SynchronousQueueProducer(BlockingQueue<String> queue) {
this.blockingQueue = queue;
}
@Override
public void run() {
while (true) {
try {
String data = UUID.randomUUID().toString();
System.out.println("Put: " + data);
blockingQueue.put(data);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class SynchronousQueueConsumer implements Runnable {
protected BlockingQueue<String> blockingQueue;
public SynchronousQueueConsumer(BlockingQueue<String> queue) {
this.blockingQueue = queue;
}
@Override
public void run() {
while (true) {
try {
String data = blockingQueue.take();
System.out.println(Thread.currentThread().getName() + " take(): " + data);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
final BlockingQueue<String> synchronousQueue = new SynchronousQueue<String>();
SynchronousQueueProducer queueProducer = new SynchronousQueueProducer(synchronousQueue);
new Thread(queueProducer).start();
SynchronousQueueConsumer queueConsumer1 = new SynchronousQueueConsumer(synchronousQueue);
new Thread(queueConsumer1).start();
SynchronousQueueConsumer queueConsumer2 = new SynchronousQueueConsumer(synchronousQueue);
new Thread(queueConsumer2).start();
}
}
插入数据的线程和获取数据的线程,交替执行
# 5. 应用场景
Executors.newCachedThreadPool()
/**
* Creates a thread pool that creates new threads as needed, but
* will reuse previously constructed threads when they are
* available, and uses the provided
* ThreadFactory to create new threads when needed.
* @param threadFactory the factory to use when creating new threads
* @return the newly created thread pool
* @throws NullPointerException if threadFactory is null
*/
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
由于ThreadPoolExecutor内部实现任务提交的时候调用的是工作队列(BlockingQueue接口的实现类)的非阻塞式入队列方法(offer方法),因此,在使用SynchronousQueue作为工作队列的前提下,客户端代码向线程池提交任务时,而线程池中又没有空闲的线程能够从SynchronousQueue队列实例中取一个任务,那么相应的offer方法调用就会失败(即任务没有被存入工作队列)。此时,ThreadPoolExecutor会新建一个新的工作者线程用于对这个入队列失败的任务进行处理(假设此时线程池的大小还未达到其最大线程池大小)。
所以,使用SynchronousQueue作为工作队列,工作队列本身并不限制待执行的任务的数量。但此时需要限定线程池的最大大小为一个合理的有限值,而不是Integer.MAX_VALUE,否则可能导致线程池中的工作者线程的数量一直增加到系统资源所无法承受为止。
如果应用程序确实需要比较大的工作队列容量,而又想避免无界工作队列可能导致的问题,不妨考虑SynchronousQueue。SynchronousQueue实现上并不使用存储空间。
使用SynchronousQueue的目的就是保证“对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务”。
参考文档:
SynchronousQueue实现原理:https://zhuanlan.zhihu.com/p/29227508
SynchronousQueue原理解析:https://www.jianshu.com/p/af6f83c78506
Java阻塞队列SynchronousQueue详解:https://www.jianshu.com/p/376d368cb44f
# (4). LinkedTransferQueue
# 1. 概述
LinkedTransferQueue是一个由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻塞队列,LinkedTransferQueue多了tryTransfer和transfer方法。
LinkedTransferQueue采用一种预占模式。意思就是消费者线程取元素时,如果队列不为空,则直接取走数据,若队列为空,那就生成一个节点(节点元素为null)入队,然后消费者线程被等待在这个节点上,后面生产者线程入队时发现有一个元素为null的节点,生产者线程就不入队了,直接就将元素填充到该节点,并唤醒该节点等待的线程,被唤醒的消费者线程取走元素,从调用的方法返回。我们称这种节点操作为“匹配”方式。
LinkedTransferQueue是ConcurrentLinkedQueue、SynchronousQueue(公平模式下转交元素)、LinkedBlockingQueue(阻塞Queue的基本方法)的超集。而且LinkedTransferQueue更好用,因为它不仅仅综合了这几个类的功能,同时也提供了更高效的实现。
# 2. 关键源码剖析
阻塞队列不外乎
put ,take,offer ,poll等方法,再加上TransferQueue的 几个tryTransfer方法。我们看看这几个方法的实现。
# 1. Node
static final class Node {
// 如果是消费者请求的节点,则isData为false,否则该节点为生产(数据)节点为true
final boolean isData; // false if this is a request node
// 数据节点的值,若是消费者节点,则item为null
volatile Object item; // initially non-null if isData; CASed to match
// 指向下一个节点
volatile Node next;
// 等待线程
volatile Thread waiter; // null until waiting
// CAS设置next
final boolean casNext(Node cmp, Node val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// CAS设置item
final boolean casItem(Object cmp, Object val) {
// assert cmp == null || cmp.getClass() != Node.class;
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
// 构造方法
Node(Object item, boolean isData) {
UNSAFE.putObject(this, itemOffset, item); // relaxed write
this.isData = isData;
}
// 将next指向自己
final void forgetNext() {
UNSAFE.putObject(this, nextOffset, this);
}
// 匹配或者节点被取消的时候会调用,设置item自连接,waiter为null
final void forgetContents() {
UNSAFE.putObject(this, itemOffset, this);
UNSAFE.putObject(this, waiterOffset, null);
}
// 节点是否被匹配过了
final boolean isMatched() {
Object x = item;
return (x == this) || ((x == null) == isData);
}
// 是否是一个未匹配的请求节点
// 如果是的话,则isData为false,且item为null,因为如果被匹配过了,item就不再为null,而是指向自己
final boolean isUnmatchedRequest() {
return !isData && item == null;
}
// 如果给定节点不能连接在当前节点后则返回true
final boolean cannotPrecede(boolean haveData) {
boolean d = isData;
Object x;
return d != haveData && (x = item) != this && (x != null) == d;
}
// 匹配一个数据节点
final boolean tryMatchData() {
// assert isData;
Object x = item;
if (x != null && x != this && casItem(x, null)) {
LockSupport.unpark(waiter);
return true;
}
return false;
}
private static final long serialVersionUID = -3375979862319811754L;
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
private static final long waiterOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
waiterOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("waiter"));
} catch (Exception e) {
throw new Error(e);
}
}
}
匹配前后节点item的变化,其中node1为数据节点,node2为消费者请求的占位节点:
| Node | node1(isData-item) | node2(isData-item) |
|---|---|---|
| 匹配前 | true-item | false-null |
| 匹配后 | true-null | false-this |
- 数据节点,则匹配前item不为null且不为自身,匹配后设置为null。
- 占位请求节点,匹配前item为null,匹配后自连接。
# 2. 重要属性
// 是否为多核
private static final boolean MP =
Runtime.getRuntime().availableProcessors() > 1;
// 作为第一个等待节点在阻塞之前的自旋次数
private static final int FRONT_SPINS = 1 << 7;
// 前驱节点正在处理,当前节点在阻塞之前的自旋次数
private static final int CHAINED_SPINS = FRONT_SPINS >>> 1;
// sweepVotes的阈值
static final int SWEEP_THRESHOLD = 32;
// 队列首节点
transient volatile Node head;
// 队列尾节点
private transient volatile Node tail;
// 断开被删除节点失败的次数
private transient volatile int sweepVotes;
// xfer方法的how参数的可能取值
// 用于无等待的poll、tryTransfer
private static final int NOW = 0; // for untimed poll, tryTransfer
// 用于offer、put、add
private static final int ASYNC = 1; // for offer, put, add
// 用于无超时的阻塞transfer、take
private static final int SYNC = 2; // for transfer, take
// 用于超时等待的poll、tryTransfer
private static final int TIMED = 3; // for timed poll, tryTransfer
# 3. 入队出队方法
// 入队方法
public void put(E e) {
xfer(e, true, ASYNC, 0);
}
public boolean offer(E e, long timeout, TimeUnit unit) {
xfer(e, true, ASYNC, 0);
return true;
}
public boolean offer(E e) {
xfer(e, true, ASYNC, 0);
return true;
}
public boolean add(E e) {
xfer(e, true, ASYNC, 0);
return true;
}
public boolean tryTransfer(E e) {
return xfer(e, true, NOW, 0) == null;
}
public void transfer(E e) throws InterruptedException {
if (xfer(e, true, SYNC, 0) != null) {
Thread.interrupted(); // failure possible only due to interrupt
throw new InterruptedException();
}
}
public boolean tryTransfer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (xfer(e, true, TIMED, unit.toNanos(timeout)) == null)
return true;
if (!Thread.interrupted())
return false;
throw new InterruptedException();
}
// 出队方法
public E take() throws InterruptedException {
E e = xfer(null, false, SYNC, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
public E poll() {
return xfer(null, false, NOW, 0);
}
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
E e = xfer(null, false, TIMED, unit.toNanos(timeout));
if (e != null || !Thread.interrupted())
return e;
throw new InterruptedException();
}
我们可以看到,这些出队、入队方法都会调用xfer方法,因为LinkedTransferQueue是无界的,入队操作都会成功,所以入队操作都是ASYNC的,而出队方法,则是根据不同的要求传入不同的值,比如需要阻塞的出队方法就传入SYNC,需要加入超时控制的就传入TIMED。
# 4. xfer方法
private E xfer(E e, boolean haveData, int how, long nanos) {
// 如果haveData但是e为null,则抛出NullPointerException异常
if (haveData && (e == null))
throw new NullPointerException();
// s是将要被添加的节点,如果需要
Node s = null; // the node to append, if needed
retry:
for (;;) { // restart on append race
// 从首节点开始匹配
for (Node h = head, p = h; p != null;) { // find & match first node
boolean isData = p.isData;
Object item = p.item;
// 判断节点是否被匹配过
// item != null有2种情况:一是put操作,二是take的item被修改了(匹配成功)
// (itme != null) == isData 要么表示p是一个put操作,要么表示p是一个还没匹配成功的take操作
if (item != p && (item != null) == isData) { // unmatched
// 节点与此次操作模式一致,无法匹配
if (isData == haveData) // can't match
break;
// 匹配成功
if (p.casItem(item, e)) { // match
for (Node q = p; q != h;) {
Node n = q.next; // update by 2 unless singleton
// 更新head为匹配节点的next节点
if (head == h && casHead(h, n == null ? q : n)) {
// 将旧节点自连接
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
// 匹配成功,则唤醒阻塞的线程
LockSupport.unpark(p.waiter);
// 类型转换,返回匹配节点的元素
return LinkedTransferQueue.<E>cast(item);
}
}
// 若节点已经被匹配过了,则向后寻找下一个未被匹配的节点
Node n = p.next;
// 如果当前节点已经离队,则从head开始寻找
p = (p != n) ? n : (h = head); // Use head if p offlist
}
// 若整个队列都遍历之后,还没有找到匹配的节点,则进行后续处理
// 把当前节点加入到队列尾
if (how != NOW) { // No matches available
if (s == null)
s = new Node(e, haveData);
// 将新节点s添加到队列尾并返回s的前驱节点
Node pred = tryAppend(s, haveData);
// 前驱节点为null,说明有其他线程竞争,并修改了队列,则从retry重新开始
if (pred == null)
continue retry; // lost race vs opposite mode
// 不为ASYNC方法,则同步阻塞等待
if (how != ASYNC)
return awaitMatch(s, pred, e, (how == TIMED), nanos);
}
// how == NOW,则立即返回
return e; // not waiting
}
}
xfer方法的整个操作流程如下所示:
- 寻找和操作匹配的节点
- 从head开始向后遍历寻找未被匹配的节点,找到一个未被匹配并且和本次操作的模式不同的节点,匹配节点成功就通过CAS 操作将匹配节点的item字段设置为e,若修改失败,则继续向后寻找节点
- 通过CAS操作更新head节点为匹配节点的next节点,旧head节点进行自连接,唤醒匹配节点的等待线程waiter,返回匹配的 item。如果CAS失败,并且松弛度大于等于2,就需要重新获取head重试。
- 如果在上述操作中没有找到匹配节点,则根据参数how做不同的处理:
- NOW:立即返回,也不会插入节点
- SYNC:插入一个item为e(isData = haveData)到队列的尾部,然后自旋或阻塞当前线程直到节点被匹配或者取消。
- ASYNC:插入一个item为e(isData = haveData)到队列的尾部,不阻塞直接返回。
上面提到了一个松弛度的概念,它是什么作用呢?
在节点被匹配(被删除)之后,不会立即更新head/tail,而是当 head/tail 节点和最近一个未匹配的节点之间的距离超过一个“松弛阀值”之后才会更新(在LinkedTransferQueue中,这个值为 2)。这个“松弛阀值”一般为1-3,如果太大会降低缓存命中率,并且会增加遍历链的长度;太小会增加 CAS 的开销。
# 5. 入队操作则是调用了tryAppend方法
private Node tryAppend(Node s, boolean haveData) {
// 从尾节点开始
for (Node t = tail, p = t;;) { // move p to last node and append
Node n, u; // temps for reads of next & tail
// 队列为空,则将s设置为head并返回s
if (p == null && (p = head) == null) {
if (casHead(null, s))
return s; // initialize
}
else if (p.cannotPrecede(haveData))
return null; // lost race vs opposite mode
// 不是最后一个节点
else if ((n = p.next) != null) // not last; keep traversing
p = p != t && t != (u = tail) ? (t = u) : // stale tail
(p != n) ? n : null; // restart if off list
// CAS失败
else if (!p.casNext(null, s))
p = p.next; // re-read on CAS failure
else {
// 更新tail
if (p != t) { // update if slack now >= 2
while ((tail != t || !casTail(t, s)) &&
(t = tail) != null &&
(s = t.next) != null && // advance and retry
(s = s.next) != null && s != t);
}
return p;
}
}
}
该方法主要逻辑为:添加节点s到队列尾并返回s的前继节点,失败时(与其他不同模式线程竞争失败)返回null,没有前继节点则返回自身。
加入队列后,如果how还不是ASYNC则调用awaitMatch()方法阻塞等待:
# 6. awaitMatch阻塞等待
private E awaitMatch(Node s, Node pred, E e, boolean timed, long nanos) {
// 计算超时时间点
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 获取当前线程对象
Thread w = Thread.currentThread();
// 自旋次数
int spins = -1; // initialized after first item and cancel checks
// 随机数
ThreadLocalRandom randomYields = null; // bound if needed
for (;;) {
Object item = s.item;
// 若有其它线程匹配了该节点
if (item != e) { // matched
// assert item != s;
// 撤销该节点,并返回匹配值
s.forgetContents(); // avoid garbage
return LinkedTransferQueue.<E>cast(item);
}
// 线程中断或者超时,则将s的节点item设置为s
if ((w.isInterrupted() || (timed && nanos <= 0)) &&
s.casItem(e, s)) { // cancel
// 断开节点
unsplice(pred, s);
return e;
}
// 自旋
if (spins < 0) { // establish spins at/near front
// 计算自旋次数
if ((spins = spinsFor(pred, s.isData)) > 0)
randomYields = ThreadLocalRandom.current();
}
else if (spins > 0) { // spin
--spins;
// 生成随机数来让出CPU时间
if (randomYields.nextInt(CHAINED_SPINS) == 0)
Thread.yield(); // occasionally yield
}
// 将s的waiter设置为当前线程
else if (s.waiter == null) {
s.waiter = w; // request unpark then recheck
}
// 超时阻塞
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos > 0L)
LockSupport.parkNanos(this, nanos);
}
// 非超时阻塞
else {
LockSupport.park(this);
}
}
}
当前操作为同步操作时,会调用awaitMatch方法阻塞等待匹配,成功返回匹配节点 item,失败返回给定参数e(s.item)。在等待期间如果线程被中断或等待超时,则取消匹配,并调用unsplice方法解除节点s和其前继节点的链接。
# 7. unsplice解除节点链接
final void unsplice(Node pred, Node s) {
// 设置item自连接,waiter为null
s.forgetContents(); // forget unneeded fields
if (pred != null && pred != s && pred.next == s) {
// 获取s的后继节点
Node n = s.next;
// s的后继节点为null,或不为null,就将s的前驱节点的后继节点设置为n
if (n == null ||
(n != s && pred.casNext(s, n) && pred.isMatched())) {
for (;;) { // check if at, or could be, head
Node h = head;
if (h == pred || h == s || h == null)
return; // at head or list empty
if (!h.isMatched())
break;
Node hn = h.next;
if (hn == null)
return; // now empty
if (hn != h && casHead(h, hn))
h.forgetNext(); // advance head
}
if (pred.next != pred && s.next != s) { // recheck if offlist
for (;;) { // sweep now if enough votes
int v = sweepVotes;
if (v < SWEEP_THRESHOLD) {
if (casSweepVotes(v, v + 1))
break;
}
// 达到阀值,进行“大扫除”,清除队列中的无效节点
else if (casSweepVotes(v, 0)) {
sweep();
break;
}
}
}
}
}
}
如果s的前继节点pred还是指向s(pred.next == s),尝试解除s的链接,若s不是自连接节点,就把pred的next引用指向s的next节点。如果s不能被解除(由于它是尾节点或者pred可能被解除链接,并且pred和s都不是head节点或已经出列),则添加到sweepVotes,sweepVotes累计到阀值SWEEP_THRESHOLD之后就调用sweep()对队列进行一次“大扫除”,清除队列中所有的无效节点:
# 8. sweep清除无效节点
private void sweep() {
for (Node p = head, s, n; p != null && (s = p.next) != null; ) {
if (!s.isMatched())
// Unmatched nodes are never self-linked
p = s;
else if ((n = s.next) == null) // trailing node is pinned
break;
else if (s == n) // stale
// No need to also check for p == s, since that implies s == n
p = head;
else
p.casNext(s, n);
}
}
# 9. 整个过程如下图:
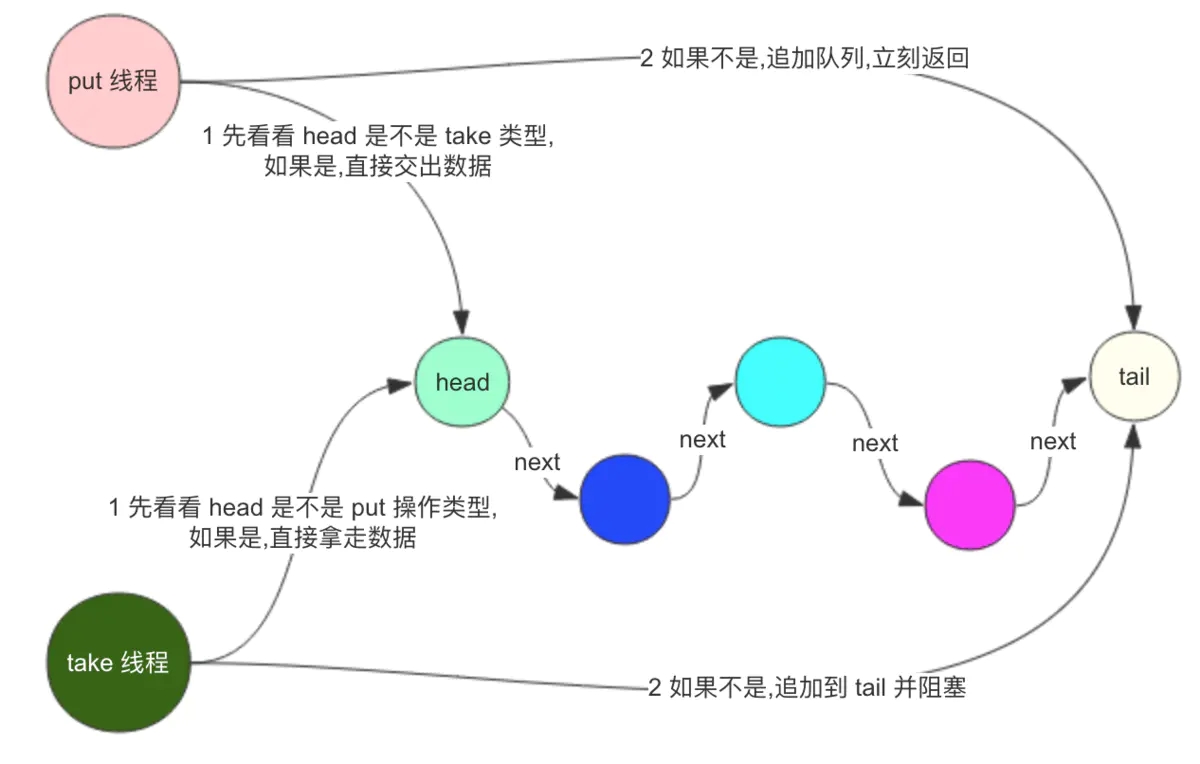
相比较 SynchronousQueue 多了一个可以存储的队列,相比较 LinkedBlockingQueue 多了直接传递元素,少了用锁来同步。性能更高,用处更大。
# 10. 总结
LinkedTransferQueue是 SynchronousQueue 和 LinkedBlockingQueue 的合体,性能比 LinkedBlockingQueue 更高(没有锁操作),比 SynchronousQueue能存储更多的元素。
当 put 时,如果有等待的线程,就直接将元素 “交给” 等待者, 否则直接进入队列。
put和 transfer 方法的区别是,put 是立即返回的, transfer 是阻塞等待消费者拿到数据才返回。transfer方法和 SynchronousQueue的 put 方法类似。
参考文档:
https://blog.csdn.net/qq_38293564/article/details/80593821 (opens new window)
# (5). PriorityBlockingQueue
# 1. 概述
PriorityBlockingQueue是一个支持优先级的无界阻塞队列,直到系统资源耗尽。默认情况下元素采用自然顺序升序排列。也可以自定义类实现compareTo()方法来指定元素排序规则,或者初始化PriorityBlockingQueue时,指定构造参数Comparator来对元素进行排序。但需要注意的是不能保证同优先级元素的顺序。PriorityBlockingQueue也是基于最小二叉堆实现,使用基于CAS实现的自旋锁来控制队列的动态扩容,保证了扩容操作不会阻塞take操作的执行。
# 2. 前置知识:优先队列(堆)
# 1. 队列与优先队列的区别
- 队列是一种FIFO(First-In-First-Out)先进先出的数据结构,对应于生活中的排队的场景,排在前面的人总是先通过,依次进行。
- 优先队列是特殊的队列,从“优先”一词,可看出有“插队现象”。比如在火车站排队进站时,就会有些比较急的人来插队,他们就在前面先通过验票。优先队列至少含有两种操作的数据结构:insert(插入),即将元素插入到优先队列中(入队);以及deleteMin(删除最小者),它的作用是找出、删除优先队列中的最小的元素(出队)。
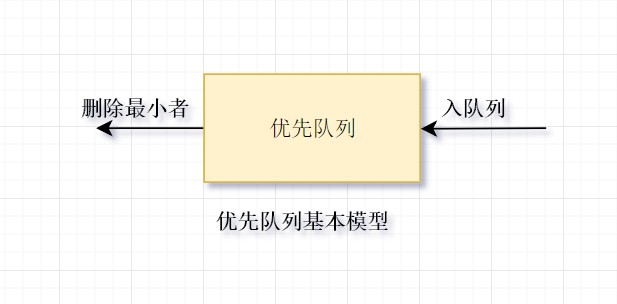
# 2. 优先队列(堆)的特性
优先队列的实现常选用二叉堆,在数据结构中,优先队列一般也是指堆。
堆的两个性质:
- 结构性:堆是一颗除底层外被完全填满的二叉树,底层的节点从左到右填入,这样的树叫做完全二叉树。
- 堆序性:由于我们想很快找出最小元,则最小元应该在根上,任意节点都小于它的后裔,这就是小顶堆(Min-Heap);如果是查找最大元,则最大元应该在根上,任意节点都要大于它的后裔,这就是大顶堆(Max-heap)。
# 3. 结构性
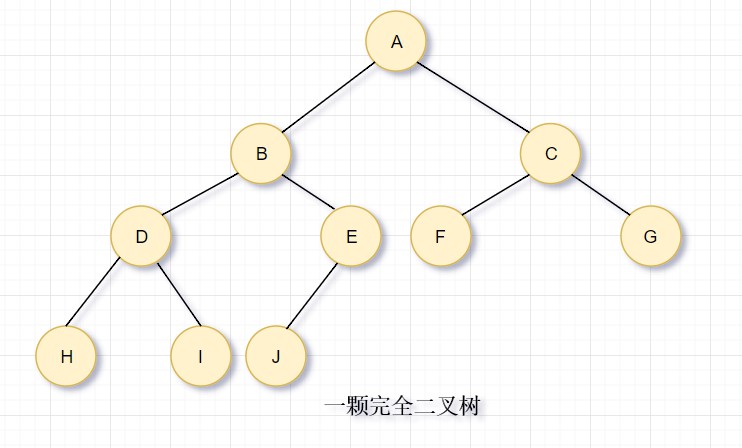
通过观察发现,完全二叉树可以直接使用一个数组表示而不需要使用其他数据结构。所以我们只需要传入一个size就可以构建优先队列的结构(元素之间使用compareTo方法进行比较)。
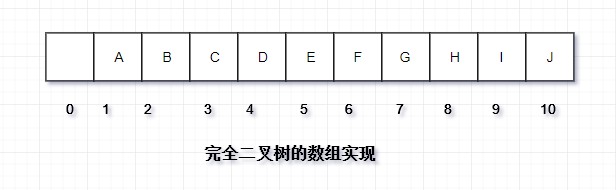
对于数组中的任意位置 i 的元素,其左儿子在位置 2i 上,则右儿子在 2i+1 上,父节点在 在 i/2(向下取整)上。通常从数组下标1开始存储,这样的好处在于很方便找到左右、及父节点。如果从0开始,左儿子在2i+1,右儿子在2i+2,父节点在(i-1)/2(向下取整)。
# 4. 堆序性
我们这建立最小堆,即对于每一个元素X,X的父亲中的关键字小于(或等于)X中的关键字,根节点除外(它没有父节点)。
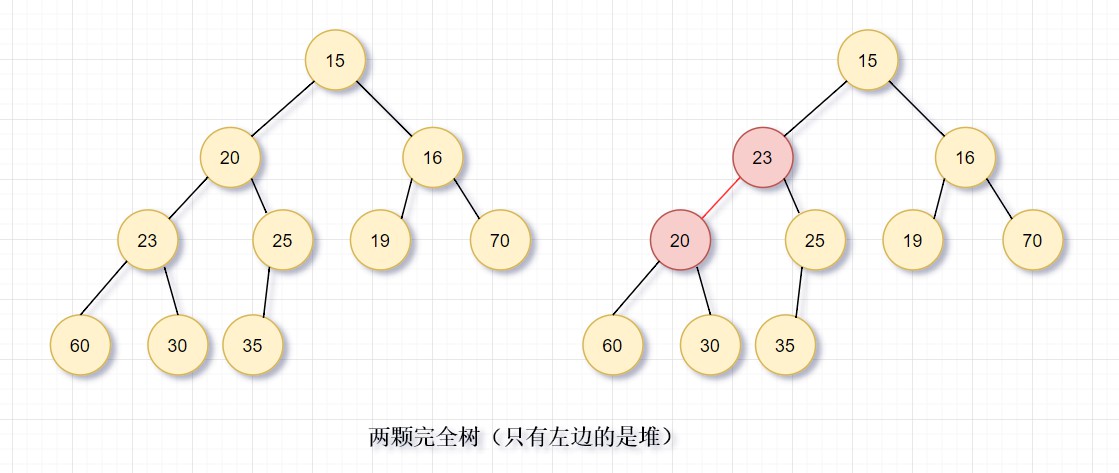
如图所示,只有左边是堆,右边红色节点违反堆序性。根据堆序性,只需要常O(1)找到最小元。
# 5. 堆的基本操作:insert(插入)
上滤:为了插入元素X,我们在下一个可用的位置建立空穴(否则会破坏结构性,不是完全二叉树)。**如果此元素放入空穴不破坏堆序性,则插入完成;否则,将父节点下移到空穴,即空穴向根的方向上冒一步。**继续该过程,直到X插入空穴为止。这样的过程称为上滤。
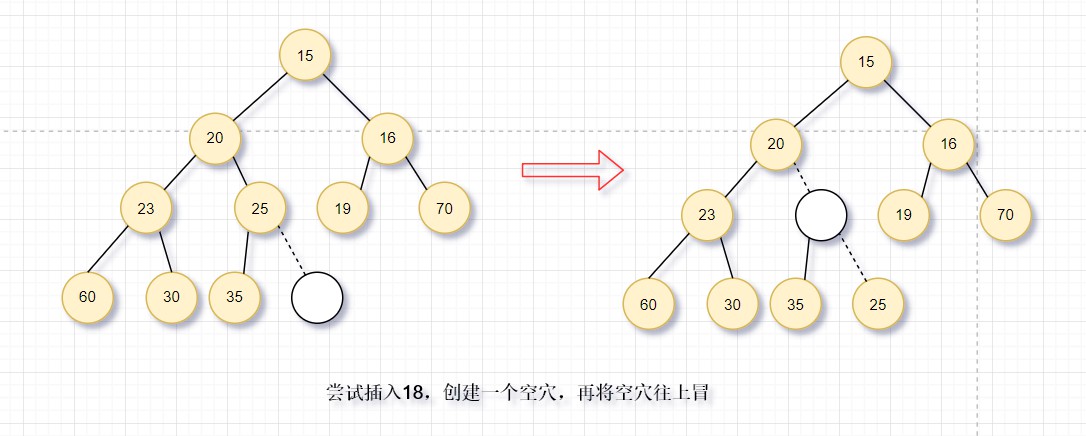
图中演示了18插入的过程,**在下一个可用的位置建立空穴(满足结构性),发现不能直接插入,将父节点移下来,空穴上冒。继续这个过程,直到满足堆序性。**这样就实现了元素插入到优先队列(堆)中。
# 6. java实现上滤
/**
* 插入到优先队列,维护堆序性
*
* @param x :插入的元素
*/
public void insert(T x) {
if (null == x) {
return;
}
//扩容
if (currentSize == array.length - 1) {
enlargeArray(array.length * 2 + 1);
}
//上滤
int hole = ++currentSize;
for (array[0] = x; x.compareTo(array[hole / 2]) < 0; hole /= 2) {
array[hole] = array[hole / 2];
}
array[hole] = x;
}
/**
* 扩容方法
*
* @param newSize :扩容后的容量,为原来的2倍+1
*/
private void enlargeArray(int newSize) {
T[] old = array;
array = (T[]) new Comparable[newSize];
System.arraycopy(old, 0, array, 0, old.length);
}
可以反复使用交换操作来进行上滤过程,但如果插入X上滤d层,则需要3d次赋值;我们这种方式只需要d+1次赋值。
如果插入的元素是新的最小元从而一直上滤到根处,那么这种插入的时间长达O(logN)。但平均来看,上滤终止得要早。**业已证明,执行依次插入平均需要2.607次比较,因此平均insert操作上移元素1.607层。**上滤次数只比插入次数少一次。
# 7. 堆的基本操作:deleteMin(删除)
下滤:类似于上滤操作。因为我们建立的是最小堆,所以删除最小元,就是将根节点删掉,这样就破坏了结构性。所以**我们在根节点处建立空穴,为了满足结构性,堆中最后一个元素X必须移动到合适的位置,如果可以直接放到空穴,则删除完成(一般不可能);否则,将空穴的左右儿子中较小者移到空穴,即空穴下移了一层。继续这样的操作,直到X可以放入到空穴中。**这样就可以满足结构性与堆序性。这个过程称为下滤。
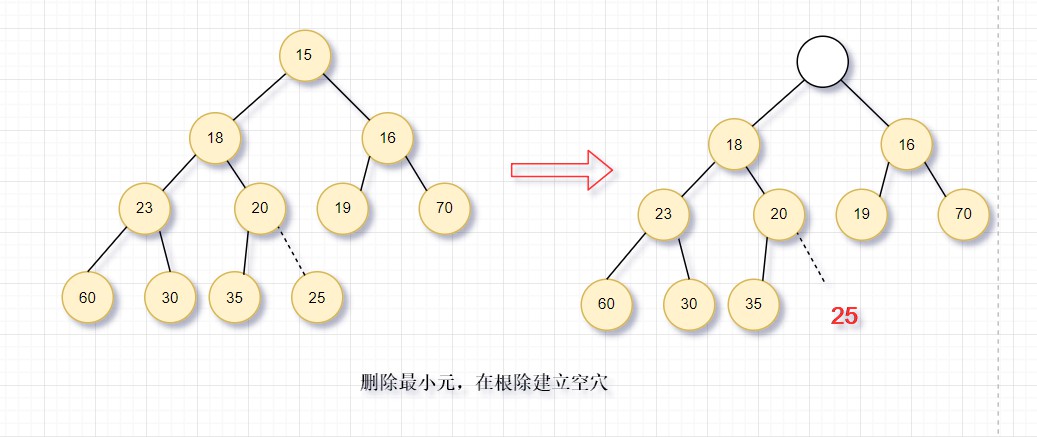
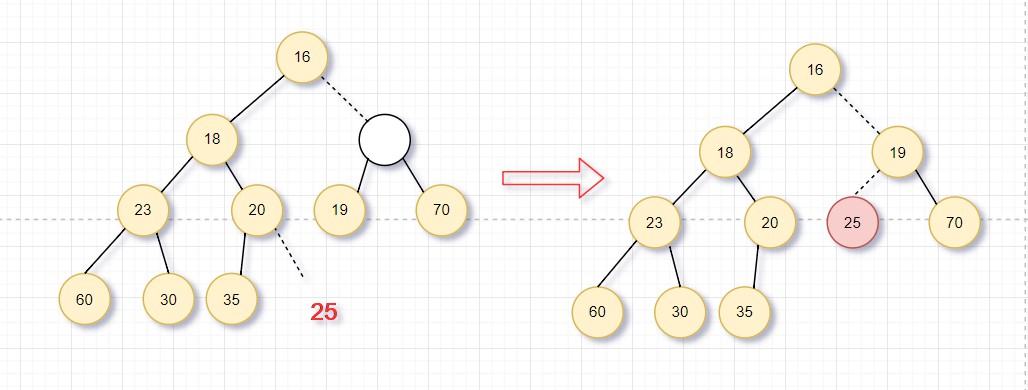
如图所示:在根处建立空穴,将最后一个元素放到空穴,已满足结构性;为满足堆序性,需要将空穴下移到合适的位置。
注意:堆的实现中,经常发生的错误是只有偶数个元素,即有一个节点只有一个儿子。所以需要测试右儿子的存在性。
# 8. java实现下滤
/**
* 删除最小元
* 若优先队列为空,抛出UnderflowException
*
* @return :返回最小元
*/
public T deleteMin() {
if (isEmpty()) {
throw new UnderflowException();
}
T minItem = findMin();
array[1] = array[currentSize--];
percolateDown(1);
return minItem;
}
/**
* 下滤方法
*
* @param hole :从数组下标hole1开始下滤
*/
private void percolateDown(int hole) {
int child;
T tmp = array[hole];
for (; hole * 2 <= currentSize; hole = child) {
//左儿子
child = hole * 2;
//判断右儿子是否存在
if (child != currentSize &&
array[child + 1].compareTo(array[child]) < 0) {
child++;
}
if (array[child].compareTo(tmp) < 0) {
array[hole] = array[child];
} else {
break;
}
}
array[hole] = tmp;
}
这种操作最坏时间复杂度是O(logN)。平均而言,被放到根处的元素几乎下滤到底层(即来自的那层),所以平均时间复杂度是O(logN)。
# 7. 总结
优先队列常使用二叉堆实现,本篇图解了二叉堆最基本的两个操作:插入及删除最小元。insert以O(1)常数时间执行,deleteMin以O(logN)执行。
# 3. 源码剖析
# 1. 定义的重要属性
// 默认容量
private static final int DEFAULT_INITIAL_CAPACITY = 11;
// 最大容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 二叉堆数组
private transient Object[] queue;
// 队列元素的个数
private transient int size;
// 比较器,如果为空,则为自然顺序
private transient Comparator<? super E> comparator;
// 内部锁
private final ReentrantLock lock;
private final Condition notEmpty;
//
private transient volatile int allocationSpinLock;
// 优先队列:主要用于序列化,这是为了兼容之前的版本。只有在序列化和反序列化才非空
private PriorityQueue<E> q;
内部仍然采用可重入锁ReentrantLock来实现同步机制,但是这里只有一个notEmpty的Condition,了解了ArrayBlockingQueue我们知道它定义了两个Condition,之类为何只有一个呢?原因就在于PriorityBlockingQueue是一个无界队列,插入总是会成功,除非消耗尽了资源导致服务器挂。
# 2. 入列:put
put(E e) :将指定元素插入此优先级队列。
public void put(E e) {
offer(e); // never need to block
}
PriorityBlockingQueue是无界的,所以不可能会阻塞。内部调用offer(E e):
# 3. 入列:offer
public boolean offer(E e) {
// 不能为null
if (e == null)
throw new NullPointerException();
// 获取锁
final ReentrantLock lock = this.lock;
lock.lock();
int n, cap;
Object[] array;
// 扩容
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
// 根据比较器是否为null,做不同的处理
if (cmp == null)
siftUpComparable(n, e, array);
else
siftUpUsingComparator(n, e, array, cmp);
size = n + 1;
// 唤醒正在等待的消费者线程
notEmpty.signal();
} finally {
lock.unlock();
}
return true;
}
# 4. siftUpComparable
当比较器comparator为null时,采用自然排序,调用siftUpComparable方法:
private static <T> void siftUpComparable(int k, T x, Object[] array) {
Comparable<? super T> key = (Comparable<? super T>) x;
// “上冒”过程
while (k > 0) {
// 父级节点 (n - ) / 2
int parent = (k - 1) >>> 1;
Object e = array[parent];
// key >= parent 完成(最大堆)
if (key.compareTo((T) e) >= 0)
break;
// key < parant 替换
array[k] = e;
k = parent;
}
array[k] = key;
}
这段代码所表示的意思:将元素X插入到数组中,然后进行调整以保持二叉堆的特性。
# 5. siftUpUsingComparator
当比较器不为null时,采用所指定的比较器,调用siftUpUsingComparator方法:
private static <T> void siftUpUsingComparator(int k, T x, Object[] array,
Comparator<? super T> cmp) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = array[parent];
if (cmp.compare(x, (T) e) >= 0)
break;
array[k] = e;
k = parent;
}
array[k] = x;
}
# 6. tryGrow:扩容
private void tryGrow(Object[] array, int oldCap) {
lock.unlock(); // 扩容操作使用自旋,不需要锁主锁,释放
Object[] newArray = null;
// CAS 占用
if (allocationSpinLock == 0 && UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset, 0, 1)) {
try {
// 新容量 最小翻倍
int newCap = oldCap + ((oldCap < 64) ? (oldCap + 2) : (oldCap >> 1));
// 超过
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE; // 最大容量
}
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0; // 扩容后allocationSpinLock = 0 代表释放了自旋锁
}
}
// 到这里如果是本线程扩容newArray肯定是不为null,为null就是其他线程在处理扩容,那就让给别的线程处理
if (newArray == null)
Thread.yield();
// 主锁获取锁
lock.lock();
// 数组复制
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
整个添加元素的过程和上面二叉堆一模一样:先将元素添加到数组末尾,然后采用“上冒”的方式将该元素尽量往上冒。
# 7. 出列:poll
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return dequeue();
} finally {
lock.unlock();
}
}
先获取锁,然后调用dequeue()方法:
# 8. dequeue
private E dequeue() {
// 没有元素 返回null
int n = size - 1;
if (n < 0)
return null;
else {
Object[] array = queue;
// 出对元素
E result = (E) array[0];
// 最后一个元素(也就是插入到空穴中的元素)
E x = (E) array[n];
array[n] = null;
// 根据比较器释放为null,来执行不同的处理
Comparator<? super E> cmp = comparator;
if (cmp == null)
siftDownComparable(0, x, array, n);
else
siftDownUsingComparator(0, x, array, n, cmp);
size = n;
return result;
}
}
# 9. siftDownComparable
如果比较器为null,则调用siftDownComparable来进行自然排序处理:
private static <T> void siftDownComparable(int k, T x, Object[] array,
int n) {
if (n > 0) {
Comparable<? super T> key = (Comparable<? super T>)x;
// 最后一个叶子节点的父节点位置
int half = n >>> 1;
while (k < half) {
int child = (k << 1) + 1; // 待调整位置左节点位置
Object c = array[child]; //左节点
int right = child + 1; //右节点
//左右节点比较,取较小的
if (right < n &&
((Comparable<? super T>) c).compareTo((T) array[right]) > 0)
c = array[child = right];
//如果待调整key最小,那就退出,直接赋值
if (key.compareTo((T) c) <= 0)
break;
//如果key不是最小,那就取左右节点小的那个放到调整位置,然后小的那个节点位置开始再继续调整
array[k] = c;
k = child;
}
array[k] = key;
}
}
处理思路和二叉堆删除节点的逻辑一样:就第一个元素定义为空穴,然后把最后一个元素取出来,尝试插入到空穴位置,并与两个子节点值进行比较,如果不符合,则与其中较小的子节点进行替换,然后继续比较调整。
# 10. siftDownUsingComparator
如果指定了比较器,则采用比较器来进行调整:
private static <T> void siftDownUsingComparator(int k, T x, Object[] array,
int n,
Comparator<? super T> cmp) {
if (n > 0) {
int half = n >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = array[child];
int right = child + 1;
if (right < n && cmp.compare((T) c, (T) array[right]) > 0)
c = array[child = right];
if (cmp.compare(x, (T) c) <= 0)
break;
array[k] = c;
k = child;
}
array[k] = x;
}
}
PriorityBlockingQueue采用二叉堆来维护,所以整个处理过程不是很复杂,添加操作则是不断“上冒”,而删除操作则是不断“下掉”。掌握二叉堆就掌握了PriorityBlockingQueue,无论怎么变还是。对于PriorityBlockingQueue需要注意的是他是一个无界队列,所以添加操作是不会失败的,除非资源耗尽。
# 4. 参考文档:
最详细版图解优先队列(堆):https://www.cnblogs.com/9dragon/p/10739121.html (opens new window)
PriorityBlockingQueue 源码分析:https://www.cnblogs.com/yaowen/p/10708249.html (opens new window)
JUC之阻塞队列PriorityBlockingQueue:https://www.jianshu.com/p/43954715aa28 (opens new window)
# (6). DelayQueue
# 1. 概述
DelayQueue是一个无界的BlockingQueue实现,加入其中的元素必需实现Delayed接口。当生产者线程调用put之类的方法加入元素时,会触发Delayed接口中的compareTo方法进行排序,也就是说队列中元素的顺序是按到期时间排序的,而非它们进入队列的顺序。排在队列头部的元素是最早到期的,越往后到期时间赿晚。
执行过程描述
消费者线程查看队列头部的元素,注意是查看不是取出。然后调用元素的getDelay方法,如果此方法返回的值小0或者等于0,则消费者线程会从队列中取出此元素,并进行处理。如果getDelay方法返回的值大于0,则消费者线程wait返回的时间值后,再从队列头部取出元素,此时元素应该已经到期。
DelayQueue是Leader-Followr模式的变种,消费者线程处于等待状态时,总是等待最先到期的元素,而不是长时间的等待。消费者线程尽量把时间花在处理任务上,最小化空等的时间,以提高线程的利用效率。
以下通过队列及消费者线程状态变化大致说明一下DelayQueue的运行过程。
# 2. 初始状态
因为队列是没有边界的,向队列中添加元素的线程不会阻塞,添加操作相对简单,所以此图不考虑向队列添加元素的生产者线程。假设现在共有三个消费者线程。
队列中的元素按到期时间排序,队列头部的元素2s以后到期。消费者线程1查看了头部元素以后,发现还需要2s才到期,于是它进入等待状态,2s以后醒来,等待头部元素到期的线程称为Leader线程。
消费者线程2与消费者线程3处于待命状态,它们不等待队列中的非头部元素。当消费者线程1拿到对象5以后,会向它们发送signal。这个时候两个中的一个会结束待命状态而进入等待状态。
# 3. 2s以后
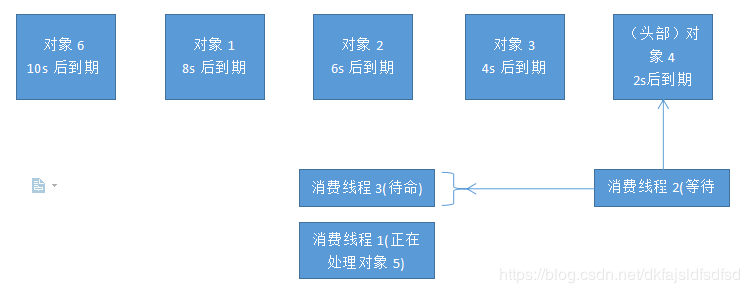
消费者线程1已经拿到了对象5,从等待状态进入处理状态,处理它取到的对象5,同时向消费者线程2与消费者线程3发送signal。
消费者线程2与消费者线程3会争抢领导权,这里是消费者线程2进入等待状态,成为Leader线程,等待2s以后对象4到期。而消费者线程3则继续处于待命状态。
此时队列中加入了一个新元素对象6,它10s后到期,排在队尾。
# 4. 又2s之后
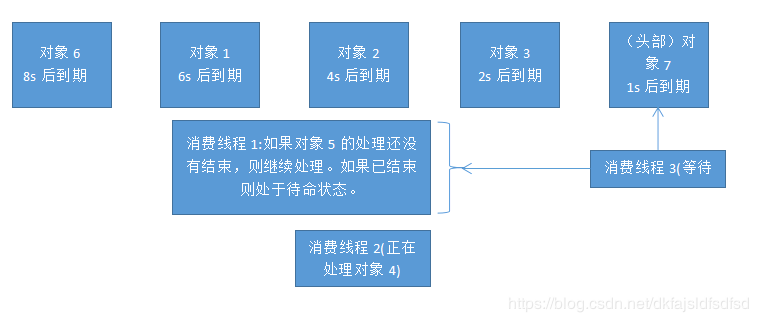
先看线程1,如果它已经结束了对象5的处理,则进入待命状态。如果还没有结束,则它继续处理对象5。
消费线程2取到对象4以后,也进入处理状态,同时给处于待命状态的消费线程3发送信号,消费线程3进入等待状态,成为新的Leader。现在头部元素是新插入的对象7,因为它1s以后就过期,要早于其它所有元素,所以排到了队列头部。
# 5. 又1s之后
一种不好的结果:
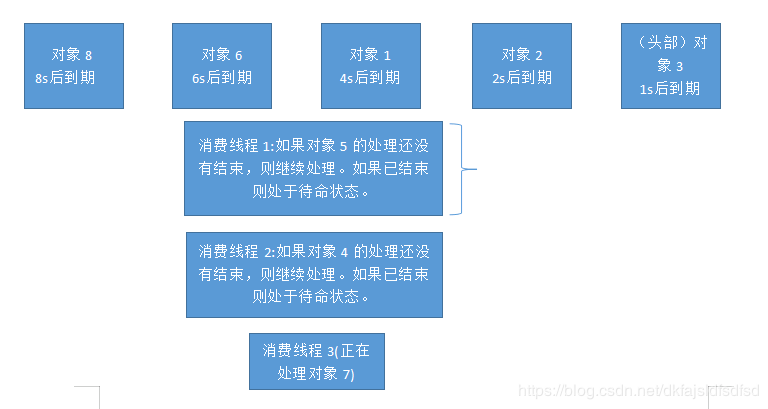
消费线程3一定正在处理对象7。消费线程1与消费线程2还没有处理完它们各自取得的对象,无法进入待命状态,也更加进入不了等待状态。此时对象3马上要到期,那么如果它到期时没有消费者线程空下来,则它的处理一定会延期。
可以想见,如果元素进入队列的速度很快,元素之间的到期时间相对集中,而处理每个到期元素的速度又比较慢的话,则队列会越来越大,队列后边的元素延期处理的时间会越来越长。
好的结果:
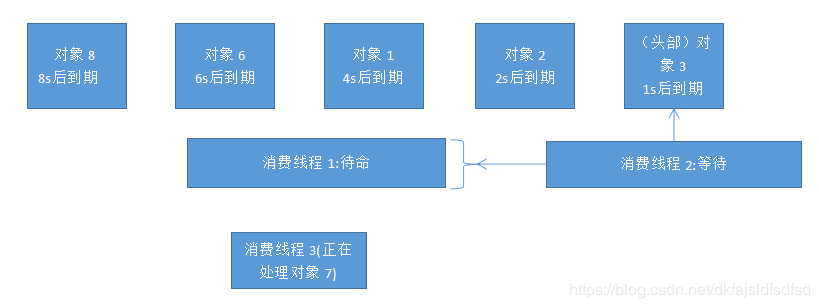
消费线程1与消费线程2很快的完成对取出对象的处理,及时返回重新等待队列中的到期元素。一个处于等待状态(Leader),对象3一到期就立刻处理。另一个则处于待命状态。这样,每一个对象都能在到期时被及时处理,不会发生明显的延期。
所以,消费者线程的数量要够,处理任务的速度要快。否则,队列中的到期元素无法被及时取出并处理,造成任务延期、队列元素堆积等情况。
# 6. 示例代码
DelayQueue的一个应用场景是定时任务调度。本例中先让主线程向DelayQueue添加10个任务,任务之间的启动间隔在1~2s之间,每个任务的执行时间固定为2s,代码如下:
package com.zhangdb.thread;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
class DelayTask implements Delayed {
private static long currentTime = System.currentTimeMillis();
protected final String taskName;
protected final int timeCost;
protected final long scheduleTime;
protected static final AtomicInteger taskCount = new AtomicInteger(0);
// 定时任务之间的启动时间间隔在1~2s之间,timeCost表示处理此任务需要的时间,本示例中为2s
public DelayTask(String taskName, int timeCost) {
this.taskName = taskName;
this.timeCost = timeCost;
taskCount.incrementAndGet();
currentTime += 1000 + (long) (Math.random() * 1000);
scheduleTime = currentTime;
}
@Override
public int compareTo(Delayed o) {
return (int) (this.scheduleTime - ((DelayTask) o).scheduleTime);
}
@Override
public long getDelay(TimeUnit unit) {
long expirationTime = scheduleTime - System.currentTimeMillis();
return unit.convert(expirationTime, TimeUnit.MILLISECONDS);
}
public void execTask() {
long startTime = System.currentTimeMillis();
System.out.println("Task " + taskName + ": schedule_start_time=" + scheduleTime + ",real start time="
+ startTime + ",delay=" + (startTime - scheduleTime));
try {
Thread.sleep(timeCost);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class DelayTaskComsumer extends Thread {
private final BlockingQueue<DelayTask> queue;
public DelayTaskComsumer(BlockingQueue<DelayTask> queue) {
this.queue = queue;
}
@Override
public void run() {
DelayTask task = null;
try {
while (true) {
task = queue.take();
task.execTask();
DelayTask.taskCount.decrementAndGet();
}
} catch (InterruptedException e) {
System.out.println(getName() + " finished");
}
}
}
public class DelayQueueExample {
public static void main(String[] args) {
BlockingQueue<DelayTask> queue = new DelayQueue<DelayTask>();
for (int i = 0; i < 10; i++) {
try {
queue.put(new DelayTask("work " + i, 2000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
ThreadGroup g = new ThreadGroup("Consumers");
for (int i = 0; i < 1; i++) {
new Thread(g, new DelayTaskComsumer(queue)).start();
}
while (DelayTask.taskCount.get() > 0) {
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
g.interrupt();
System.out.println("Main thread finished");
}
}
首先启动一个消费者线程。因为消费者线程处单个任务的时间为2s,而任务的调度间隔为1~2s。这种情况下,每当消费者线程处理完一个任务,回头再从队列中新取任务时,新任务肯定延期了,无法按给定的时间调度任务。而且越往后情况越严重。运行代码看一下输出:
Task work 0: schedule_start_time=1554203579096,real start time=1554203579100,delay=4
Task work 1: schedule_start_time=1554203580931,real start time=1554203581101,delay=170
Task work 2: schedule_start_time=1554203582884,real start time=1554203583101,delay=217
Task work 3: schedule_start_time=1554203584660,real start time=1554203585101,delay=441
Task work 4: schedule_start_time=1554203586075,real start time=1554203587101,delay=1026
Task work 5: schedule_start_time=1554203587956,real start time=1554203589102,delay=1146
Task work 6: schedule_start_time=1554203589041,real start time=1554203591102,delay=2061
Task work 7: schedule_start_time=1554203590127,real start time=1554203593102,delay=2975
Task work 8: schedule_start_time=1554203591903,real start time=1554203595102,delay=3199
Task work 9: schedule_start_time=1554203593577,real start time=1554203597102,delay=3525
Main thread finished
Thread-0 finished
最后一个任务的延迟时间已经超过3.5s了。
再作一次测试,将消费者线程的个数调整为2,这时任务应该能按时启动,延迟应该很小,运行程序看一下结果:
Task work 0: schedule_start_time=1554204395427,real start time=1554204395430,delay=3
Task work 1: schedule_start_time=1554204396849,real start time=1554204396850,delay=1
Task work 2: schedule_start_time=1554204398050,real start time=1554204398051,delay=1
Task work 3: schedule_start_time=1554204399590,real start time=1554204399590,delay=0
Task work 4: schedule_start_time=1554204401289,real start time=1554204401289,delay=0
Task work 5: schedule_start_time=1554204402883,real start time=1554204402883,delay=0
Task work 6: schedule_start_time=1554204404663,real start time=1554204404664,delay=1
Task work 7: schedule_start_time=1554204406154,real start time=1554204406154,delay=0
Task work 8: schedule_start_time=1554204407991,real start time=1554204407991,delay=0
Task work 9: schedule_start_time=1554204409540,real start time=1554204409540,delay=0
Main thread finished
Thread-0 finished
Thread-2 finished
基本上按时启动,最大延迟为3毫秒,大部分都是0毫秒。
将消费者线程个数调整成3个,运行看一下结果:
Task work 0: schedule_start_time=1554204499695,real start time=1554204499698,delay=3
Task work 1: schedule_start_time=1554204501375,real start time=1554204501376,delay=1
Task work 2: schedule_start_time=1554204503370,real start time=1554204503371,delay=1
Task work 3: schedule_start_time=1554204504860,real start time=1554204504861,delay=1
Task work 4: schedule_start_time=1554204506419,real start time=1554204506420,delay=1
Task work 5: schedule_start_time=1554204508191,real start time=1554204508192,delay=1
Task work 6: schedule_start_time=1554204509495,real start time=1554204509496,delay=1
Task work 7: schedule_start_time=1554204510663,real start time=1554204510664,delay=1
Task work 8: schedule_start_time=1554204512598,real start time=1554204512598,delay=0
Task work 9: schedule_start_time=1554204514276,real start time=1554204514277,delay=1
Main thread finished
Thread-0 finished
Thread-2 finished
Thread-4 finished
大部分延迟时间变成1毫秒,情况好像还不如2个线程的情况。
将消费者线程数调整成5,运行看一下结果:
Task work 0: schedule_start_time=1554204635015,real start time=1554204635019,delay=4
Task work 1: schedule_start_time=1554204636856,real start time=1554204636857,delay=1
Task work 2: schedule_start_time=1554204637968,real start time=1554204637970,delay=2
Task work 3: schedule_start_time=1554204639758,real start time=1554204639759,delay=1
Task work 4: schedule_start_time=1554204641089,real start time=1554204641090,delay=1
Task work 5: schedule_start_time=1554204642879,real start time=1554204642880,delay=1
Task work 6: schedule_start_time=1554204643941,real start time=1554204643942,delay=1
Task work 7: schedule_start_time=1554204645006,real start time=1554204645007,delay=1
Task work 8: schedule_start_time=1554204646309,real start time=1554204646310,delay=1
Task work 9: schedule_start_time=1554204647537,real start time=1554204647538,delay=1
Thread-2 finished
Thread-0 finished
Main thread finished
Thread-8 finished
Thread-4 finished
Thread-6 finished
与3个消费者线程的情况差不多。
# 7. 结论
最优的消费者线程的个数与任务启动的时间间隔好像存在这样的关系:单个任务处理时间的最大值 / 相邻任务的启动时间最小间隔 = 最优线程数,如果最优线程数是小数,则取整数后加1,比如1.3的话,那么最优线程数应该是2。
本例中,单个任务处理时间的最大值固定为2s。 相邻任务的启动时间最小间隔为1s。 则消费者线程数为2/1=2。
如果消费者线程数小于此值,则来不及处理到期的任务。如果大于此值,线程太多,在调度、同步上花更多的时间,无益改善性能。
参考文档:https://blog.csdn.net/dkfajsldfsdfsd/article/details/88966814 (opens new window)
# 十一、BlockingDeque的实现类
# (1). LinkedBlockingDeque
# 1. 概述
LinkedBlockingDeque是双向链表实现的双向并发阻塞队列。该阻塞队列同时支持FIFO和FILO两种操作方式,即可以从队列的头和尾同时操作(插入/删除);并且,该阻塞队列是支持线程安全。还有,LinkedBlockingDeque还是可选容量的(防止过度膨胀),即可以指定队列的容量。如果不指定,默认容量大小等于Integer.MAX_VALUE。
# 2. 源码剖析
# 1. 重要的属性
/**
* 节点类,维护了前一个元素和后一个元素,用来存储数据
*/
static final class Node<E> {
E item;
Node<E> prev;
Node<E> next;
Node(E x) {
item = x;
}
}
/**
* 阻塞队列的第一个元素的节点
*/
transient Node<E> first;
/**
* 阻塞队列的尾节点
*/
transient Node<E> last;
/** 当前阻塞队列中的元素个数 */
private transient int count;
/** 阻塞队列的大小,默认为Integer.MAX_VALUE */
private final int capacity;
/** 所有访问元素时使用的锁 */
final ReentrantLock lock = new ReentrantLock();
/** 等待take的条件对象 */
private final Condition notEmpty = lock.newCondition();
/** 等待put的条件对象 */
private final Condition notFull = lock.newCondition();
由这些属性,我们可以和 LinkedBlockingQueue 进行对比。
首先是Node节点类,不同于 LinkedBlockingQueue 的单向链表,LinkedBlockingDeque 维护的是一个双向链表。
再来看count,这里是用int来进行修饰,而 LinkedBlockingQueue 确实用的AtomicInteger来修饰,这里这么做是因为 LinkedBlockingDeque 内部的每一个操作都共用一把锁,故能保证可见性。而 LinkedBlockingQueue 中维护了两把锁,在添加和移除元素的时候并不能保证双方能够看见count的修改,所以使用CAS来维护可见性。
# 2. 构造函数
public LinkedBlockingDeque() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingDeque(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
}
public LinkedBlockingDeque(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock lock = this.lock;
lock.lock();
try {
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (!linkLast(new Node<E>(e)))
throw new IllegalStateException("Deque full");
}
} finally {
lock.unlock();
}
}
构造函数几乎和 LinkedBlockingQueue 一样,不过少了一句 last = head = new Node(null) 。因为这里不存在head节点了,而用first来代替。并且添加元素的方法也进行了重写来相应 Deque 的方法。
# 3. 入队:add相关的方法
public boolean add(E e) {
addLast(e);
return true;
}
public void addFirst(E e) {
if (!offerFirst(e))
throw new IllegalStateException("Deque full");
}
public void addLast(E e) {
if (!offerLast(e))
throw new IllegalStateException("Deque full");
}
add调用的其实是addLast方法,而addFirst和addLast都调用的offer的相关方法,这里直接看offer的方法。
# 4. 入队:offer相关的方法
public boolean offer(E e) {
return offerLast(e);
}
public boolean offerFirst(E e) {
if (e == null) throw new NullPointerException();
Node<E> node = new Node<E>(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
return linkFirst(node);
} finally {
lock.unlock();
}
}
public boolean offerLast(E e) {
if (e == null) throw new NullPointerException();
Node<E> node = new Node<E>(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
return linkLast(node);
} finally {
lock.unlock();
}
}
很明显,加锁以后调用linkFirst和linkLast这两个方法。
private boolean linkFirst(Node<E> node) {
if (count >= capacity)
return false;
Node<E> f = first;
node.next = f;
first = node;
// 插入第一个元素的时候才需要把last指向该元素,后面所有的操作只需要把f.prev指向node
if (last == null)
last = node;
else
f.prev = node;
++count;
notEmpty.signal();
return true;
}
private boolean linkLast(Node<E> node) {
if (count >= capacity)
return false;
Node<E> l = last;
node.prev = l;
last = node;
if (first == null)
first = node;
else
l.next = node;
++count;
notEmpty.signal();
return true;
}
下面给出两张图,都是队列为空的情况下,调用linkFirst和linkLast依次放入元素A和元素B的图:
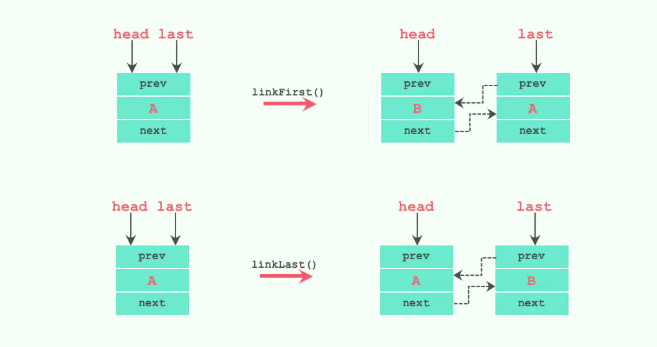
offer的超时方法这里就不放出了,原理和 LinkedBlockingQueue 一样,利用了Condition的awaitNanos进行超时等待,并在外面用while循环控制等待时的中断问题。
# 5. 入队:put相关的方法
public void put(E e) throws InterruptedException {
putLast(e);
}
public void putFirst(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
Node<E> node = new Node<E>(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 阻塞等待linkFirst成功
while (!linkFirst(node))
notFull.await();
} finally {
lock.unlock();
}
}
public void putLast(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
Node<E> node = new Node<E>(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 阻塞等待linkLast成功
while (!linkLast(node))
notFull.await();
} finally {
lock.unlock();
}
}
lock加锁后一直阻塞等待,直到元素插入到队列中。
# 6. 出队:remove相关的方法
public E remove() {
return removeFirst();
}
public E removeFirst() {
E x = pollFirst();
if (x == null) throw new NoSuchElementException();
return x;
}
public E removeLast() {
E x = pollLast();
if (x == null) throw new NoSuchElementException();
return x;
}
remove方法调用了poll的相关方法。
# 7. 出队:poll相关的方法
public E poll() {
return pollFirst();
}
public E pollFirst() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return unlinkFirst();
} finally {
lock.unlock();
}
}
public E pollLast() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return unlinkLast();
} finally {
lock.unlock();
}
}
poll方法用lock加锁后分别调用了unlinkFirst和unlinkLast方法
private E unlinkFirst() {
Node<E> f = first;
if (f == null)
return null;
Node<E> n = f.next;
E item = f.item;
f.item = null;
f.next = f; // help GC
// first指向下一个节点
first = n;
if (n == null)
last = null;
else
n.prev = null;
--count;
notFull.signal();
return item;
}
private E unlinkLast() {
Node<E> l = last;
if (l == null)
return null;
Node<E> p = l.prev;
E item = l.item;
l.item = null;
l.prev = l; // help GC
// last指向下一个节点
last = p;
if (p == null)
first = null;
else
p.next = null;
--count;
notFull.signal();
return item;
}
poll的超时方法也是利用了Condition的awaitNanos来做超时等待。这里就不做过多说明了。
# 8. 出队:take相关的方法
public E take() throws InterruptedException {
return takeFirst();
}
public E takeFirst() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
E x;
while ( (x = unlinkFirst()) == null)
notEmpty.await();
return x;
} finally {
lock.unlock();
}
}
public E takeLast() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
E x;
while ( (x = unlinkLast()) == null)
notEmpty.await();
return x;
} finally {
lock.unlock();
}
}
还是一个套路,lock加锁,while循环重试移除,await阻塞等待。
# 9. 获取元素方法
public E element() {
return getFirst();
}
public E peek() {
return peekFirst();
}
public E getFirst() {
E x = peekFirst();
if (x == null) throw new NoSuchElementException();
return x;
}
public E getLast() {
E x = peekLast();
if (x == null) throw new NoSuchElementException();
return x;
}
public E peekFirst() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return (first == null) ? null : first.item;
} finally {
lock.unlock();
}
}
public E peekLast() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return (last == null) ? null : last.item;
} finally {
lock.unlock();
}
}
获取元素前加锁,防止并发问题导致数据不一致。利用first和last节点直接可以获得元素。
# 10. 删除元素方法
public boolean remove(Object o) {
return removeFirstOccurrence(o);
}
public boolean removeFirstOccurrence(Object o) {
if (o == null) return false;
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 从first向后开始遍历比较,找到元素后调用unlink移除
for (Node<E> p = first; p != null; p = p.next) {
if (o.equals(p.item)) {
unlink(p);
return true;
}
}
return false;
} finally {
lock.unlock();
}
}
public boolean removeLastOccurrence(Object o) {
if (o == null) return false;
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 从last向前开始遍历比较,找到元素后调用unlink移除
for (Node<E> p = last; p != null; p = p.prev) {
if (o.equals(p.item)) {
unlink(p);
return true;
}
}
return false;
} finally {
lock.unlock();
}
}
void unlink(Node<E> x) {
Node<E> p = x.prev;
Node<E> n = x.next;
if (p == null) {
unlinkFirst();
} else if (n == null) {
unlinkLast();
} else {
p.next = n;
n.prev = p;
x.item = null;
// Don't mess with x's links. They may still be in use by
// an iterator.
--count;
notFull.signal();
}
}
删除元素是从头/尾向两边进行遍历比较,故时间复杂度为O(n),最后调用unlink把要移除元素的prev和next进行关联,把要移除的元素从链中脱离,等待下次GC回收。
# 3. 总结
LinkedBlockingDeque和LinkedBlockingQueue的相同点在于:
- 基于链表
- 通过ReentrantLock实现锁
- 利用Condition实现队列的阻塞等待,唤醒
- 容量可选,不设置的话,就是Int的最大值
LinkedBlockingDeque和LinkedBlockingQueue的不同点在于:
LinkedBlockingQueue只能一端出一端如的单向队列结构,是有FIFO特性的,并且是通过两个ReentrantLock和两个Condition来实现的
LinkedBlockingQueue采用了两把锁来对队列进行操作,也就是队尾添加的时候,队头仍然可以删除等操作
对于LinkedBlockingQueue来说,有两个ReentrantLock分别控制队头和队尾,这样就可以使得添加操作分开来做,一般的操作是获取一把锁就可以,但有些操作例如remove操作,则需要同时获取两把锁
LinkedBlockingDeque就是一个双端队列,任何一端都可以进行元素的出入
LinkedBlockingDeque 和 ArrayBlockingQueue 结构还是很类似的,也是一个ReentrantLock和两个Condition使用,但是仅仅是在这二者使用上,其实内部运转还是很大不同的
参考文档:
https://blog.csdn.net/qq_38293564/article/details/80592429 (opens new window)
https://www.jianshu.com/p/91d9f434da91 (opens new window)
# 十二、Queue的实现类
# (1). PriorityQueue
# 1. 概述
PriorityQueue 一个基于优先级的无界队列。优先级队列的元素按照其自然顺序进行排序,或者根据构造队列时提供的 Comparator 进行排序,具体取决于所使用的构造方法。该队列不允许使用 null 元素也不允许插入不可比较的对象(没有实现Comparable接口的对象)。PriorityQueue 队列的头指排序规则最小那个元素。如果多个元素都是最小值则随机选一个。PriorityQueue 是一个无界队列,但是初始的容量11(实际是一个Object[]),随着不断向优先级队列添加元素,其容量会自动扩容。
# 2. 基本使用
PriorityQueue使用跟普通队列一样,唯一区别是PriorityQueue会根据排序规则决定谁在队头,谁在队尾。
往队列中添加可比较的对象String
public class PriorityQueueTest {
public static void main(String[] args) {
PriorityQueue<String> q = new PriorityQueue<String>();
//入列
q.offer("1");
q.offer("2");
q.offer("5");
q.offer("3");
q.offer("4");
//出列
System.out.println(q.poll()); //1
System.out.println(q.poll()); //2
System.out.println(q.poll()); //3
System.out.println(q.poll()); //4
System.out.println(q.poll()); //5
}
}
观察打印结果, 入列:12534, 出列是12345, 也是说出列时做了相关判断,将最小的值返回。默认情况下PriorityQueue使用自然排序法,最小元素先出列。
自定义排序规则
public class Student {
private String name; //名字
private int score; //分数
public Student(String name, int score) {
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", score=" + score +
'}';
}
}
public class PriorityQueueTest1 {
public static void main(String[] args) {
//通过改造器指定排序规则
PriorityQueue<Student> q = new PriorityQueue<Student>(new Comparator<Student>() {
public int compare(Student o1, Student o2) {
//按照分数低到高,分数相等按名字
if(o1.getScore() == o2.getScore()){
return o1.getName().compareTo(o2.getName());
}
return o1.getScore() - o2.getScore();
}
});
//入列
q.offer(new Student("dafei", 20));
q.offer(new Student("will", 17));
q.offer(new Student("setf", 30));
q.offer(new Student("bunny", 20));
//出列
System.out.println(q.poll()); //Student{name='will', score=17}
System.out.println(q.poll()); //Student{name='bunny', score=20}
System.out.println(q.poll()); //Student{name='dafei', score=20}
System.out.println(q.poll()); //Student{name='setf', score=30}
}
}
PriorityQueue优先级规则可以由我们根据具体需求而定制, 方式有2种:
- 添加元素自身实现了Comparable接口,确保元素是可排序的对象
- 如果添加元素没有实现Comparable接口,可以在创建PriorityQueue队列时直接指定比较器。
# 3. 源码剖析
# 1. 重要属性
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
transient Object[] queue; //队列容器, 默认是11
private int size = 0; //队列长度
private final Comparator<? super E> comparator; //队列比较器, 为null使用自然排序
//....
}
# 2. 入列
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1); //当队列长度大于等于容量值时,自动拓展
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e); //
return true;
}
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x); //指定比较器
else
siftUpComparable(k, x); //没有指定比较器,使用默认的自然比较器
}
# 3. 使用默认的自然比较器
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
# 4. 使用指定的比较器
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
从源码上看PriorityQueue的入列操作并没对所有加入的元素进行优先级排序。仅仅保证数组第一个元素是最小的即可。
# 5. 出列
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
return result;
}
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x); //指定比较器
else
siftDownComparable(k, x); //默认比较器
}
# 6. 使用默认的自然比较器
private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}
# 7. 使用指定的比较器
private void siftDownUsingComparator(int k, E x) {
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = x;
}
上面源码,当第一个元素出列之后,对剩下的元素进行再排序,挑选出最小的元素排在数组第一个位置。
通过上面源码,也可看出PriorityQueue并不是线程安全队列,因为offer/poll都没有对队列进行锁定,所以,如果要拥有线程安全的优先级队列,需要额外进行加锁操作。
# 4. 总结
- PriorityQueue是一种无界的,线程不安全的队列
- PriorityQueue是一种通过数组实现的,并拥有优先级的队列
- PriorityQueue存储的元素要求必须是可比较的对象, 如果不是就必须明确指定比较器
参考文档:https://www.jianshu.com/p/f1fd9b82cb72 (opens new window)
# (2). ConcurrentLinkedQueue
# 1. 概述
ConcurrentLinkedQueue是单向链表结构的无界并发队列。从JDK1.7开始加入到JUC的行列中。使用CAS实现并发安全,元素操作按照 FIFO (first-in-first-out 先入先出) 的顺序。适合“单生产,多消费”的场景。内存一致性遵循对ConcurrentLinkedQueue的插入操作先行发生于(happen-before)访问或移除操作。
ConcurrentLinkedQueue的非阻塞算法实现可概括为下面四点(后面源码解析中都会有详细说明):
- 使用 CAS 原子指令来处理对数据的并发访问,这是非阻塞算法得以实现的基础。
- head/tail 节点都允许滞后,也就是说它们并非总是指向队列的头/尾节点,这是因为并不是每次操作队列都更新 head/tail,和 LinkedTransferQueue 一样,使用了一个“松弛阀值(2)”, 当前指针距离 head/tail 节点大于2时才会更新 head/tail,这也是一种优化方式,减少了CAS指令的执行次数。
- 由于队列有时会处于不一致状态。为此,ConcurrentLinkedQueue 对节点使用了“不变性”和“可变性”来约束非阻塞算法的正确性(后面会详细说明)。
- 使用“自链接”方式管理出队节点,这样一个自链接节点意味着需要从head向后推进。
# 2. 源码剖析
# 1. Node类型
ConcurrentLinkedQueue 继承了AbstractQueue,使用Node存储数据,Node是一个单向链表,内部存储元素和下一个节点的引用。
private static class Node<E> {
volatile E item;
volatile Node<E> next;
Node(E item) {
UNSAFE.putObject(this, itemOffset, item);
}
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
# 2. 构造方法
// 默认构造方法,head节点存储的元素为空,tail节点等于head节点
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
// 根据其他集合来创建队列
public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
// 遍历节点
for (E e : c) {
// 若节点为null,则直接抛出NullPointerException异常
checkNotNull(e);
Node<E> newNode = new Node<E>(e);
if (h == null)
h = t = newNode;
else {
t.lazySetNext(newNode);
t = newNode;
}
}
if (h == null)
h = t = new Node<E>(null);
head = h;
tail = t;
}
private transient volatile Node<E> head;
private transient volatile Node<E> tail;
默认情况下head节点存储的元素为空,tail节点等于head节点。
head = tail = new Node<E>(null);
首先来看一下上面提到的节点的“不变性”和“可变性”,在ConcurrentLinkedQueue中,通过这些性质来约束非阻塞算法的正确性。
基本不变性:
- 当入队插入新节点之后,队列中有一个 next 域为 null (最后一个)的节点。
- 从 head 开始遍历队列,可以访问所有 item 域不为 null 的节点。
head / tail 的不变性
- 所有live节点(指未删除节点),都能从 head 通过调用 succ() 方法遍历可达
- 通过 tail 调用 succ() 方法,最后节点总是可达的
- head 节点的 next 域不能引用到自身
- head / tail 不能为 null
head / tail 的可变性:
- head / tail 节点的 item 域可能为 null,也可能不为 null
- 允许 tail 滞后(lag behind)于 head。也就是说,从 head 开始遍历队列,不一定能到达 tail
- tail 节点的 next 域可以引用到自身
# 3. 入队操作
入队列就是将入队节点添加到队列的尾部。为了方便理解入队时队列的变化,以及head节点和tail节点的变化,每添加一个节点我就做了一个队列的快照图:
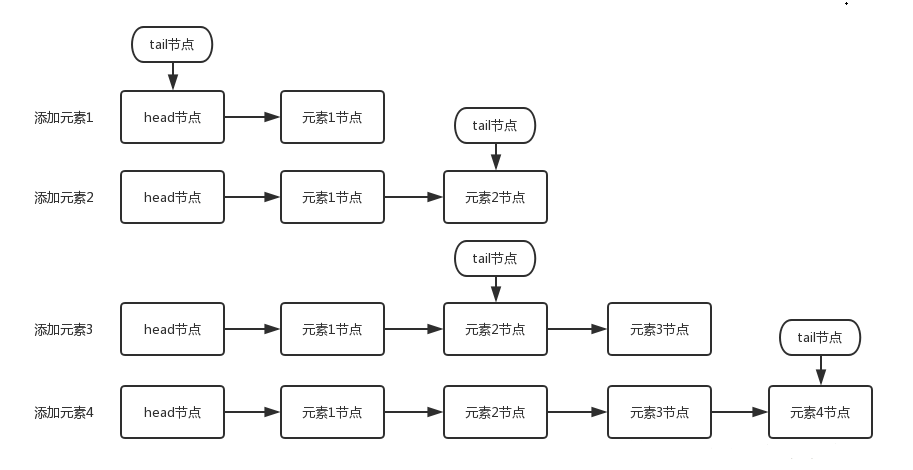
上图所示的元素添加过程如下:
- 添加元素1:队列更新head节点的next节点为元素1节点。又因为tail节点默认情况下等于head节点,所以它们的next节点都指向元素1节点。
- 添加元素2:队列首先设置元素1节点的next节点为元素2节点,然后更新tail节点指向元素2节点。
- 添加元素3:设置元素2节点的next节点为元素3节点(也就意味着tail节点的next节点也是元素3节点)。
- 添加元素4:设置元素3的next节点为元素4节点,然后将tail节点指向元素4节点。
入队操作主要做两件事情,第一是将入队节点设置成当前队列尾节点的下一个节点。第二是更新tail节点,如果tail节点的next节点不为空,则将入队节点设置成tail节点,如果tail节点的next节点为空,则将入队节点设置成tail的next节点,所以tail节点不总是尾节点,理解这一点很重要。
上面的分析让我们从单线程入队的角度来理解入队过程,但是多个线程同时进行入队情况就变得更加复杂,因为可能会出现其他线程插队的情况。如果有一个线程正在入队,那么它必须先获取尾节点,然后设置尾节点的下一个节点为入队节点,但这时可能有另外一个线程插队了,那么队列的尾节点就会发生变化,这时当前线程要暂停入队操作,然后重新获取尾节点。
# 4. 入队方法
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
// 如果e为null,则直接抛出NullPointerException异常
checkNotNull(e);
// 创建入队节点
final Node<E> newNode = new Node<E>(e);
// 循环CAS直到入队成功
// 1、根据tail节点定位出尾节点(last node);2、将新节点置为尾节点的下一个节点;3、cas Tail更新尾节点
for (Node<E> t = tail, p = t;;) {
// p用来表示队列的尾节点,初始情况下等于tail节点
// q是p的next节点
Node<E> q = p.next;
// 判断p是不是尾节点,tail节点不一定是尾节点,判断是不是尾节点的依据是该节点的next是不是null
// 如果p是尾节点
if (q == null) {
// p is last node
// 设置p节点的下一个节点为新节点,设置成功则casNext返回true;否则返回false,说明有其他线程更新过尾节点
if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
// 如果p != t,则将入队节点设置成tail节点,更新失败了也没关系,因为失败了表示有其他线程成功更新了tail节点
if (p != t) // 跳两个节点以上时才修改tail
casTail(t, newNode); // cas替换尾节点
return true;
}
// Lost CAS race to another thread; re-read next
}
// 多线程操作时候,由于poll时候会把旧的head变为自引用,然后将head的next设置为新的head
// 所以这里需要重新找新的head,因为新的head后面的节点才是激活的节点
else if (p == q)
// p节点指向自身,说明p是一个自链节点,此时需要重新获取tail节点,
// 如果tail节点被其他线程修改,此时需要从head开始向后遍历,因为
// 从head可以到达所有的live节点。
p = (t != (t = tail)) ? t : head;
// 寻找尾节点
else
//继续向后查找,如果tail节点变化,重新获取tail
p = (p != t && t != (t = tail)) ? t : q;
}
}
从源代码角度来看整个入队过程主要做两件事情:
- 第一是定位出尾节点
- 第二是使用 CAS 算法能将入队节点设置成尾节点的next节点,如不成功则重试。
第一步定位尾节点。tail节点并不总是尾节点,所以每次入队都必须先通过tail节点来找到尾节点,尾节点可能就是tail节点,也可能是tail节点的next节点。代码中循环体中的第一个if就是判断tail是否有next节点,有则表示next节点可能是尾节点。获取tail节点的next节点需要注意的是p节点等于q节点的情况,出现这种情况的原因我们后续再来介绍。 第二步设置入队节点为尾节点。p.casNext(null, newNode)方法用于将入队节点设置为当前队列尾节点的next节点,q如果是null表示p是当前队列的尾节点,如果不为null表示有其他线程更新了尾节点,则需要重新获取当前队列的尾节点。
# 5. tail节点不一定为尾节点的设计意图
对于先进先出的队列入队所要做的事情就是将入队节点设置成尾节点,作者写的代码和逻辑还是稍微有点复杂。那么我用以下方式来实现行不行?
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (;;) {
Node<E> t = tail;
if (t.casNext(null ,newNode) && casTail(t, newNode)) {
return true;
}
}
}
让 tail 节点永远作为队列的尾节点,这样实现代码量非常少,而且逻辑非常清楚和易懂。但是这么做有个缺点就是每次都需要使用循环 CAS 更新 tail 节点。如果能减少 CAS 更新 tail 节点的次数,就能提高入队的效率。
在JDK 1.7的实现中,作者使用hops变量来控制并减少 tail 节点的更新频率,并不是每次节点入队后都将 tail 节点更新成尾节点,而是当tail节点和尾节点的距离大于等于常量 HOPS 的值(默认等于1)时才更新 tail 节点,tail 和尾节点的距离越长使用 CAS 更新 tail 节点的次数就会越少,但是距离越长带来的负面效果就是每次入队时定位尾节点的时间就越长,因为循环体需要多循环一次来定位出尾节点,但是这样仍然能提高入队的效率,因为从本质上来看它通过增加对 volatile变量的读操作来减少了对 volatile 变量的写操作,而对 volatile 变量的写操作开销要远远大于读操作,所以入队效率会有所提升。
在JDK 1.8的实现中,tail 的更新时机是通过p和t是否相等来判断的,其实现结果和JDK 1.7相同,即当tail节点和尾节点的距离大于等于1时,更新tail。
# 6. 入队操作整体逻辑如下图所示:
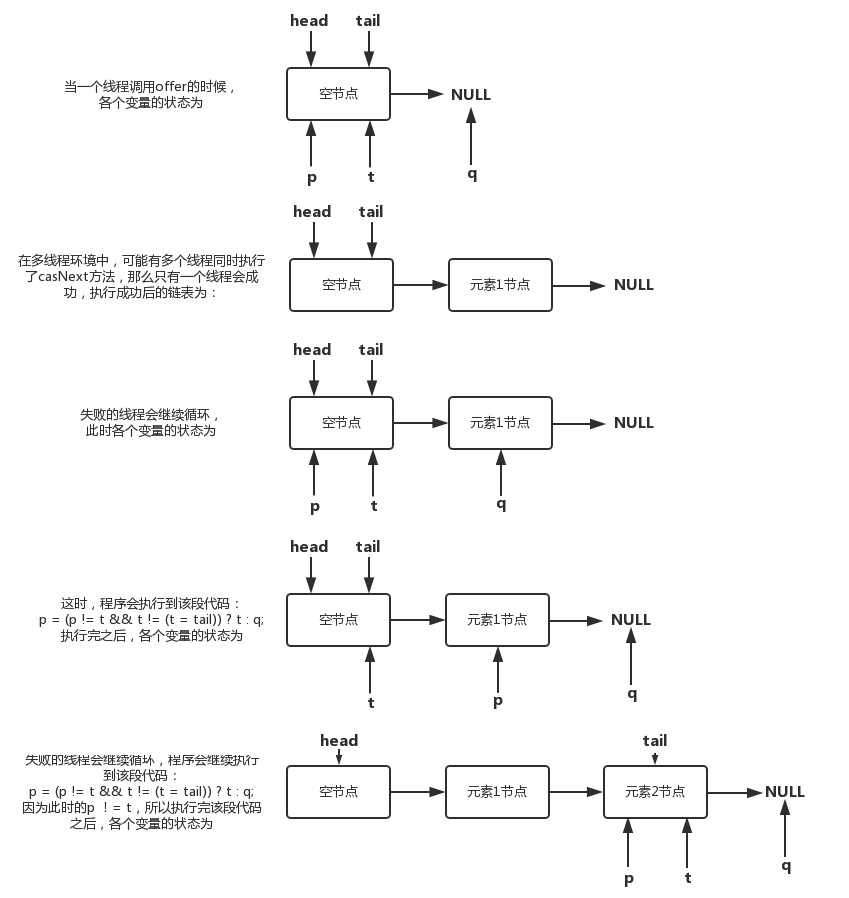
# 7. 出队操作
出队列的就是从队列里返回一个节点元素,并清空该节点对元素的引用。让我们通过每个节点出队的快照来观察下head节点的变化:
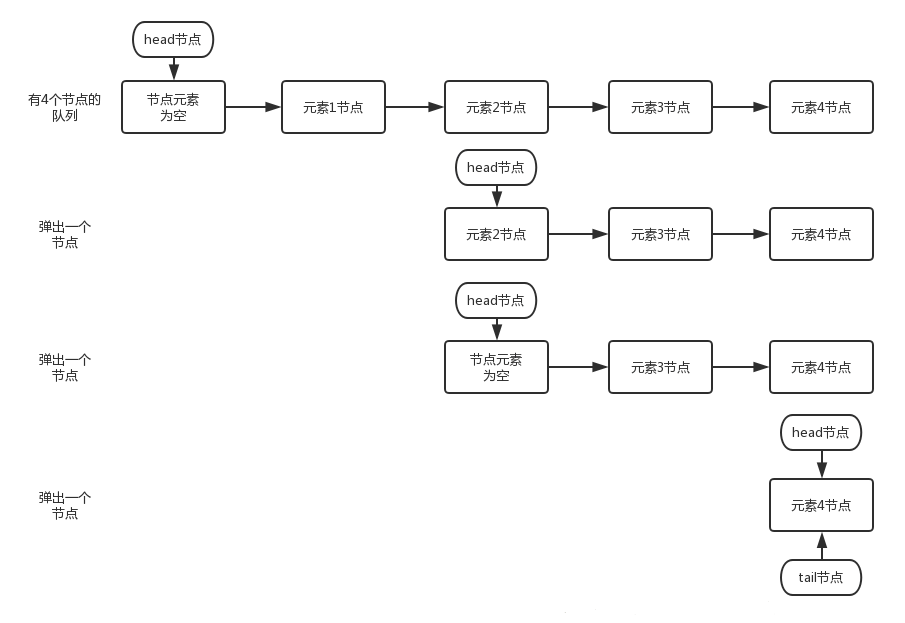
从上图可知,并不是每次出队时都更新 head 节点,当 head 节点里有元素时,直接弹出head节点里的元素,而不会更新head 节点。只有当head节点里没有元素时,出队操作才会更新head节点。采用这种方式也是为了减少使用 CAS 更新head 节点的消耗,从而提高出队效率。让我们再通过源码来深入分析下出队过程。
# 8. 出队方法
public E poll() {
restartFromHead:
for (;;) {
// p节点表示首节点,即需要出队的节点
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// 如果p节点的元素不为null,则通过CAS来设置p节点引用的元素为null,如果成功则返回p节点的元素
if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point
// for item to be removed from this queue.
// 如果p != h,则更新head
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
// 如果头节点的元素为空或头节点发生了变化,这说明头节点已经被另外一个线程修改了。
// 那么获取p节点的下一个节点,如果p节点的下一节点为null,则表明队列已经空了
else if ((q = p.next) == null) {
// 更新头结点
updateHead(h, p);
return null;
}
// p == q,则使用新的head重新开始
else if (p == q)
continue restartFromHead;
// 如果下一个元素不为空,则将头节点的下一个节点设置成头节点
else
p = q;
}
}
}
该方法的主要逻辑就是首先获取头节点的元素,然后判断头节点元素是否为空,如果为空,表示另外一个线程已经进行了一次出队操作将该节点的元素取走,如果不为空,则使用CAS的方式将头节点的引用设置成null,如果CAS成功,则直接返回头节点的元素,如果不成功,表示另外一个线程已经进行了一次出队操作更新了head节点,导致元素发生了变化,需要重新获取头节点。
在入队和出队操作中,都有p == q的情况,那这种情况是怎么出现的呢?我们来看这样一种操作:
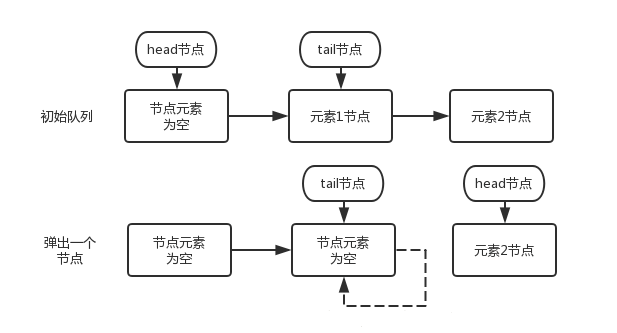
在弹出一个节点之后,tai l节点有一条指向自己的虚线,这是什么意思呢?我们来看poll()方法,在该方法中,移除元素之后,会调用updateHead方法:
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
// 将旧的头结点h的next域指向为h
h.lazySetNext(h);
}
我们可以看到,在更新完head之后,会将旧的头结点h的next域指向为h,上图中所示的虚线也就表示这个节点的自引用。
如果这时,再有一个线程来添加元素,通过tail获取的next节点则仍然是它本身,这就出现了p == q的情况,出现该种情况之后,则会触发执行head的更新,将p节点重新指向为head,所有“活着”的节点(指未删除节点),都能从head通过遍历可达,这样就能通过head成功获取到尾节点,然后添加元素了。
# 9. peek()方法
// 获取链表的首部元素(只读取而不移除)
public E peek() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null || (q = p.next) == null) {
updateHead(h, p);
return item;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
从源码中可以看到,peek操作会改变head指向,执行peek()方法后head会指向第一个具有非空元素的节点。
# 10. size()方法
public int size() {
int count = 0;
// first()获取第一个具有非空元素的节点,若不存在,返回null
// succ(p)方法获取p的后继节点,若p == p的后继节点,则返回head
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
// Collection.size() spec says to max out
// 最大返回Integer.MAX_VALUE
if (++count == Integer.MAX_VALUE)
break;
return count;
}
size()方法用来获取当前队列的元素个数,但在并发环境中,其结果可能不精确,因为整个过程都没有加锁,所以从调用size方法到返回结果期间有可能增删元素,导致统计的元素个数不精确。
# 11. remove(Object o)方法
public boolean remove(Object o) {
// 删除的元素不能为null
if (o != null) {
Node<E> next, pred = null;
for (Node<E> p = first(); p != null; pred = p, p = next) {
boolean removed = false;
E item = p.item;
// 节点元素不为null
if (item != null) {
// 若不匹配,则获取next节点继续匹配
if (!o.equals(item)) {
next = succ(p);
continue;
}
// 若匹配,则通过CAS操作将对应节点元素置为null
removed = p.casItem(item, null);
}
// 获取删除节点的后继节点
next = succ(p);
// 将被删除的节点移除队列
if (pred != null && next != null) // unlink
pred.casNext(p, next);
if (removed)
return true;
}
}
return false;
}
# 12. contains(Object o)方法
public boolean contains(Object o) {
if (o == null) return false;
// 遍历队列
for (Node<E> p = first(); p != null; p = succ(p)) {
E item = p.item;
// 若找到匹配节点,则返回true
if (item != null && o.equals(item))
return true;
}
return false;
}
该方法和size方法类似,有可能返回错误结果,比如调用该方法时,元素还在队列里面,但是遍历过程中,该元素被删除了,那么就会返回false。
# 3. 总结
ConcurrentLinkedQueue 的非阻塞算法实现可概括为下面 5 点:
- 使用 CAS 原子指令来处理对数据的并发访问,这是非阻塞算法得以实现的基础。
- head/tail 并非总是指向队列的头 / 尾节点,也就是说允许队列处于不一致状态。 这个特性把入队 / 出队时,原本需要一起原子化执行的两个步骤分离开来,从而缩小了入队 / 出队时需要原子化更新值的范围到唯一变量。这是非阻塞算法得以实现的关键。
- 由于队列有时会处于不一致状态。为此,ConcurrentLinkedQueue 使用**三个不变式(p,t,q)**来维护非阻塞算法的正确性。
- 以批处理方式来更新 head/tail,从整体上减少入队 / 出队操作的开销。
- 为了有利于垃圾收集,队列使用特有的 head 更新机制;为了确保从已删除节点向后遍历,可到达所有的非删除节点,队列使用了特有的向后推进策略。
参考地址:
https://blog.csdn.net/qq_38293564/article/details/80798310 (opens new window)
https://www.jianshu.com/p/0c5a672b2ade (opens new window)
# 十三、Deque的实现类
# (1). ArrayDeque
# 1. 概述
ArrayDeque 是 Deque 接口的一种具体实现,是依赖于可变数组来实现的。ArrayDeque 没有容量限制,可根据需求自动进行扩容。ArrayDeque 可以作为栈来使用,效率要高于 Stack;ArrayDeque 也可以作为队列来使用,效率相较于基于双向链表的 LinkedList 也要更好一些。注意,ArrayDeque 不支持为 null 的元素。非线程安全
# 2. 循环数组
Java中一般只有两种基础的数据容器,数组或链表。数组排列紧密、下标查找快、中间插入慢;链表排列稀疏、查找慢,中间插入快。对于栈结构来说,采用数组更具优势,ArrayDeque也是采用了数组来作为基本数据容器,也需要处理数组扩容问题。
不过,传统的数组都是线性数组,向尾部添加数据固然很方便,但是向中间添加数据的话,就需要挪动插入点之后的所有数据,如果向头部添加数据的话,整个数组都要挪一遍,虽然Java提供了Native函数System.arrayCopy来提升效率,但是对内存的操作是不可避免的。
为了提高效率,ArrayDeque采用了循环数组的设计,也就是说虽然基础容器是一个普通的数组(默认容量16),但是在逻辑上,这个数组没有固定的开头或结尾,既可以直接向尾部添加数据,也可以直接向头部之前添加数据,不需要大面积地移动数据。逻辑上的概念大概是这样的:
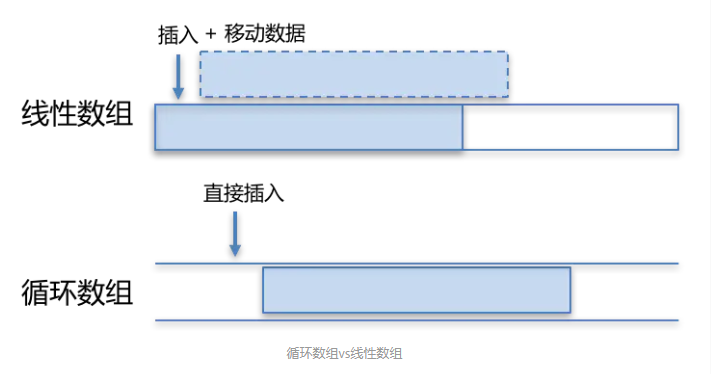
# 1. 具体实现及优化
循环数组在概念上没有左右边界,但是Java并没有这样的数组,Java只能提供固定大小的数组,这样的话,如何实现循环数组就转变为如何利用固定数组实现循环数组。相对于线性数组,循环数组是连续的,但是数组的头和尾可能在任何位置,所以循环数组在真实数据中的映射大概是这样:

在逻辑上,队首总是在左边,队尾总是在右边,但是如果持续向队首插入数据,就很容易把队首“挤”出物理容器的左边界,“挤”进物理容器的右侧。这时候,我们可以看到,循环数组在物理数组中最大的问题是,很多时候,逻辑上连续,但物理上被分成了两截。所以,ArrayDeque需要针对以下操作,做特殊处理:
# 2. 添加/删除头
主要判断头的新位置在左侧还是右侧。先看添加:head的新位置一定是head-1,如果得到的结果为-1,就需要挪到右侧,也就是物理数组中的最后一个位置length-1。如果让我们自己来写,可能是这样写:
if(head - 1 < 0){
head = elements.length - 1;
}else{
head = head - 1;
}
elements[head] = e;
事实上,ArrayDeque使用了更精妙的实现,他用一步位与运算实现了这个功能:
elements[head = (head - 1) & (elements.length - 1)] = e;
这行代码具体什么意思呢? 当head-1为-1时,实际上是11111111&00001111,结果是00001111,也就是物理数组的尾部15; 当head-1为较小的值如3时,实际上是00000011&00001111,结果是00000011,还是3。 当head增长如head+1超过物理数组长度如16时,实际上是00010000&00001111,结果是00000000,也就是0,这样就回到了物理数组的头部。 所以,位与运算可以很轻松地实现把数据控制在某个范围内。 回过头来,我们再看删除头的代码:
elements[h] = null; // Must null out slot
head = (h + 1) & (elements.length - 1);
先清空数据,然后移动head位置,也是用位与运算实现的。 位运算本来就非常高效,ArrayDeque的这种写法,更是用一行代码覆盖了函数中的所有场景,非常精妙。
# 3. 添加/删除尾
主要判断尾的新位置在左侧还是右侧,具体操作和上一步添加/删除头类似。
# 4. 删除中间某个数据
删除中间元素时,即使是循环数组,也需要批量移动数组元素了,所以删除中间元素实际上面临三个问题,一是需要在左侧或右侧删除,二是需要挪动头或尾,三是优化需要,尽量少得移动数组元素。 ArrayDeque实际上是先从第三个问题入手的,先判断中间元素里head近还是离tail近,然后移动较近的那一端。不过,较近的一端只是逻辑上较近,物理数组上,可能被分成了两截,这就需要做两次数组元素的批量移动。
//ArrayDeque源码(部分情况)
System.arraycopy(elements, 0, elements, 1, i);
elements[0] = elements[mask];
System.arraycopy(elements, h, elements, h + 1, mask - h);
# 5. 计算队列长度,如果物理上不连续,需要特别计算真正的数据
如果让我们自己写,可能也是分条件判断,分别计算两截的数据。 ArrayDeque又使用了位与运算:
return (tail - head) & (elements.length - 1);
也是只有一行,当物理上被分为两截时,tail-head会是负数,整个操作相当于取模运算,例如,当tail为3,head为14,物理数组长度16时,运算的就是11110101&00001111,值为00000101,也就是5。
# 6. 复制一个线性数组toArray
从基本操作上,如果物理上不连续,先复制右侧,再补上左侧。toArray的问题在于新数组的长度是动态的,为了生成大小刚好的新数组,ArrayDeque使用了Arrays工具类来实现这个特定长度的数组,并同时实现对head一侧数据的复制:
boolean wrap = (tail < head);
int end = wrap ? tail + elements.length : tail;
Object[] a = Arrays.copyOfRange(elements, head, end);
if (wrap)
System.arraycopy(elements, 0, a, elements.length - head, tail);
这样的话,如果物理空间连续,就直接复制完成;但如果物理空间不连续,第一次Arrays.copyOfRange需要保证一次性生成足够的物理空间,所以end的值不能是length(否则长度就只有length-head这么长),而应该是tail+length。
# 7. 空间扩容
数据容器的扩容其实可以分解为两个问题,一是何时开始扩容,二是旧数组数据的复制。
对于何时开始扩容的问题,为了减少检查的次数,ArrayDeque采用了对 head 和 tail 是否重合的检查,只要 tail 和 head 不重合,就说明 tail 后面 head 前面还有空间,所以只要在添加头/尾时检查head==tail即可。
对于旧数组数据的复制,空间扩容和问题和toArray有些类似,不同的是新数组的长度是可知的(2倍),所以可以直接new一个定长的数组,这样就不需要Array.copyOfRange函数,可以统一使用System.arrayCopy:
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
相比ArrayList,我们可以看到ArrayDeque大量减少了System.arrayCopy的使用,只在delete、clone、扩容和 toArray 函数中使用了这个函数,其他操作中都不需要大量移动数组元素,这也可以说明 ArrayDeque 这个数据集合的性能非常优良。
# 3. 实现思路
我先来总结下ArrayDeque的实现思路。
首先,ArrayDeque内部是拥有一个内部数组用于存储数据。其次,假设采用简单的方案,即队列数组按顺序在数组里排开,那么:
- 由于ArrayDeque的两端都能增删数据,那么把数据插入到队列头部也就是数组头部,会造成O(N)的时间复杂度。
- 假设只再队尾加入而只从队头删除,队头就会空出越来越多的空间。
那么该怎么实现?也很简单。将物理上的连续数组回绕,形成逻辑上的一个 环形结构。即a[size - 1]的下一个位置是a[0]. 之后,使用头尾指针标识队列头尾,在队列头尾增删元素,反映在头尾指针上就是这两个指针绕着环赛跑。
这个是大体思路,具体的还有一些细节,后面代码里分析:
- head和tail的具体概念是如何界定?
- 如果判断队满和队空?
- 数组满了怎么办?
# 4. 源码剖析
# 1. 重要的属性
//数据存放数组,默认初始容量为16,每次扩容都是容量翻倍
transient Object[] elements;
//头部元素下标
transient int head;
//尾部元素下标
transient int tail;
# 2. 构造函数
public ArrayDeque() {
elements = new Object[16]; // 默认的数组长度大小
}
public ArrayDeque(int numElements) {
allocateElements(numElements);// 需要的数组长度大小
}
private void allocateElements(int numElements) {
elements = new Object[calculateSize(numElements)];
}
- 如果没有指定内部数组的初始大小,默认为16。
- 如果指定了内部数组的初始大小,则通过
calculateSize函数二次计算出大小。
# 3. calculateSize函数
private static final int MIN_INITIAL_CAPACITY = 8;
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// 找到大于需要长度的最小的2的幂整数。
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
return initialCapacity;
}
- 如果小于8,那么大小就为8。
- 如果大于等于8,则按照2的幂对齐。
# 4. 入队
public boolean offer(E e) {
return offerLast(e);
}
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
public boolean offerLast(E e) {
addLast(e);
return true;
}
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
addFirst是从队头插入,addLast是从队尾插入。
从该代码能够分析出head和tail指针的含义:
- head 指针指向的是队头元素的位置,除非队列为空。
- tail 指针指向的是队尾元素后一格的位置,即尾后指针。
因此:
- 如果队列没有满,tail 指向的是空位置,head 指向的是队头元素,永远不可能一样。
- 但是当队列满时,tail 回绕会追上 head,当 tail 等于 head 时,表示队列满了。
理清楚了这一点,上面的代码也就十分容易理解了:
- 对应位置插入位置,移动指针。
- 当 tail 和 head 相等时,扩容。
最后,这句:
(head - 1) & (elements.length - 1)
假如被余数是2的幂次方,那么模运算就能够优化成按位与运算。也即相当于:
(head - 1) % elements.length
# 5. 出队
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
elements[h] = null; // Must null out slot
head = (h + 1) & (elements.length - 1);
return result;
}
public E pollLast() {
int t = (tail - 1) & (elements.length - 1);
@SuppressWarnings("unchecked")
E result = (E) elements[t];
if (result == null)
return null;
elements[t] = null;
tail = t;
return result;
}
# 6. 扩容
// 扩容为原来的2倍。
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
// 扩容后的大小小于0(溢出),也即队列最大应该是2的30次方
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
// 既然是head和tail已经重合了,说明tail是在head的左边。
System.arraycopy(elements, p, a, 0, r); // 拷贝原数组从head位置到结束的数据
System.arraycopy(elements, 0, a, r, p); // 拷贝原数组从开始到head的数据
elements = a;
head = 0;// 重置head和tail为数据的开始和结束索引
tail = n;
}
// 拷贝该数组的所有元素到目标数组
private <T> T[] copyElements(T[] a) {
if (head < tail) { // 开始索引大于结束索引,一次拷贝
System.arraycopy(elements, head, a, 0, size());
} else if (head > tail) {// 开始索引在结束索引的右边,分两段拷贝
int headPortionLen = elements.length - head;
System.arraycopy(elements, head, a, 0, headPortionLen);
System.arraycopy(elements, 0, a, headPortionLen, tail);
}
return a;
}
扩容的实现为按 两倍 扩容原数组,将原数倍拷贝过去。
其中值得注意的是对数组大小溢出的处理。
# 5. 总结
参考文档:
https://segmentfault.com/a/1190000016330001 (opens new window)
https://www.jianshu.com/p/132733115f95 (opens new window)
# (2). ConcurrentLinkedDeque
# 1. 概述
ConcurrentLinkedDeque是双向链表结构的无界并发队列。从JDK 7开始加入到JUC的行列中。使用CAS实现并发安全,与ConcurrentLinkedQueue的区别是该阻塞队列同时支持FIFO和FILO两种操作方式,即可以从队列的头和尾同时操作(插入/删除)。适合“多生产,多消费”的场景。内存一致性遵循对ConcurrentLinkedDeque的插入操作先行发生于(happen-before)访问或移除操作。注意:size方法不是一个准确的操作
ConcurrentLinkedDeque(后面称CLD) 的实现方式继承了ConcurrentLinkedQueue和LinkedTransferQueue的思想,在非阻塞算法的实现方面与ConcurrentLinkedQueue基本一致。
# 2. 源码剖析
# 1. 重要的属性
//头节点
private transient volatile Node<E> head;
//尾节点
private transient volatile Node<E> tail;
//终止节点
private static final Node<Object> PREV_TERMINATOR, NEXT_TERMINATOR;
//移除节点时更新链表属性的阀值
private static final int HOPS = 2;
和ConcurrentLinkedQueue一样,CLD 内部也只维护了head和tail属性,对 head/tail 节点也使用了“不变性”和“可变性”约束,不过跟 ConcurrentLinkedQueue 有些许差异,我们来看一下:
head/tail 的不变性:
- 第一个节点总是能以O(1)的时间复杂度从 head 通过 prev 链接到达;
- 最后一个节点总是能以O(1)的时间复杂度从 tail 通过 next 链接到达;
- 所有live节点(item不为null的节点),都能从第一个节点通过调用 succ() 方法遍历可达;
- 所有live节点(item不为null的节点),都能从最后一个节点通过调用 pred() 方法遍历可达;
- head/tail 不能为 null;
- head 节点的 next 域不能引用到自身;
- head/tail 不会是GC-unlinked节点(但它可能是unlink节点)。
head/tail的可变性:
- head/tail 节点的 item 域可能为 null,也可能不为 null;
- head/tail 节点可能从first/last/tail/head 节点访问时不可达;
- tail 节点的 next 域可以引用到自身。
注:CLD中也对 head/tail 的更新也使用了“松弛阀值”的概念,除此之外,CLD设定了一个“跳跃阀值”-HOPS(指在查找活动节点时跳过的已删除节点数),在执行出队操作时,跳跃节点数大于2或者操作的节点不是 first/last 节点时才会更新链表(后面源码中详细分析)。
除此之外,再来看看CLD中另外两个属性:
- PREV_TERMINATOR:prev的终止节点,next指向自身,即
PREV_TERMINATOR.next = PREV_TERMINATOR。在 first 节点出列后,会把first.next指向自身(first.next=first),然后把prev设为PREV_TERMINATOR。 - NEXT_TERMINATOR:next的终止节点,prev指向自身,即
NEXT_TERMINATOR.pre = NEXT_TERMINATOR。在 last 节点出列后,会把last.prev指向自身(last.prev=last),然后把next设为NEXT_TERMINATOR。
# 2. Node的定义
- live node:节点的 item!=null 被称为live节点。当节点的 item 被 CAS 改为 null,逻辑上来讲这个节点已经从链表中移除;一个新的元素通过 CAS 添加到一个包含空 prev 或空 next 的 first 或 last 节点,这个元素的节点在这时是 live节点。
- first node & last node:首节点(first node)总会有一个空的 prev 引用,终止任何从 live 节点开始的 prev 引用链;同样的最后一个节点(last node)是 next 的终止节点。first/last 节点的 item 可以为 null。并且 first 和 last 节点总是相互可达的。
- active node:live节点、first/last 节点也被称为活跃节点(active node),活跃节点一定是被链接的,如果p节点为active节点,则:
p.item != null || (p.prev == null && p.next != p) || (p.next == null && p.prev != p) - self-node:自链接节点,prev 或 next 指向自身的节点,自链接节点用在解除链接操作中,并且它们都不是active node。
- head/tail节点:head/tail 也可能不是 first/last 节点。从 head 节点通过 prev 引用总是可以找到 first 节点,从 tail 节点通过 next 引用总是可以找到 last 节点。允许 head 和 tail 引用已删除的节点,这些节点没有链接,因此可能无法从 live 节点访问到。
节点删除时经历三个阶段:逻辑删除(logical deletion),未链接( unlinking),和gc未链接( gc-unlinking):
- **logical deletion:**通过 CAS 修改节点 item 为 null 来完成,表示当前节点可以被解除链接(unlinking)。
- unlinking: 这种状态下的节点与其他 active 节点有链接,但是其他 active 节点与之都没有链接,也就是说从这个状态下的节点可以达到 active 节点,但是从 active 节点不可达到这种状态的节点。在任何时候,从 first 通过 next 找到的 live 节点和从 last 通过 prev 找到的节点总是相等的。但是,在节点被逻辑删除时上述结论不成立,这些被逻辑删除的节点也可能只从一端是可达的。
- gc-unlinking: GC未链接使已删除节点不可达到 active 节点,使GC更容易回收被删除的节点。通过让节点自链接或链接到终止节点(PREV_TERMINATOR 或 NEXT_TERMINATOR)来实现。 gc-unlinking 节点从 head/tail 访问不可达。这一步是为了使数据结构保持GC健壮性(gc-robust),防止保守式GC(conservative GC,目前已经很少使用)对这些边界空间的使用。对保守式GC来说,使数据结构保持GC健壮性会消除内存无限滞留的问题,同时也提高了分代收机器的性能。
# 3. 入列
入列方法包括:offer(E)、add(E)、push(E)、addFirst(E)、addLast(E)、offerFirst(E)、offerLast(E),所有这些操作都是通过linkFirst(E)或linkLast(E)来实现的。
/**
* Links e as first element.
*/
private void linkFirst(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
restartFromHead:
for (;;)
//从head节点往前寻找first节点
for (Node<E> h = head, p = h, q;;) {
if ((q = p.prev) != null &&
(q = (p = q).prev) != null)
// Check for head updates every other hop.
// If p == q, we are sure to follow head instead.
//如果head被修改,返回head重新查找
p = (h != (h = head)) ? h : q;
else if (p.next == p) // 自链接节点,重新查找
continue restartFromHead;
else {
// p is first node
newNode.lazySetNext(p); // CAS piggyback
if (p.casPrev(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this deque,
// and for newNode to become "live".
if (p != h) // hop two nodes at a time 跳两个节点时才修改head
casHead(h, newNode); // Failure is OK.
return;
}
// Lost CAS race to another thread; re-read prev
}
}
}
/**
* Links e as last element.
*/
private void linkLast(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
restartFromTail:
for (;;)
//从tail节点往后寻找last节点
for (Node<E> t = tail, p = t, q;;) {
if ((q = p.next) != null &&
(q = (p = q).next) != null)
// Check for tail updates every other hop.
// If p == q, we are sure to follow tail instead.
//如果tail被修改,返回tail重新查找
p = (t != (t = tail)) ? t : q;
else if (p.prev == p) // 自链接节点,重新查找
continue restartFromTail;
else {
// p is last node
newNode.lazySetPrev(p); // CAS piggyback
if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this deque,
// and for newNode to become "live".
if (p != t) // hop two nodes at a time 跳两个节点时才修改tail
casTail(t, newNode); // Failure is OK.
return;
}
// Lost CAS race to another thread; re-read next
}
}
}
说明:linkFirst是插入新节点到队列头的主函数,执行流程如下:
首先从 head 节点开始向前循环找到 first 节点(p.prev==null&&p.next!=p);然后通过lazySetNext设置新节点的 next 节点为 first;然后 CAS 修改 first 的 prev 为新节点。注意这里 CAS 指令成功后会判断 first 节点是否已经跳了两个节点,只有在跳了两个节点才会 CAS 更新 head,这也是为了节省 CAS 指令执行开销。linkLast是插入新节点到队列尾,执行流程与linkFirst一致。
注:
lazySetNext通过 Unsafe 类的putOrderedObject实现
# 4. 出列
出列方法分两种:
- 获取节点:
peek、peekFirst 、peekLast、getFirst、getLast,都是通过peekFirst 、peekLast实现。 - 获取并移除节点:
poll、pop、remove、pollFirst、pollLast、removeFirst、removeLast,都是通过pollFirst、pollLast实现。pollFirst、pollLast包括了peekFirst 、peekLast的实现,都是找到并返回 first/last 节点,不同的是,pollFirst、pollLast比peekFirst 、peekLast多了 unlink 这一步。所以这里我们只对pollFirst和pollLast两个方法进行解析。
/**获取并移除队列首节点*/
public E pollFirst() {
for (Node<E> p = first(); p != null; p = succ(p)) {
E item = p.item;
if (item != null && p.casItem(item, null)) {
unlink(p);
return item;
}
}
return null;
}
/**获取并移除队列尾节点*/
public E pollLast() {
for (Node<E> p = last(); p != null; p = pred(p)) {
E item = p.item;
if (item != null && p.casItem(item, null)) {
unlink(p);
return item;
}
}
return null;
}
说明: pollFirst()用于找到链表中首个 item 不为 null 的节点(注意并不是first节点,因为first节点的item可以为null),并返回节点的item。涉及的内部方法较多,不过都很简单,我们通过穿插代码方式分析:
先通过
first()方法找到 first 节点,first 节点必须为 active 节点(p.prev==null&&p.next!=p)。first()源码如下:Node<E> first() { restartFromHead: for (;;) //从head开始往前找 for (Node<E> h = head, p = h, q;;) { if ((q = p.prev) != null && (q = (p = q).prev) != null) // Check for head updates every other hop. // If p == q, we are sure to follow head instead. //如果head被修改则返回新的head重新查找,否则继续向前(prev)查找 p = (h != (h = head)) ? h : q; else if (p == h // It is possible that p is PREV_TERMINATOR, // but if so, the CAS is guaranteed to fail. //找到的节点不是head节点,CAS修改head || casHead(h, p)) return p; else continue restartFromHead; } }如果
first.item==null(这里是允许的,具体见上面我们对 first/last 节点的介绍),则继续调用succ方法寻找后继节点。succ源码如下:/**返回指定节点的的后继节点,如果指定节点的next指向自己,返回first节点*/ final Node<E> succ(Node<E> p) { // TODO: should we skip deleted nodes here? Node<E> q = p.next; return (p == q) ? first() : q; }CAS 修改节点的 item 为 null(即 “逻辑删除-logical deletion”),然后调用
unlink(p)方法解除节点链接,最后返回 item。
# 5. unlink(Node x)
/**
* Unlinks non-null node x.
*/
void unlink(Node<E> x) {
// assert x != null;
// assert x.item == null;
// assert x != PREV_TERMINATOR;
// assert x != NEXT_TERMINATOR;
final Node<E> prev = x.prev;
final Node<E> next = x.next;
if (prev == null) {//操作节点为first节点
unlinkFirst(x, next);
} else if (next == null) {//操作节点为last节点
unlinkLast(x, prev);
} else {// common case
Node<E> activePred, activeSucc;
boolean isFirst, isLast;
int hops = 1;
// Find active predecessor
//从被操作节点的prev节点开始找到前继活动节点
for (Node<E> p = prev; ; ++hops) {
if (p.item != null) {
activePred = p;
isFirst = false;
break;
}
Node<E> q = p.prev;
if (q == null) {
if (p.next == p)
return;//自链接节点
activePred = p;
isFirst = true;
break;
}
else if (p == q)//自链接节点
return;
else
p = q;
}
// Find active successor
for (Node<E> p = next; ; ++hops) {
if (p.item != null) {
activeSucc = p;
isLast = false;
break;
}
Node<E> q = p.next;
if (q == null) {
if (p.prev == p)
return;
activeSucc = p;
isLast = true;
break;
}
else if (p == q)//自链接节点
return;
else
p = q;
}
// TODO: better HOP heuristics
//无节点跳跃并且操作节点有first或last节点时不更新链表
if (hops < HOPS
// always squeeze out interior deleted nodes
&& (isFirst | isLast))
return;
// Squeeze out deleted nodes between activePred and
// activeSucc, including x.
//连接两个活动节点
skipDeletedSuccessors(activePred);
skipDeletedPredecessors(activeSucc);
// Try to gc-unlink, if possible
if ((isFirst | isLast) &&
// Recheck expected state of predecessor and successor
(activePred.next == activeSucc) &&
(activeSucc.prev == activePred) &&
(isFirst ? activePred.prev == null : activePred.item != null) &&
(isLast ? activeSucc.next == null : activeSucc.item != null)) {
updateHead(); // Ensure x is not reachable from head
updateTail(); // Ensure x is not reachable from tail
// Finally, actually gc-unlink
x.lazySetPrev(isFirst ? prevTerminator() : x);
x.lazySetNext(isLast ? nextTerminator() : x);
}
}
}
说明:unlink(Node x)方法用于解除已弹出节点的链接,分三种情况:
首先说一下通常的情况(源码中标注
common case处),这种情况下,入列和出列非同端操作,即操作节点 x 非 first 和 last 节点, 就执行如下流程:- 首先找到给定节点 x 的活跃(active)前继和后继节点。然后修整它们之间的链接,让它们指向对方(通过
skipDeletedSuccessors和skipDeletedPredecessors方法),留下一个从活跃(active)节点不可达的 x 节点(即“unlinking”)。 - 如果成功执行,或者 x 节点没有 live 的前继/后继节点,再尝试 gc 解除链接(gc-unlink),在设置 x 节点的 prev/next 指向它们自己或 TERMINATOR 之前(即“gc-unlink”),需要检查 x 的前继和后继节点的状态未被改变,并保证 x 节点从 head/tail 不可达(通过
updateHead()和updateTail()方法)。
- 首先找到给定节点 x 的活跃(active)前继和后继节点。然后修整它们之间的链接,让它们指向对方(通过
如果操作节点为 first 节点(入列和出列都发生在 first 端),则调用
unlinkFirst解除已删除节点的链接,并链接 first 节点到下一个 active 节点(注意,在执行完此方法之后 first 节点是没有改变的)。unlinkFirst源码如下:/** * Unlinks non-null first node. */ private void unlinkFirst(Node<E> first, Node<E> next) { // assert first != null; // assert next != null; // assert first.item == null; //从next节点开始向后寻找有效节点,o:已删除节点(item为null) for (Node<E> o = null, p = next, q;;) { if (p.item != null || (q = p.next) == null) { //跳过已删除节点,CAS替换first的next节点为一个active节点p if (o != null && p.prev != p && first.casNext(next, p)) { //更新p的prev节点 skipDeletedPredecessors(p); if (first.prev == null && (p.next == null || p.item != null) && p.prev == first) { //更新head节点,确保已删除节点o从head不可达(unlinking) updateHead(); // Ensure o is not reachable from head //更新tail节点,确保已删除节点o从tail不可达(unlinking) updateTail(); // Ensure o is not reachable from tail // Finally, actually gc-unlink //使unlinking节点next指向自身 o.lazySetNext(o); //设置移除节点的prev为PREV_TERMINATOR o.lazySetPrev(prevTerminator()); } } return; } else if (p == q)//自链接节点 return; else { o = p; p = q; } } }如果操作节点为 last 节点(入列和出列都发生在 last 端),则调用
unlinkLast解除已删除节点的链接,并链接 last 节点到上一个 active 节点。unlinkLast与unlinkFirst方法执行流程一致,只是操作的是 last 端,在此不多赘述。
# 3. 总结
- 基于链接节点的无界并发 deque 。 并发插入,删除和访问操作可以跨多个线程安全执行。 一个
ConcurrentLinkedDeque是许多线程将共享对公共集合的访问的适当选择。 像大多数其他并发集合实现一样,此类不允许使用null元素,ConcurrentLinkedDeque是一个双向链表 。 ConcurrentLinkedDeque使用了自旋+CAS的非阻塞算法来保证线程并发访问时的数据一致性。由于队列本身是一种双链表结构,所以虽然算法看起来很简单,但其实需要考虑各种并发的情况,实现复杂度较高,并且ConcurrentLinkedDeque不具备实时的数据一致性,实际运用中,如果需要一种线程安全的栈结构,可以使用ConcurrentLinkedDeque。- 关于
ConcurrentLinkedDeque还有以下需要注意的几点ConcurrentLinkedDeque的迭代器是弱一致性的,这在并发容器中是比较普遍的现象,主要是指在一个线程在遍历队列结点而另一个线程尝试对某个队列结点进行修改的话不会抛出ConcurrentModificationException,这也就造成在遍历某个尚未被修改的结点时,在next方法返回时可以看到该结点的修改,但在遍历后再对该结点修改时就看不到这种变化。- size方法需要遍历链表,所以在并发情况下,其结果不一定是准确的,只能供参考。
参考文档
https://www.jianshu.com/p/602b3240afaf (opens new window)
# 十四、其他重要的容器
# (1). ConcurrentHashMap
# 1. 概述
# (2). ConcurrentSkipListMap
# 1. 概述
ConcurrentSkipListMap是线程安全的有序的哈希表,适用于高并发的场景。跳表(跳跃表)是一种数据结构,改进自链表,用于存储有序的数据,跳跃表通过空间换时间的方法来提高数据检索的速度。空间换时间的算法是:建立多级索引,实现以二分查找遍历一个有序链表。时间复杂度等同于红黑树的 O(log n)。但实现却远远比红黑树要简单。
ConcurrentSkipListMap其实是TreeMap的并发版本。TreeMap使用的是红黑树,并且按照key的顺序排序(自然顺序、自定义顺序),但是他是非线程安全的,如果在并发环境下,建议使用ConcurrentHashMap或者ConcurrentSkipListMap (opens new window)。
# 2. 跳跃表的数据结构介绍
# 1. 跳跃表具有以下几个必备的性质
- 最底层包含所有节点的一个有序的链表
- 每一层都是一个有序的链表
- 每个节点都有两个指针,一个指向右侧节点(没有则为空),一个指向下层节点(没有则为空)
- 必备一个头节点指向最高层的第一个节点,通过它可以遍历整张表
# 2. 查找一个元素
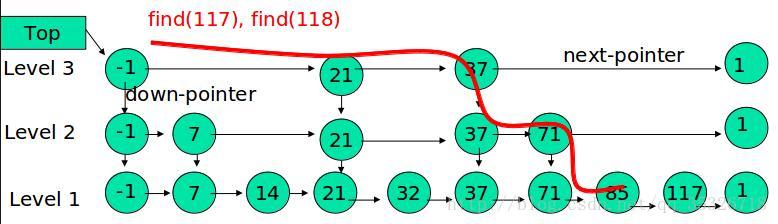
查找的过程有点像我们的二分查找,不过这里我们是通过为链表建立多级索引,以空间换时间来实现二分查找。所以,跳表的查询操作的时间复杂度为 O(logN)。
# 3. 跳表的插入操作
首先,跳表的插入必然会在底层增加一个节点,但是往上的层次是否需要增加节点则完全是随机的,SkipList 通过概率保证整张表的节点分布均匀,它不像红黑树是通过人为的 rebalance 操作来保证二叉树的平衡性。(数学对于计算机还是很重要的)。通过概率算法得到新插入节点的一个 level 值,如果小于当前表的最大 level,从最底层到 level 层都添加一个该节点。例如:
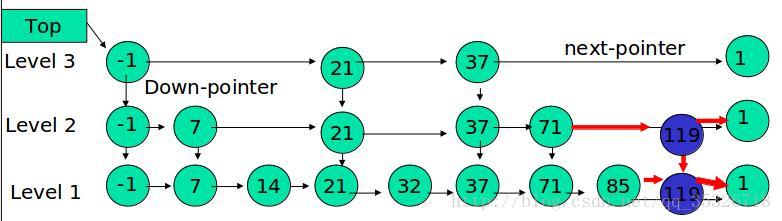
如图,首先 119 节点会被添加到最底层链表的合适位置,然后通过概率算法得到 level 为 2,于是 1—2 层中的每一层都添加了 119 节点。
如果概率算法得到的 level 大于当前表的最大 level 值的话,那么将会新增一个 level,并且将新节点添加到该 level 上。
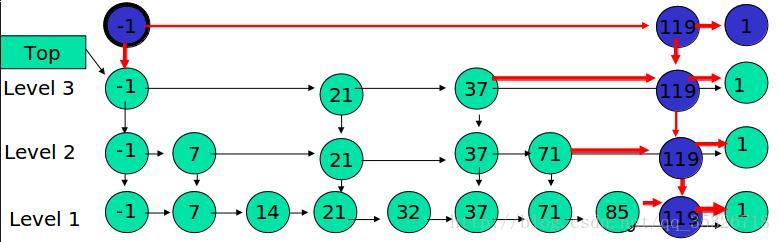
# 4. 跳表的删除操作
跳表的删除操作其实就是一个查找加删除节点的操作
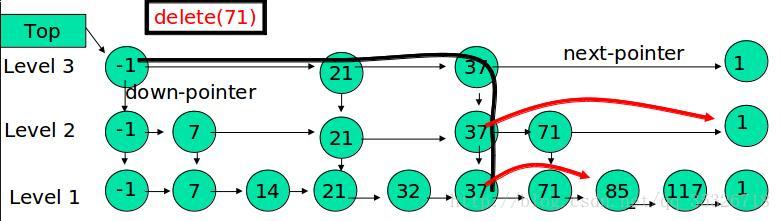
# 3. ConcurrentSkipListMap 的前导知识预备
在实际分析 put 方法之前,有一些预备的知识需要先有个大致的了解,否则在实际分析源码的时候会感觉吃力些。
首先是删除操作,在我们上述的跳表数据结构中谈及的删除操作主要是定位待删结点 + 删除该结点的一个复合操作。而在我们的并发跳表中,删除操作相对复杂点,需要分为以下三个步骤:
- 找到待删结点并将其 value 属性值由 notnull 置为 null,整个过程是基于 CAS 无锁式算法的
- 向待删结点的 next 位置新增一个 marker 标记结点,整个过程也是基于 CAS 无锁式算法
- CAS 式删除具体的结点,实际上也就是跳过该待删结点,让待删结点的前驱节点直接越过本身指向待删结点的后继结点即可
例如我们有以下三个结点,n 为待删除的结点。
+——+ +——+ +——+
… | b |——>| n |—–>| f | …
+——+ +——+ +——+
第一步是找到 n ,然后 CAS 该结点的 value 值为 null。如果该步骤失败了,那么 ConcurrentSkipListMap 会通过循环再次尝试 CAS 将 n 的 value 属性赋值为 null。
第二步是建立在第一步成功的前提下的,n 的当前 value 属性的值为 null,ConcurrentSkipListMap 试图在 n 的后面增加一个空的 node 结点(marker)以分散下一步的并发冲突性。
+------+ +------+ +------+ +------+
... | b |------>| n |----->|marker|---->| f | ...
+------+ +------+ +------+ +------+
第三步,断链操作。如果 marker 添加失败,将不会有第三步,直接回重新回到第一步。如果成功添加,那么将试图断开 b 到 n 的链接,直接绕过 n,让 b 的 next 指向 f。那么,这个 n 结点将作为内存中的一个游离结点,最终被 GC 掉。断开失败的话,也将回到第一步。
+------+ +------+
... | b |----------------------->| f | ...
+------+ +------+
# 5. 源码剖析
# 1. node 结点类型的定义
这是 node 结点类型的定义,是最基本的数据存储单元。
static final class Node<K,V> {
final K key;
volatile Object value;
volatile Node<K,V> next;
Node(K key, Object value, Node<K,V> next) {
this.key = key;
this.value = value;
this.next = next;
}
//省略其它的一些基于当前结点的 CAS 方法
}
# 2. Index 结点
Index 结点封装了 node 结点,作为跳表的最基本组成单元。
static class Index<K,V> {
final Node<K,V> node;
final Index<K,V> down;
volatile Index<K,V> right;
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
//省略其它的一些基于当前结点的 CAS 方法
}
# 3. HeadIndex:头结点
HeadIndex 封装了 Index 结点,作为每层的头结点,level 属性用于标识当前层次的序号。
static final class HeadIndex<K,V> extends Index<K,V> {
final int level;
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
}
# 4. 重要的属性
// 整个跳表的头结点,通过它可以遍历访问整张跳表。
private transient volatile HeadIndex<K,V> head;
// 比较器,用于比较两个元素的键值大小,如果没有显式传入则默认为自然排序
final Comparator<? super K> comparator;
// 特殊的值,用于初始化跳表
private static final Object BASE_HEADER = new Object();
# 5. 构造函数
//未传入比较器,则为默认值
public ConcurrentSkipListMap() {
this.comparator = null;
initialize();
}
public ConcurrentSkipListMap(Comparator<? super K> comparator) {
this.comparator = comparator;
initialize();
}
//所有的构造器都会调用这个初始化的方法
private void initialize() {
keySet = null;
entrySet = null;
values = null;
descendingMap = null;
head = new HeadIndex<K,V>(new Node<K,V>(null, BASE_HEADER, null),null, null, 1);
}
这个初始化方法主要完成的是对整张跳表的一个初始化操作,head 头指针指向这个并没有什么实际意义的头结点。 重点还是那三个内部类,都分别代表了什么样的结点类型,都使用在何种场景下。
# 6. put 并发添加的内部实现
//基本的 put 方法,向跳表中添加一个节点
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
}
put 方法的内部调用的是 doPut 方法来实现添加元素的,但是由于 doPut 方法的方法体很长,我们分几个部分进行分析。
//第一部分
private V doPut(K key, V value, boolean onlyIfAbsent) {
Node<K,V> z;
//边界值判断,空的 key 自然是不允许插入的
if (key == null)
throw new NullPointerException();
//拿到比较器的引用
Comparator<? super K> cmp = comparator;
outer: for (;;) {
//根据 key,找到待插入的位置
//b 叫做前驱节点,将来作为新加入结点的前驱节点
//n 叫做后继结点,将来作为新加入结点的后继结点
//也就是说,新节点将插入在 b 和 n 之间
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
//如果 n 为 null,那么说明 b 是链表的最尾端的结点,这种情况比较简单,直接构建新节点插入即可
//否则走下面的判断体
if (n != null) {
Object v; int c;
Node<K,V> f = n.next;
//如果 n 不再是 b 的后继结点了,说明有其他线程向 b 后面添加了新元素
//那么我们直接退出内循环,重新计算新节点将要插入的位置
if (n != b.next)
break;
//value =0 说明 n 已经被标识位待删除,其他线程正在进行删除操作
//调用 helpDelete 帮助删除,并退出内层循环重新计算待插入位置
if ((v = n.value) == null) {
n.helpDelete(b, f);
break;
}
//b 已经被标记为待删除,前途结点 b 都丢了,可不得重新计算待插入位置吗
if (b.value == null || v == n)
break;
//如果新节点的 key 大于 n 的 key 说明找到的前驱节点有误,按序往后挪一个位置即可
//回到内层循环重新试图插入
if ((c = cpr(cmp, key, n.key)) > 0) {
b = n;
n = f;
continue;
}
//新节点的 key 等于 n 的 key,这是一次 update 操作,CAS 更新即可
//如果更新失败,重新进循环再来一次
if (c == 0) {
if (onlyIfAbsent || n.casValue(v, value)) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
break;
}
}
//无论遇到何种问题,到这一步说明待插位置已经确定
z = new Node<K,V>(key, value, n);
if (!b.casNext(n, z))
break;
//如果成功了,退出最外层循环,完成了底层的插入工作
break outer;
}
}
以上这一部分主要完成了向底层链表插入一个节点,至于其中具体的怎么找前驱节点的方法稍后介绍。但这其实只不过才完成一小半的工作,就像红黑树在插入后需要 rebalance 一样,我们的跳表需要根据概率算法保证节点分布稳定,它的调节措施相对于红黑树来说就简单多了,通过往上层索引层添加相关引用即可,以空间换时间。具体的我们来看:
//第二部分
//获取一个线程无关的随机数,占四个字节,32 个比特位
int rnd = ThreadLocalRandom.nextSecondarySeed();
//和 1000 0000 0000 0000 0000 0000 0000 0001 与
//如果等于 0,说明这个随机数最高位和最低位都为 0,这种概率很大
//如果不等于 0,那么将仅仅把新节点插入到最底层的链表中即可,不会往上层递归
if ((rnd & 0x80000001) == 0) {
int level = 1, max;
//用低位连续为 1 的个数作为 level 的值,也是一种概率策略
while (((rnd >>>= 1) & 1) != 0)
++level;
Index<K,V> idx = null;
HeadIndex<K,V> h = head;
//如果概率算得的 level 在当前跳表 level 范围内
//构建一个从 1 到 level 的纵列 index 结点引用
if (level <= (max = h.level)) {
for (int i = 1; i <= level; ++i)
idx = new Index<K,V>(z, idx, null);
}
//否则需要新增一个 level 层
else {
level = max + 1;
@SuppressWarnings("unchecked")
Index<K,V>[] idxs =(Index<K,V>[])new Index<?,?>[level+1];
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K,V>(z, idx, null);
for (;;) {
h = head;
int oldLevel = h.level;
//level 肯定是比 oldLevel 大一的,如果小了说明其他线程更新过表了
if (level <= oldLevel)
break;
HeadIndex<K,V> newh = h;
Node<K,V> oldbase = h.node;
//正常情况下,循环只会执行一次,如果由于其他线程的并发操作导致 oldLevel 的值不稳定,那么会执行多次循环体
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j);
//更新头指针
if (casHead(h, newh)) {
h = newh;
idx = idxs[level = oldLevel];
break;
}
}
}
这一部分的代码主要完成的是根据 level 的值,确认是否需要增加一层索引,如果不需要则构建好底层到 level 层的 index 结点的纵向引用。如果需要,则新创建一层索引,完成 head 结点的指针转移,并构建好纵向的 index 结点引用。
//第三部分
if ((rnd & 0x80000001) == 0){
//省略第二部分的代码段
//第三部分的代码是紧接着第二部分代码段后面的
splice: for (int insertionLevel = level;;) {
int j = h.level;
for (Index<K,V> q = h, r = q.right, t = idx;;) {
//其他线程并发操作导致头结点被删除,直接退出外层循环
//这种情况发生的概率很小,除非并发量实在太大
if (q == null || t == null)
break splice;
if (r != null) {
Node<K,V> n = r.node;
int c = cpr(cmp, key, n.key);
//如果 n 正在被其他线程删除,那么调用 unlink 去删除它
if (n.value == null) {
if (!q.unlink(r))
break;
//重新获取 q 的右结点,再次进入循环
r = q.right;
continue;
}
//c > 0 说明前驱结点定位有误,重新进入
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
if (j == insertionLevel) {
//尝试着将 t 插在 q 和 r 之间,如果失败了,退出内循环重试
if (!q.link(r, t))
break; // restart
//如果插入完成后,t 结点被删除了,那么结束插入操作
if (t.node.value == null) {
findNode(key);
break splice;
}
// insertionLevel-- 处理底层链接
if (--insertionLevel == 0)
break splice;
}
//--j,j 应该与 insertionLevel 同步,它代表着我们创建的那个纵向的结点数组的索引
//并完成层次下移操作
if (--j >= insertionLevel && j < level)
t = t.down;
//至此,新节点在当前层次的前后引用关系已经被链接完成,现在处理下一层
q = q.down;
r = q.right;
}
}
}
return null;
}
我们根据概率算法得到了一个 level 值,并且通过第二步创建了 level 个新节点并构成了一个纵向的引用关联,但是这些纵向的结点并没有链接到每层中。而我们的第三部分代码就是完成的这个工作,将我们的新节点在每个索引层都构建好前后的链接关系。下面用三张图描述着三个部分所完成的主要工作。
# 7. 图解
初始化的跳表如下:
第一部分,新增一个结点到最底层的链表上。
第二部分,假设概率得出一个 level 值为 10,那么根据跳表的算法描述需要新建一层索引层。
第三步,链接各个索引层次上的新节点。
这样就完成了新增结点到跳表中的全部过程,大体上已如上图描述,至于 ConcurrentSkipListMap 中关于并发处理的细节之处,图中无法展示,大家可据此重新感受下源码的实现过程。下面我们着重描述下整个 doPut 方法中还涉及的其他几个方法的具体实现。
# 8. findPredecessor()方法
首先是 findPredecessor 方法,我们说该方法将根据给定的 key,为我们返回最合适的前驱节点。
private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) {
if (key == null)
throw new NullPointerException();
for (;;) {
for (Index<K,V> q = head, r = q.right, d;;) {
//r 为空说明 head 后面并没有其他节点了
if (r != null) {
Node<K,V> n = r.node;
// r 节点处于待删除状态,那么尝试 unlink 它,失败了将重新进入循环再此尝试
//否则重新获取 q 的右结点并重新进入循环查找前驱节点
if (n.value == null) {
if (!q.unlink(r))
break; // restart
r = q.right; // reread r
continue;
}
//大于零说明当前位置上的 q 还不是我们要的前驱节点,继续往后找
if (cpr(cmp, key, k) > 0) {
q = r;
r = r.right;
continue;
}
}
//如果当前的 level 结束了或者 cpr(cmp, key, k) <= 0 会达到此位置
//往低层递归,如果没有低层了,那么当前的 q 就是最合适的前驱节点
//整个循环只有这一个出口,无论如何最终都会从此处结束方法
if ((d = q.down) == null)
return q.node;
//否则向低层递归并重置 q 和 r
q = d;
r = d.right;
}
}
}
最后总结下 findPredecessor 方法的大体逻辑,首先程序会从 head 节点开始在当前的索引层上寻找最后一个比给定 key 小的结点,它就是我们需要的前驱节点(q),我们只需要返回它即可。
# 9. helpDelete()方法
其次我们看看 helpDelete 方法,当检测到某个结点的 value 属性值为 null 的时候,一般都会调用这个方法来删除该结点。
/*
一般的调用形式如下:
n.helpDelete(b, f);
*/
void helpDelete(Node<K,V> b, Node<K,V> f) {
if (f == next && this == b.next) {
if (f == null || f.value != f)
casNext(f, new Node<K,V>(f));
else
b.casNext(this, f.next);
}
}
该方法是 Node 结点的内部实例方法,逻辑相对简单,此处不再赘述。通过该方法可以完成将 b.next 指向 f,完成对 n 结点的删除。
至此,有关 put 方法的源码分析就简单到这,大部分的代码还是用于实现跳表这种数据结构的构建和插入,关于并发的处理,你会发现基本都是双层 for 循环+ CAS 无锁式更新,如果遇到竞争失利将退出里层循环重新进行尝试,否则成功的话就会直接 return 或者退出外层循环并结束 CAS 操作。下面我们看删除操作是如何实现的。
# 10. remove 并发删除操作的内部实现
remove 方法的部分内容我们在介绍相关预备知识中已经提及过,此处的理解想必会容易些。
public V remove(Object key) {
return doRemove(key, null);
}
//代码比较多,建议读者结合自己的 jdk 源码共同来分析
final V doRemove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
//找到 key 的前驱节点
//因为删除不单单是根据 key 找到对应的结点,然后赋 null 就完事的,还要负责链接该结点前后的关联
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
//目前 n 基本上就是我们要删除的结点,它为 null,那自然不用继续了,已经被删除了
if (n == null)
break outer;
Node<K,V> f = n.next;
//再次确认 n 还是不是 b 的后继结点,如果不是将退出里层循环重新进入
if (n != b.next)
break;
//如果有人正在删除 n,那么帮助它删除
if ((v = n.value) == null) {
n.helpDelete(b, f);
break;
}
//b 被删除了,重新定位前驱节点
if (b.value == null || v == n)
break;
//正常情况下,key 应该等于 n.key
//key 大于 n.key 说明我们要找的结点可能在 n 的后面,往后递归即可
//key 小于 n.key 说明 key 所代表的结点根本不存在
if ((c = cpr(cmp, key, n.key)) < 0)
break outer;
if (c > 0) {
b = n;
n = f;
continue;
}
//如果删除是根据键和值两个参数来删除的话,value 是不为 null 的
//这种情况下,如果 n 的 value 属性不等于我们传入的 value ,那么是不进行删除的
if (value != null && !value.equals(v))
break outer;
//下面三个步骤才是整个删除操作的核心,大致的逻辑我们也在上文提及过了,此处想必会容易理解些
//第一步,尝试将待删结点的 value 属性赋值 null,失败将退出重试
if (!n.casValue(v, null))
break;
//第二步和第三步如果有一步由于竞争失败,将调用 findNode 方法根据我们第一步的成果,也就是删除所有 value 为 null 的结点
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key);
//否则说明三个步骤都成功完成了
else {
findPredecessor(key, cmp);
//判断此次删除后是否导致某一索引层没有其他节点了,并适情况删除该层索引
if (head.right == null)
tryReduceLevel();
}
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
}
return null;
}
remove 方法其实从整体上来看,首先会有一堆的判断,根据给定的 key 和 value 会判断是否存在与 key 对应的一个节点,也会判断和待删结点相关的前后结点是否正在被删除,并适情况帮助删除。其次才是删除的三大步骤,核心步骤还是将待删结点的 value 属性赋 null 以标记该结点无用了,至于这个 marker 也是为了分散并发冲突的,最后通过 casNext 完成结点的删除。
# 11. get 方法获取指定结点的 value
public V get(Object key) {
return doGet(key);
}
private V doGet(Object key) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
//依然是双层循环来处理并发
outer: for (;;) {
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
//以下的一些判断的作用已经描述了多次,此处不再赘述了
if (n == null)
break outer;
Node<K,V> f = n.next;
if (n != b.next)
break;
if ((v = n.value) == null) {
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n)
break;
//c = 0 说明 n 就是我们要的结点
if ((c = cpr(cmp, key, n.key)) == 0) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
//c < 0 说明不存在这个 key 所对应的结点
if (c < 0)
break outer;
b = n;
n = f;
}
}
return null;
}
doGet 方法的实现相对还是比较简单的,所以并没有给出太多的注释,主要还是由于大量的并发判断的代码都是一样的,大多都已经在 doPut 方法中给予了详细的注释了。
# 12. 其它的一些方法的简单描述
//是否包含指定 key 的结点
public boolean containsKey(Object key) {
return doGet(key) != null;
}
//根据 key 返回该 key 所代表的结点的 value 值,不存在该结点则返回默认的 defaultValue
public V getOrDefault(Object key, V defaultValue) {
V v;
return (v = doGet(key)) == null ? defaultValue : v;
}
//返回跳表的实际存储元素个数,采取遍历来进行统计
public int size() {
long count = 0;
for (Node<K,V> n = findFirst(); n != null; n = n.next) {
if (n.getValidValue() != null)
++count;
}
return (count >= Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) count;
}
//返回所有键的集
public NavigableSet<K> keySet() {
KeySet<K> ks = keySet;
return (ks != null) ? ks : (keySet = new KeySet<K>(this));
}
//返回所有值的集
public Collection<V> values() {
Values<V> vs = values;
return (vs != null) ? vs : (values = new Values<V>(this));
}
这里需要说明一点的是,虽然返回来的是键或者值的一个集合,但是无论你是通过这个集合获取键或者值,还是删除集合中的键或者值,都会直接映射到当前跳表实例中。原因是这个集合中没有一个方法是自己实现的,都是调用传入的跳表实例的内部方法,具体的大家查看源码即可知晓,此处不再贴出源码。
# 6. 跳跃表的应用场景大概是这样的
- 有序
- 频繁插入和删除
- 频繁查询
# 7. 使用建议
在非多线程的情况下,应当尽量使用TreeMap。
对于并发性相对较低的并行程序可以使用Collections.synchronizedSortedMap将TreeMap进行包装,也可以提供较好的效率。
对于高并发程序,应当使用ConcurrentSkipListMap,能够提供更高的并发度。
所以在多线程程序中,如果需要对Map的键值进行排序时,请尽量使用ConcurrentSkipListMap,可能得到更好的并发度。
注意,调用ConcurrentSkipListMap的size时,由于多个线程可以同时对映射表进行操作,所以映射表需要遍历整个链表才能返回元素个数,这个操作是个O(log(n))的操作。
参考:
https://blog.csdn.net/qq_35326718/article/details/78870658 (opens new window)
https://blog.csdn.net/vernonzheng/article/details/8244984 (opens new window)
# (3). ConcurrentSkipListSet
# 1. 概述
ConcurrentSkipListSet是线程安全的有序的集合,适用于高并发的场景。ConcurrentSkipListSet也是基于ConcurrentSkipListMap实现的。上面已经详细讲述了ConcurrentSkipListMap的原理及源码,故在此不做过多描述。
ConcurrentSkipListSet其实是TreeSet的并发版本。TreeSet底层使用红黑树,并且按照key的顺序排序(自然顺序、自定义顺序),但是他是非线程安全的,如果在并发环境下ConcurrentSkipListSet。
# 2. 总结
参考文档
https://www.jianshu.com/p/2f0c5a2c2dc4 (opens new window)
# (4). CopyOnWriteArrayList
# 1. 概述
CopyOnWriteArrayList这是一个ArrayList的线程安全的变体,其原理大概可以通俗的理解为:初始化的时候只有一个容器,很常一段时间,这个容器数据、数量等没有发生变化的时候,大家(多个线程),都是读取(假设这段时间里只发生读取的操作)同一个容器中的数据,所以这样大家读到的数据都是唯一、一致、安全的,但是后来有人往里面增加了一个数据,这个时候CopyOnWriteArrayList 底层实现添加的原理是先copy出一个容器(可以简称副本),再往新的容器里添加这个新的数据,最后把新的容器的引用地址赋值给了之前那个旧的的容器地址,但是在添加这个数据的期间,其他线程如果要去读取数据,仍然是读取到旧的容器里的数据。
为了将读取的性能发挥到极致,jdk中提供了CopyOnWriteArrayList类。对它来说,读取是完全不用加锁的,写入也不会阻塞读取操作。只有写入与写入之间需要进行同步等待。那么它是如何做到的呢?从这个类的名字中可以看出,CopyOnWrite就是在写入操作时,进行一次自我复制。也就是对原有的数据进行一次复制,将修改的内容写入副本中。写完之后,再将修改完的副本替换原来的数据。这样就可以保证写操作不影响读了。
# 2. 读取操作
private transient volatile Object[] array;
final Object[] getArray() {
return array;
}
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}
可以看到,读取代码没有任何同步控制和锁操作,因为内部数组array不会发生修改,只会被另一个array替换,可以保证数据安全。
# 3. 增删改操作
// 在最后面加入一个元素
public boolean add(E e) {
final ReentrantLock lock = this.lock;
//获得锁
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//复制一个新的数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
//插入新值
newElements[len] = e;
//将新的数组指向原来的引用
setArray(newElements);
return true;
} finally {
//释放锁
lock.unlock();
}
}
// 指定位置加入一个元素
public void add(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
if (index > len || index < 0)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+len);
Object[] newElements;
int numMoved = len - index;
if (numMoved == 0)
newElements = Arrays.copyOf(elements, len + 1);
else {
newElements = new Object[len + 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index, newElements, index + 1,
numMoved);
}
newElements[index] = element;
setArray(newElements);
} finally {
lock.unlock();
}
}
// 删除指定位置的元素
public E remove(int index) {
final ReentrantLock lock = this.lock;
//获得锁
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
//如果删除的元素是最后一个,直接复制该元素前的所有元素到新的数组
setArray(Arrays.copyOf(elements, len - 1));
else {
//创建新的数组
Object[] newElements = new Object[len - 1];
//将index+1至最后一个元素向前移动一格
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();
}
}
// 更新指定位置的元素
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
//获得锁
lock.lock();
try {
Object[] elements = getArray();
E oldValue = get(elements, index);
if (oldValue != element) {
int len = elements.length;
//创建新数组
Object[] newElements = Arrays.copyOf(elements, len);
//替换元素
newElements[index] = element;
//将新数组指向原来的引用
setArray(newElements);
} else {
setArray(elements);
}
return oldValue;
} finally {
//释放锁
lock.unlock();
}
}
可以看到,增删改操作使用了锁,重点在 Object[] newElements = Arrays.copyOf(elements, len + 1);这里在生成一个新的数组,然后将新的元素加入到newElements中,再将新的数组替换成老的数组,修改就完成了。整个过程不会影响到读取的线程。当修改完成后,读取线程可以立即察觉到这个修改,因为array被volatile修饰了。
# (5). CopyOnWriteArraySet
# 1. 概述
CopyOnWriteArraySet这是一个HashSet的线程安全的变体,其原理大概可以通俗的理解为:初始化的时候只有一个容器,很常一段时间,这个容器数据、数量等没有发生变化的时候,大家(多个线程),都是读取(假设这段时间里只发生读取的操作)同一个容器中的数据,所以这样大家读到的数据都是唯一、一致、安全的,但是后来有人往里面增加了一个数据,这个时候CopyOnWriteArraySet底层实现添加的原理是先 copy 出一个容器(可以简称副本),再往新的容器里添加这个新的数据,最后把新的容器的引用地址赋值给了之前那个旧的的容器地址,但是在添加这个数据的期间,其他线程如果要去读取数据,仍然是读取到旧的容器里的数据。
CopyOnWriteArraySet是通过CopyOnWriteArrayList实现的,它的API基本上都是通过调用CopyOnWriteArrayList的API来实现的。上面已经详细讲述了CopyOnWriteArrayList的原理及源码,故在此不做过多描述。
# 十五、两个线程交替执行
# 1. SynchronousQueue
public class Demo41 {
public static void main(String[] args) {
SynchronousQueue synchronousQueue = new SynchronousQueue();
new Thread(() -> {
for (int index = 1; index < 27; index++) {
try {
System.out.println(synchronousQueue.take());
synchronousQueue.put(index + "");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
new Thread(() -> {
String str1 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (int index = 0; index < str1.length(); index++) {
try {
synchronousQueue.put(str1.substring(index, index + 1));
System.out.println(synchronousQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
# 2. LinkedTransferQueue
public class Demo42 {
public static void main(String[] args) {
LinkedTransferQueue linkedTransferQueue = new LinkedTransferQueue();
new Thread(() -> {
for (int index = 1; index < 27; index++) {
try {
System.out.println(linkedTransferQueue.take());
linkedTransferQueue.transfer(index + "");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
new Thread(() -> {
String str1 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (int index = 0; index < str1.length(); index++) {
try {
linkedTransferQueue.transfer(str1.substring(index, index + 1));
System.out.println(linkedTransferQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
# 3. ArrayBlockingQueue
public class Demo49 {
public static void main(String[] args) {
ArrayBlockingQueue arrayBlockingQueue1 = new ArrayBlockingQueue(1);
ArrayBlockingQueue arrayBlockingQueue2 = new ArrayBlockingQueue(1);
new Thread(() -> {
for (int index = 1; index < 27; index++) {
try {
System.out.println(arrayBlockingQueue2.take());
arrayBlockingQueue1.put(index);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
new Thread(() -> {
String str1 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (int index = 0; index < str1.length(); index++) {
try {
arrayBlockingQueue2.put(str1.substring(index, index + 1));
System.out.println(arrayBlockingQueue1.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
# 4. Exchanger
public class Demo50 {
public static void main(String[] args) {
Exchanger exchanger = new Exchanger();
new Thread(() -> {
for (int index = 1; index < 27; index++) {
try {
System.out.println(exchanger.exchange(index));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
new Thread(() -> {
String str1 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (int index = 0; index < str1.length(); index++) {
try {
System.out.println(exchanger.exchange(str1.substring(index, index + 1)));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
# 5. obj.wait();obj.notify()
public class Demo43 {
private static Object lock = new Object();
public static void main(String[] args) {
new Thread(() -> {
for (int index = 1; index < 27; index++) {
synchronized (lock) {
try {
lock.wait();
System.out.println(index);
lock.notify();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
new Thread(() -> {
String str1 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (int index = 0; index < str1.length(); index++) {
synchronized (lock) {
try {
System.out.println(str1.substring(index, index + 1));
lock.notify();
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
}
}
# 6. LockSupport
public class Demo44 {
private static Thread thread1 = null;
private static Thread thread2 = null;
public static void main(String[] args) {
thread1 = new Thread(() -> {
for (int index = 1; index < 27; index++) {
LockSupport.park();
System.out.println(index);
LockSupport.unpark(thread2);
}
});
thread2 = new Thread(() -> {
String str1 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (int index = 0; index < str1.length(); index++) {
System.out.println(str1.substring(index, index + 1));
LockSupport.unpark(thread1);
LockSupport.park();
}
});
thread1.start();
thread2.start();
}
}
# 7. ReentrantLock单锁
public class Demo45 {
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Condition condition = lock.newCondition();
new Thread(() -> {
try {
lock.lock();
for (int index = 1; index < 27; index++) {
try {
condition.await();
System.out.println(index);
condition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}finally {
lock.unlock();
}
}).start();
new Thread(() -> {
try {
lock.lock();
String str1 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (int index = 0; index < str1.length(); index++) {
try {
System.out.println(str1.substring(index, index + 1));
condition.signal();
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}finally {
lock.unlock();
}
}).start();
}
}
# 8. ReentrantLock 双锁
public class Demo46 {
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Condition condition1 = lock.newCondition();
Condition condition2 = lock.newCondition();
new Thread(() -> {
try {
lock.lock();
for (int index = 1; index < 27; index++) {
try {
condition1.await();
System.out.println(index);
condition2.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}finally {
lock.unlock();
}
}).start();
new Thread(() -> {
try {
lock.lock();
String str1 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (int index = 0; index < str1.length(); index++) {
try {
System.out.println(str1.substring(index, index + 1));
condition1.signalAll();
condition2.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}finally {
lock.unlock();
}
}).start();
}
}
# 9. 手写CAS
public class Demo47 {
enum T { T1, T2 }
private static volatile T t = T.T2;
public static void main(String[] args) {
new Thread(() -> {
for (int index = 1; index < 27; index++) {
while(t != T.T1){
}
System.out.println(index);
t = T.T2;
}
}).start();
new Thread(() -> {
String str1 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (int index = 0; index < str1.length(); index++) {
while(t != T.T2){
}
System.out.println(str1.substring(index, index + 1));
t = T.T1;
}
}).start();
}
}
# 10. AtomicInteger-CAS
public class Demo48 {
private static AtomicInteger atomicInteger = new AtomicInteger(2);
public static void main(String[] args) {
new Thread(() -> {
for (int index = 1; index < 27; index++) {
while(atomicInteger.get() != 1){
}
System.out.println(index);
atomicInteger.set(2);
}
}).start();
new Thread(() -> {
String str1 = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for (int index = 0; index < str1.length(); index++) {
while(atomicInteger.get() != 2){
}
System.out.println(str1.substring(index, index + 1));
atomicInteger.set(1);
}
}).start();
}
}
# 十六、线程池
# 1. Executor

# 2. Callable

public class CallableTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Callable callable = new Callable() {
@Override
public Object call() throws Exception {
Thread.sleep(2000);
return "hello world";
}
};
ExecutorService executorService = Executors.newCachedThreadPool();
// Future<String> submit = executorService.submit(callable);
Future<String> submit = executorService.submit(() -> {
Thread.sleep(2000);
return "hello world";
});
// 直接输出
System.out.println("继续执行其他方法");
// get方法会进行阻塞等待两秒后输出
System.out.println(submit.get());
executorService.shutdown();
}
}
# 3. ExecutorService
# 4. Future

# 5. FutureTask
public class FutureTaskTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask futureTask = new FutureTask(()->{
Thread.sleep(2000);
return "hello world";
});
new Thread(futureTask).start();
// 阻塞拿值
System.out.println(futureTask.get());
}
}
# 6. CompletableFuture
public class CompletableFutureTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Stopwatch started = Stopwatch.createStarted();
CompletableFuture c1 = CompletableFuture.supplyAsync(CompletableFutureTest::get1);
CompletableFuture c2 = CompletableFuture.supplyAsync(CompletableFutureTest::get2);
CompletableFuture c3 = CompletableFuture.supplyAsync(CompletableFutureTest::get3);
CompletableFuture.allOf(c1, c2, c3).join();
System.out.println(c1.get());
System.out.println(c2.get());
System.out.println(c3.get());
System.out.println(started.elapsed(TimeUnit.MILLISECONDS));
c1 = CompletableFuture.supplyAsync(CompletableFutureTest::get1);
c2 = CompletableFuture.supplyAsync(CompletableFutureTest::get2);
c3 = CompletableFuture.supplyAsync(CompletableFutureTest::get3);
started.reset().start();
Object join = CompletableFuture.anyOf(c1, c2, c3).join();
System.out.println(join);
System.out.println(started.elapsed(TimeUnit.MILLISECONDS));
CompletableFuture.supplyAsync(CompletableFutureTest::get1)
.thenApply(String::valueOf)
.thenApply(str -> "price: " + str)
.thenAccept(System.out::println)
.join();
}
private static String get3(){
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "3";
}
private static String get2(){
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "2";
}
private static String get1(){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "1";
}
}
# 7. Executors:线程池的工厂
有任务队列,生命周期管理
线程个数计算公式:N(threads) = N(CPU) * U(CPU) * (1 + W/C)
N(CPU)是处理器的核的数目,可以通过
Runtime.getRuntime().availableProcessors()得到U(CPU)是期望的CPU利用率(该值应该介于0和1之间)
W/C是等待时间与计算时间的比率
# 1. newSingleThreadExecutor()
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
# 2. newSingleThreadExecutor(ThreadFactory)
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
# 3. newCachedThreadPool()
任务来的忽高忽低的时候使用;自己估算,精确定义
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
# 4. newCachedThreadPool(ThreadFactory)
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
# 5. newFixedThreadPool(int)
任务来的很平稳的时候使用;自己估算,精确定义
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
# 6. newFixedThreadPool(int, ThreadFactory)
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
# 7. newScheduledThreadPool(int)
定时任务线程池
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
# 8. newScheduledThreadPool(int, ThreadFactory)
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
# 9. newSingleThreadScheduledExecutor()
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
# 10. newSingleThreadScheduledExecutor(ThreadFactory)
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1, threadFactory));
}
# 11. newWorkStealingPool()
每一个线程都有自己单独的队列,当自己线程中队列的任务执行完成之后,会去另外的线程中拿任务进行执行
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
# 12. newWorkStealingPool(int)
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
# 8. ThreadPoolExecutor
当线程达到核心线程数是,如果核心线程都在忙,当来了一个任务,加入任务队列,当任务队列满了的时候,新开启一个线程,等到线程数达到最大线程数时,执行拒绝策略。
# 1. int corePoolSize
核心线程数:
# 2. int maximumPoolSize
最大线程数:
# 3. long keepAliveTime
空闲多长时间:
# 4. TimeUnit unit
时间的单位:
# 5. BlockingQueue workQueue
执行任务的队列:
# 6. ThreadFactory threadFactory
创建线程池的工厂:
自定义线程工厂需要实现:ThreadFactory 接口
# 7. RejectedExecutionHandler handler
拒绝策略:线程都在忙,任务队列满了的时候,会进行触发。
# 1. AbortPolicy
抛异常
# 2. DiscardPolicy
扔掉,不抛异常
# 3. DiscardOldestPolicy
扔掉排队时间最久的
# 4. CallerRunsPolicy
调用者自己处理任务
# 5. 自定义
需要实现 RejectedExecutionHandler 接口
# 8. 源码剖析
# 1. 常用变量的解释
// 1. `ctl`,可以看做一个int类型的数字,高3位表示线程池状态,低29位表示worker数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 2. `COUNT_BITS`,`Integer.SIZE`为32,所以`COUNT_BITS`为29
private static final int COUNT_BITS = Integer.SIZE - 3;
// 3. `CAPACITY`,线程池允许的最大线程数。1左移29位,然后减1,即为 2^29 - 1
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
// 4. 线程池有5种状态,按大小排序如下:RUNNING < SHUTDOWN < STOP < TIDYING < TERMINATED
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
// 5. `runStateOf()`,获取线程池状态,通过按位与操作,低29位将全部变成0
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 6. `workerCountOf()`,获取线程池worker数量,通过按位与操作,高3位将全部变成0
private static int workerCountOf(int c) { return c & CAPACITY; }
// 7. `ctlOf()`,根据线程池状态和线程池worker数量,生成ctl值
private static int ctlOf(int rs, int wc) { return rs | wc; }
/*
* Bit field accessors that don't require unpacking ctl.
* These depend on the bit layout and on workerCount being never negative.
*/
// 8. `runStateLessThan()`,线程池状态小于xx
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
// 9. `runStateAtLeast()`,线程池状态大于等于xx
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
# 2. 构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// 基本类型参数校验
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
// 空指针校验
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
// 根据传入参数`unit`和`keepAliveTime`,将存活时间转换为纳秒存到变量`keepAliveTime `中
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
# 3. 提交执行task的过程
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
// worker数量比核心线程数小,直接创建worker执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// worker数量超过核心线程数,任务直接进入队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 线程池状态不是RUNNING状态,说明执行过shutdown命令,需要对新加入的任务执行reject()操作。
// 这儿为什么需要recheck,是因为任务入队列前后,线程池的状态可能会发生变化。
if (! isRunning(recheck) && remove(command))
reject(command);
// 这儿为什么需要判断0值,主要是在线程池构造方法中,核心线程数允许为0
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 如果线程池不是运行状态,或者任务进入队列失败,则尝试创建worker执行任务。
// 这儿有3点需要注意:
// 1. 线程池不是运行状态时,addWorker内部会判断线程池状态
// 2. addWorker第2个参数表示是否创建核心线程
// 3. addWorker返回false,则说明任务执行失败,需要执行reject操作
else if (!addWorker(command, false))
reject(command);
}
# 4. addworker源码解析
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
// 外层自旋
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 这个条件写得比较难懂,我对其进行了调整,和下面的条件等价
// (rs > SHUTDOWN) ||
// (rs == SHUTDOWN && firstTask != null) ||
// (rs == SHUTDOWN && workQueue.isEmpty())
// 1. 线程池状态大于SHUTDOWN时,直接返回false
// 2. 线程池状态等于SHUTDOWN,且firstTask不为null,直接返回false
// 3. 线程池状态等于SHUTDOWN,且队列为空,直接返回false
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
// 内层自旋
for (;;) {
int wc = workerCountOf(c);
// worker数量超过容量,直接返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 使用CAS的方式增加worker数量。
// 若增加成功,则直接跳出外层循环进入到第二部分
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
// 线程池状态发生变化,对外层循环进行自旋
if (runStateOf(c) != rs)
continue retry;
// 其他情况,直接内层循环进行自旋即可
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
// worker的添加必须是串行的,因此需要加锁
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
// 这儿需要重新检查线程池状态
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// worker已经调用过了start()方法,则不再创建worker
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// worker创建并添加到workers成功
workers.add(w);
// 更新`largestPoolSize`变量
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 启动worker线程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// worker线程启动失败,说明线程池状态发生了变化(关闭操作被执行),需要进行shutdown相关操作
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
# 5. 线程池worker任务单元
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
// 这儿是Worker的关键所在,使用了线程工厂创建了一个线程。传入的参数为当前worker
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
// 省略代码...
}
# 6. 核心线程执行逻辑-runworker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// 调用unlock()是为了让外部可以中断
w.unlock(); // allow interrupts
// 这个变量用于判断是否进入过自旋(while循环)
boolean completedAbruptly = true;
try {
// 这儿是自旋
// 1. 如果firstTask不为null,则执行firstTask;
// 2. 如果firstTask为null,则调用getTask()从队列获取任务。
// 3. 阻塞队列的特性就是:当队列为空时,当前线程会被阻塞等待
while (task != null || (task = getTask()) != null) {
// 这儿对worker进行加锁,是为了达到下面的目的
// 1. 降低锁范围,提升性能
// 2. 保证每个worker执行的任务是串行的
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
// 如果线程池正在停止,则对当前线程进行中断操作
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
// 执行任务,且在执行前后通过`beforeExecute()`和`afterExecute()`来扩展其功能。
// 这两个方法在当前类里面为空实现。
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
// 帮助gc
task = null;
// 已完成任务数加一
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 自旋操作被退出,说明线程池正在结束
processWorkerExit(w, completedAbruptly);
}
}
# 7. 设置核心线程允许退出
// true为允许退出,false我不允许退出
threadPoolExecutor.allowCoreThreadTimeOut(true);
# 9. ForkJoinPool
# 1. 简介
从JDK1.7开始,Java提供ForkJoin框架用于并行执行任务,它的思想就是讲一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。
# 2. ForkJoinPool
既然任务是被逐渐的细化的,那就需要把这些任务存在一个池子里面,这个池子就是ForkJoinPool,它与其它的ExecutorService区别主要在于它使用“工作窃取“,那什么是工作窃取呢?
一个大任务会被划分成无数个小任务,这些任务被分配到不同的队列,这些队列有些干活干的块,有些干得慢。于是干得快的,一看自己没任务需要执行了,就去隔壁的队列里面拿去任务执行。
# 3. ForkJoinTask
ForkJoinTask就是ForkJoinPool里面的每一个任务。他主要有两个子类:RecursiveAction 和 RecursiveTask。然后通过fork()方法去分配任务执行任务,通过join()方法汇总任务结果,
这就是整个过程的运用。他有两个子类,使用这两个子类都可以实现我们的任务分配和计算。
- RecursiveAction 一个递归无结果的ForkJoinTask(没有返回值)
- RecursiveTask 一个递归有结果的ForkJoinTask(有返回值)
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务。
# 4. RecursiveTask :有返回结果
第一步:创建 AddTask 子类在ForkJoinTest中
static class AddTask extends RecursiveTask<Long> {
private static final long serialVersionUID = 1L;
int start, end;
AddTask(int s, int e) {
start = s;
end = e;
}
@Override
protected Long compute() {
if(end-start <= MAX_NUM) {
long sum = 0L;
for(int i=start; i<end; i++) sum += nums[i];
return sum;
}
int middle = start + (end-start)/2;
AddTask subTask1 = new AddTask(start, middle);
AddTask subTask2 = new AddTask(middle, end);
subTask1.fork();
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
在这个方法中我们传进去数据,然后使用二分法继续分配给子任务,当任务小的不能再分,那就汇总返回。
第二步在ForkJoinTest中去测试
static int[] nums = new int[1000000];
static final int MAX_NUM = 50000;
static Random r = new Random();
static {
for(int i=0; i<nums.length; i++) {
nums[i] = r.nextInt(100);
}
System.out.println("---" + Arrays.stream(nums).sum()); //stream api
}
public static void main(String[] args) throws IOException {
ForkJoinPool fjp = new ForkJoinPool();
AddTask task = new AddTask(0, nums.length);
fjp.execute(task);
long result = task.join();
System.out.println(result);
System.in.read();
}
在这个类中我们定义了一个阈值,然后创建一个ForkJoinPool,在这个池子中新建我们刚刚创建的Task任务,最终返回我们结果。
# 5. RecursiveAction:无返回结果
第一步:创建 AddAction 子类在ForkJoinTest中
static class AddAction extends RecursiveAction {
int start, end;
AddAction(int s, int e) {
start = s;
end = e;
}
@Override
protected void compute() {
if(end-start <= MAX_NUM) {
long sum = 0L;
for(int i=start; i<end; i++) sum += nums[i];
System.out.println("from:" + start + " to:" + end + " = " + sum);
} else {
int middle = start + (end-start)/2;
AddAction subTask1 = new AddAction(start, middle);
AddAction subTask2 = new AddAction(middle, end);
subTask1.fork();
subTask2.fork();
}
}
}
在这个方法中我们不需要有return语句。过程和之前的RecursiveTask类似。
第二步在ForkJoinTest中去测试
static int[] nums = new int[1000000];
static final int MAX_NUM = 50000;
static Random r = new Random();
static {
for(int i=0; i<nums.length; i++) {
nums[i] = r.nextInt(100);
}
System.out.println("---" + Arrays.stream(nums).sum()); //stream api
}
public static void main(String[] args) throws IOException {
ForkJoinPool fjp = new ForkJoinPool();
AddAction task = new AddAction(0, nums.length);
fjp.execute(task);
System.in.read();
}
现在不管我们输出多少次都可以有返回结果了。
ForkJoinTask在执行的时候可能会抛出异常,在主线程中是无法直接获取的,但是可以通过ForkJoinTask提供的isCompletedAbnormally() 方法来检查任务是否已经抛出异常或已经被取消了。
# 十六、Disruptor
# 1. 概述
Disruptor是一个性能极强的异步消息处理框架,可以认为它是线程间通信高效低延时的内存消息组件,它最大的特点是高性能,其LMAX架构可以获得每秒6百万订单,用1微秒的延迟获得吞吐量为100K+。实际上它是拿内存换取处理高性能的低延迟的处理熟速度,(实际上这个框架在log4j,以及activeMQ源码扩展中有使用)
# 2. Disruptor的特点
对比ConcurrentLinkedQueue : 链表实现 JDK中没有ConcurrentArrayQueue Disruptor是数组实现的 无锁,高并发,使用环形Buffer,直接覆盖(不用清除)旧的数据,降低GC频率 实现了基于事件的生产者消费者模式(观察者模式)
# 3. RingBuffer
环形队列 RingBuffer的序号,指向下一个可用的元素 采用数组实现,没有首尾指针 对比ConcurrentLinkedQueue,用数组实现的速度更快
假如长度为8,当添加到第12个元素的时候在哪个序号上呢?用12%8决定 当Buffer被填满的时候到底是覆盖还是等待,由Producer决定 长度设为2的n次幂,利于二进制计算,例如:12%8 = 12 & (8 - 1) pos = num & (size -1)
# 4. Disruptor开发步骤
# 1. 定义Event - 队列中需要处理的元素
public class LongEvent {
private long value;
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
@Override
public String toString() {
return "LongEvent{" +
"value=" + value +
'}';
}
}
# 2. 定义Event工厂,用于填充队列
这里牵扯到效率问题:disruptor初始化的时候,会调用 Event 工厂,对 ringBuffer 进行内存的提前分配 GC产频率会降低
public class LongEventFactory implements EventFactory<LongEvent> {
@Override
public LongEvent newInstance() {
return new LongEvent();
}
}
# 3. 定义EventHandler(消费者),处理容器中的元素
public class LongEventHandler implements EventHandler<LongEvent> {
public static long count = 0;
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch) throws Exception {
count ++;
System.out.println("[" + Thread.currentThread().getName() + "]" + event + " 序号:" + sequence);
}
}
# 5. 事件发布模板
long sequence = ringBuffer.next(); // Grab the next sequence
try {
LongEvent event = ringBuffer.get(sequence); // Get the entry in the Disruptor
// for the sequence
event.set(8888L); // Fill with data
} finally {
ringBuffer.publish(sequence);
}
# 6. 使用EventTranslator发布事件
//===============================================================
EventTranslator<LongEvent> translator1 = new EventTranslator<LongEvent>() {
@Override
public void translateTo(LongEvent event, long sequence) {
event.set(8888L);
}
};
ringBuffer.publishEvent(translator1);
//===============================================================
EventTranslatorOneArg<LongEvent, Long> translator2 = new EventTranslatorOneArg<LongEvent, Long>() {
@Override
public void translateTo(LongEvent event, long sequence, Long l) {
event.set(l);
}
};
ringBuffer.publishEvent(translator2, 7777L);
//===============================================================
EventTranslatorTwoArg<LongEvent, Long, Long> translator3 = new EventTranslatorTwoArg<LongEvent, Long, Long>() {
@Override
public void translateTo(LongEvent event, long sequence, Long l1, Long l2) {
event.set(l1 + l2);
}
};
ringBuffer.publishEvent(translator3, 10000L, 10000L);
//===============================================================
EventTranslatorThreeArg<LongEvent, Long, Long, Long> translator4 = new EventTranslatorThreeArg<LongEvent, Long, Long, Long>() {
@Override
public void translateTo(LongEvent event, long sequence, Long l1, Long l2, Long l3) {
event.set(l1 + l2 + l3);
}
};
ringBuffer.publishEvent(translator4, 10000L, 10000L, 1000L);
//===============================================================
EventTranslatorVararg<LongEvent> translator5 = new EventTranslatorVararg<LongEvent>() {
@Override
public void translateTo(LongEvent event, long sequence, Object... objects) {
long result = 0;
for(Object o : objects) {
long l = (Long)o;
result += l;
}
event.set(result);
}
};
ringBuffer.publishEvent(translator5, 10000L, 10000L, 10000L, 10000L);
# 7. 使用Lamda表达式
public class Main03 {
public static void main(String[] args) {
//must be power of 2
int ringBufferSize = 1024;
Disruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new, ringBufferSize, Executors.defaultThreadFactory());
disruptor.handleEventsWith((longEvent, sequence, endOfBatch) -> System.out.println(longEvent.getValue()));
disruptor.start();
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
//
ringBuffer.publishEvent((event, sequence) -> event.setValue(888L));
ringBuffer.publishEvent((event, sequence, l) -> event.setValue(l), 10000L);
ringBuffer.publishEvent((event, sequence, l1, l2) -> event.setValue(l1 + l2), 10000L, 20000L);
ringBuffer.publishEvent((event, sequence, l1, l2, l3) -> event.setValue(l1 + l2 + l3), 10000L, 20000L, 30000L);
ringBuffer.publishEvent((event, sequence, array) -> {
long sum = 0L;
for (int index = 0, length = array.length; index < length; index++) {
sum += (Long) array[index];
}
event.setValue(sum);
}, 10000L, 20000L, 30000L, 40000L);
//
disruptor.shutdown();
}
}
# 8. ProducerType生产者线程模式
ProducerType有两种模式 Producer.MULTI和Producer.SINGLE 默认是MULTI,表示在多线程模式下产生sequence 如果确认是单线程生产者,那么可以指定SINGLE,效率会提升 如果是多个生产者(多线程),但模式指定为SINGLE,会出什么问题呢?
# 9. 等待策略
- (常用)BlockingWaitStrategy:通过线程阻塞的方式,等待生产者唤醒,被唤醒后,再循环检查依赖的sequence是否已经消费。
- BusySpinWaitStrategy:线程一直自旋等待,可能比较耗cpu
- LiteBlockingWaitStrategy:线程阻塞等待生产者唤醒,与BlockingWaitStrategy相比,区别在signalNeeded.getAndSet,如果两个线程同时访问一个访问waitfor,一个访问signalAll时,可以减少lock加锁次数.
- LiteTimeoutBlockingWaitStrategy:与LiteBlockingWaitStrategy相比,设置了阻塞时间,超过时间后抛异常。
- PhasedBackoffWaitStrategy:根据时间参数和传入的等待策略来决定使用哪种等待策略
- TimeoutBlockingWaitStrategy:相对于BlockingWaitStrategy来说,设置了等待时间,超过后抛异常
- (常用)YieldingWaitStrategy:尝试100次,然后Thread.yield()让出cpu
- (常用)SleepingWaitStrategy : sleep
- 支持自定义,需要实现
WaitStrategy接口
# 10. 消费者异常处理
- 默认:disruptor.setDefaultExceptionHandler()
- 覆盖:disruptor.handleExceptionFor().with()