# 重要知识点
# JS兼容性写法
# 获取样式
// 定义一个方法,该方法的功能是获取内部样式和外部样式,适用于任何浏览器
function getStyle(ele, cssName) {
// 判断是哪个浏览器打开的该页面
if (ele.currentStyle == undefined) { // 谷歌浏览器
return window.getComputedStyle(ele, null)[cssName];
} else { // IE低版本浏览器
return ele.currentStyle[cssName] :
}
// 或者
ele.currentStyle ? ele.currentStyle[cssName] : window.getComputedStyle(ele, null)[cssName];
}
# 获取页面宽度
document.documentElement.clientWidth || document.body.clientWidth || window.innerWidth
# 获取页面的高度
document.documentElement.clientHeight || document.body.clientHieght || window.innerHeight
# 获取容器中被卷上去的高度
document.documentElement.scrollTop || document.body.scrollTop
# 获取容器中被卷到左边的宽度
document.documentElement.scrollLeft || document.body.scrollLeft
# dom2级事件处理函数的兼容方式
// 定义一个方法,功能是添加事件(解决DOM2级事件处理程序不兼容的问题)
function addEvent(ele, eventName, callback, bool) {
if (ele.attachEvent == undefined) {
ele.addEventListener(eventName, callback, bool);
} else {
ele.attachEvent('on' + eventName, callback);
}
}
// 定义一个方法,功能是删除事件(解决DOM2级事件处理程序在删除事件时不兼容的问题)
function removeEvent(ele, eventName, callback, bool) {
if (ele.detachEvent == undefined) {
ele.removeEventListener(eventName, callback, bool);
} else {
ele.detachEvent('on' + eventName, callback);
}
}
# 关闭鼠标右键默认行为的兼容写法
document.oncontextmenu = function(e) {
// 获取事件对象兼容写法
e = e || window.event;
if (e.preventDefault == undefined) {
e.returnValue = false; // IE支持
} else {
e.preventDefault();
}
// 或者
e.preventDefault == undefined ? e.returnValue = false : e.preventDefault();
// 执行其他右键操作
}
# 从事件对象获取点击对象的兼容写法
document.oncontextmenu = function(e) {
// 获取事件对象兼容写法
e = e || window.event;
var obj = e.target || e.srcElement;
console.log(obj.innerHTML);
}
# 阻断事件流
document.oncontextmenu = function(e) {
// 阻断事件流的兼容写法
e = e || window.event;
if (e.stopPropagation == undefined) {
e.cancelBubble = true; // IE支持
} else {
e.stopPropagation();
}
// 或者
e.stopPropagation == undefined ? e.cancelBubble = true : e.stopPropagation();
// 执行其他右键操作
}
# eureka自我保护机制
# 自我保护背景
首先对Eureka注册中心需要了解的是Eureka各个节点都是平等的,没有ZK中角色的概念, 即使N-1个节点挂掉也不会影响其他节点的正常运行。
默认情况下,**如果Eureka Server在一定时间内(默认90秒)没有接收到某个微服务实例的心跳,Eureka Server将会移除该实例。**但是当网络分区故障发生时,微服务与Eureka Server之间无法正常通信,而微服务本身是正常运行的,此时不应该移除这个微服务,所以引入了自我保护机制。
# 自我保护机制
官方对于自我保护机制的定义:
自我保护模式正是一种针对网络异常波动的安全保护措施,使用自我保护模式能使Eureka集群更加的健壮、稳定的运行。
自我保护机制的工作机制是:如果在15分钟内超过85%的客户端节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,Eureka Server自动进入自我保护机制,此时会出现以下几种情况:
- Eureka Server不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka Server仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上,保证当前节点依然可用
- 当网络稳定时,当前Eureka Server新的注册信息会被同步到其它节点中
因此Eureka Server可以很好的应对因网络故障导致部分节点失联的情况,而不会像ZK那样如果有一半不可用的情况会导致整个集群不可用而变成瘫痪。
# 自我保护开关
Eureka自我保护机制,通过配置 eureka.server.enable-self-preservation 来true打开/false禁用自我保护机制,默认打开状态,建议生产环境打开此配置。
# 开发环境配置
开发环境中如果要实现服务失效能自动移除,只需要修改以下配置。
注册中心关闭自我保护机制,修改检查失效服务的时间
eureka: server: enable-self-preservation: false eviction-interval-timer-in-ms: 3000微服务修改减短服务心跳的时间
eureka: instance: # 默认90秒 lease-expiration-duration-in-seconds: 90 # 默认30秒 lease-renewal-interval-in-seconds: 30
# @Autowired注解与@Resource注解的区别
# 相同点
@Resource的作用相当于@Autowired,均可标注在字段或属性的setter方法上。
# 不同点
- 提供方:@Autowired是由Spring提供;@Resource是由J2EE提供,需要JDK1.6及以上
- 注入方式:@Autowired只按照byType 注入;@Resource默认按byName自动注入,也提供按照byType 注入;
- 属性:@Autowired按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false。如果我们想使用按名称装配,可以结合 @Qualifier 注解一起使用。@Resource有两个中重要的属性:name和type。name属性指定byName,如果没有指定name属性,当注解标注在字段上,即默认取字段的名称作为bean名称寻找依赖对象,当注解标注在属性的setter方法上,即默认取属性名作为bean名称寻找依赖对象。需要注意的是,@Resource如果没有指定name属性,并且按照默认的名称仍然找不到依赖对象时, @Resource注解会回退到按类型装配。但一旦指定了name属性,就只能按名称装配了。
# @Resource装配顺序
- 如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常
- 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常
- 如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常
- 如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配;
推荐使用@Resource注解在字段上,这样就不用写setter方法了.并且这个注解是属于J2EE的,减少了与Spring的耦合,这样代码看起就比较优雅 。
# 秒杀的分布式锁场景
# 前提
已有的系统功能完善,稳定。
# 特点
稳定,短时间,高并发
# 目标
不多卖,不少卖,服务的可用性,服务器响应速度快
# 实现流程

# 如何提高加锁阻塞的效率?
- 库存分段,10个10个的锁,并发效率提高了10倍
# 秒杀场景优化思路
- 请求的数据量要少(接口数据少)
- 请求的路径要端(减少链路调用次数)
- 相关依赖要少
- 不要单点
- CDN分发
- 动静分离(静态数据做缓存,减少服务器压力)
- 识别热点数据,为系统扩容做准备(当前置的耗费资源少的接口被频繁调用时,说明热点数据快要来了)
- 使用消息队列进行削峰,前面简单处理一下,就扔到MQ里,后面进行排队,慢慢的去进行消费
- 答题,输验证码
- 网络(网络请求转发)、CPU(优化程序的并发)、内存(自己的内存+Redis)、硬盘(MySQL)
# Object类的方法说明
# toString() 方法
返回对象的描述信息:全类名@哈希码值的十六进制形式
编程规范:开发者要对自定义的类重写toString(),对对象做详细的说明
# hashCode() 方法
返回该对象的哈希码值,int类型; 同一个对象的哈希码值是唯一的。java规定如果两个对象equals返回true,那么这两个对象的hashCode码必须一致。
编程规范: 一般重写了类的equals方法后,都会重写它的hashCode方法
# toString和hashCode哈希码的联系
他们之间是十六进制与十进制之间的关系!
# equals() 方法
默认比较的是两个对象的内存值,相等返回 true,否则 false。可重写equals方法。
问题:既然equals比较的是对象的内存值,那我们在开发的时候经常使用 equals() 方法比较两个字符串是否相等,为什么?
String 重写了Object类的equals方法,比较的是字符串内容是否相等。
# equals 和 ==
# ==
- 比较基本数据类型,比较的是值是否相等。
- 比较引用数据类型,比较的是地址是否相等。
# equals
- 比较的是两个对象的地址值是否相等,此时等价 ==。
- 重写后按照重写后的方式比较。
# equals 和 hashCode 方法
# 作用
都是用于比较java对象是否一致
- equals:重写的equal() 方法里一般比较全面、复杂,效率低。
- hashCode:生成一个int类型的hash值。效率高,但hash值可能不唯一。
# 问题
由于hash值的生成问题,可能导致不同的对象,hash值相同。
# 结论
- equal()对比绝对可靠(equal()相等的两个对象他们的hashCode()肯定相等)
- hashCode()不是绝对可靠的(hashCode()相等的两个对象他们的equal()不一定相等)
# 使用
所有对于需要大量并且快速的对比的话如果都用equal()去做显然效率太低,所以每当需要对比的时候,首先用hashCode()去对比,如果hashCode()不一样,则表示这两个对象肯定不相等(也就是不必再用equal()去再对比了),如果hashCode()相同,此时再对比他们的equal(),如果equal()也相同,则表示这两个对象是真的相同了,这样既能大大提高了效率也保证了对比的绝对正确性!
# String的hashcde算法
# hashcde源码
/** The value is used for character storage. */
private final char value[]; //将字符串截成的字符数组
/** Cache the hash code for the string */
private int hash; // Default to 0 用以缓存计算出的hashcode值
/**
* Returns a hash code for this string. The hash code for a
* <code>String</code> object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using <code>int</code> arithmetic, where <code>s[i]</code> is the
* <i>i</i>th character of the string, <code>n</code> is the length of
* the string, and <code>^</code> indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
# 举例说明
String msg = "abcd"; // 此时value[] = {'a','b','c','d'} 因此
for循环会执行4次
第一次:h = 31*0 + a = 97
第二次:h = 31*97 + b = 3105
第三次:h = 31*3105 + c = 96354
第四次:h = 31*96354 + d = 2987074
由以上代码计算可以算出 msg 的hashcode = 2987074 刚好与 System.err.println(new String("abcd").hashCode()); 进行验证
在源码的hashcode的注释中还提供了一个多项式计算方式:
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
s[0] :表示字符串中指定下标的字符
n:表示字符串中字符长度
a*31^3 + b*31^2 + c*31^1 + d = 2987074 + 94178 + 3069 + 100 = 2987074 ;
# MQ100%投递及消费
# 核心点
- 消息收到先落地
- 消息超时、重传、确认保证消息必达
# MQ投递消息
- 客户端给MQ服务器发送消息
- MQ服务器将消息落地,落地后即为发送成功
- MQ服务器将应答发送给MQ客户端
说明:MQ投递消息的1或者2或者3如果丢失或者超时,MQ客户端内的定时器会重发消息,直到期望收到3,如果重传N次后还未收到,则回调发送失败(说明此时网络可能存在问题了;如果要求100%投递成功,可以先把失败的消息存储到一个第三方介质上,过段时间网络恢复了再进行消息投递)需要注意的是,这个过程中MQ服务器可能会收到同一条消息的多次重发
# MQ消费消息
- MQ服务器将消息发送给MQ客户端
- MQ客户端回复MQ服务器接受完成
- MQ服务器收到ACK应答,将已经落地的消息删除,完成消息的可靠传递
说明:MQ消费消息的1或者2或者3如果丢失或者超时,MQ服务器内的定时器会重发消息,直到收到2并且成功执行3,这个过程可能会重发很多次消息,一般采用指数退避的策略,先隔x秒重发,2x秒重发,4x秒重发,以此类推,需要注意的是,这个过程中MQ客户端也可能会收到同一条消息的多次重发
MQ投递消息与MQ消费消息如何进行消息去重,需要进行MQ架构幂等性设计!!!
# 幂等的设计思路
# MQ幂等设计
# MQ投递消息的幂等设计
此时重发的是MQ客户端,消息处理的是MQ服务器端,为了避免步骤2落地重复的消息,对每条消息,MQ系统内部必须生成一个内部的消息id(inner-msg-id),作为去重和幂等的依据,这个内部消息ID的特性是:
- 全局唯一
- MQ生成,具备业务无关性,对消息发送发和消息接收方屏蔽
有了这个inner-msg-id,就能保证MQ投递消息的重发,只有1条消息落到MQ服务器中,实现MQ消息投递的幂等。
# MQ消费消息的幂等设计
此时重发的是MQ服务器,消息的处理是消息消费业务方,消息重发势必会导致业务方重复消费,为了保证业务幂等性,业务消息体中,必须有一个biz-id,作为去重和幂等的依据,这个业务id的特性是:
- 对于同一个业务场景,全局唯一
- 由业务消息发送方生成,业务相关,对MQ透明
- 由业务消息消费方负责判重,以保证幂等
最常见的业务id有:支付id,订单id,帖子id等;有了这个业务id,才能够保证MQ消息消费业务方即使收到重复的消息,也只有1条被消费,保证了幂等。
# MQ幂等设计总结
- MQ投递消息
- MQ客户端内部或者MQ服务器生成inner-msg-id,保证MQ投递消息幂等
- 这个id全局唯一,业务无关,由MQ保证
- MQ消费消息
- 业务发送发带入biz-id,业务接收方去重保证幂等
- 这个id对业务唯一,业务相关,对MQ透明
结论:幂等性,不仅对MQ有要求,对业务上下游也有要求。
# 服务接口幂等设计
# 保证接口幂等性的要求
- 对于每个请求必须有一个唯一的标识
- 每次处理完请求之后,必须有一个记录标识这个请求处理过了
- 每次接收请求需要进行判断之前是否处理过的逻辑处理
# 用户重复提交问题,Nginx重试,Ribbon重试
这个问题等同于表单重复提交,一般的解决思路是token机制。
也就是说在表单提交之前需要向后端申请token,后端返给前端token的同时需要把token保存到redis中,并设置超时时间。请求接口时,将此token放在header中或者作为参数,后端判断token是否存在,存在则删除token并正常处理业务逻辑;否则返回重复提交提示。
# 分布式锁
# 分布式锁的特点
- 互斥性:任意时刻,只能有一个客户端获取锁,不能同时有两个客户端获取到锁
- 安全性:锁只能被持有该锁的客户端删除,不能由其它客户端删除
- 防死锁:获取锁的客户端因为某些原因(如down机等),需要设置一个策略把锁释放掉,否则其他客户端再也无法获取到该锁
- 容错性:当部分服务节点down机时,客户端仍然能够获取锁和释放锁
# 基于数据库的锁
利用数据库的行级锁实现
# 基于Zookeeper的分布式锁
利用zk临时顺序节点的特性来实现
# 基于Redis单机的锁
使用redis set nx命令来实现
# 基于Redisson分布式锁
多个redis实例之间毫无任何关系,加锁成功的个数超过半数+1,即获得锁成功
# feign调用全过程
https://www.cnblogs.com/rickiyang/p/11802487.html
Feign是一个声明式的REST客户端,它的目的就是让REST调用更加简单。通过提供HTTP请求模板,让Ribbon请求的书写更加简单和便捷。另外,在Feign中整合了Ribbon,从而不需要显式的声明Ribbon的jar包。
注 : 如果通过Java代码进行了配置,又通过配置文件进行了配置,则配置文件的中的Feign配置会覆盖Java代码的配置。但也可以设置feign.client.defalult-to-properties=false,禁用掉feign配置文件的方式让Java配置生效。
# 首先调用接口为什么会直接发送请求?
原因就是Spring扫描了@FeignClient注解,并且根据配置的信息生成代理类,调用的接口实际上调用的是生成的代理类。
# 其次请求是如何被Feign接管的?
- Feign通过扫描
@EnableFeignClients注解中配置包路径,扫描@FeignClient注解并将注解配置的信息注入到Spring容器中,类型为FeignClientFactoryBean; - 然后通过
FeignClientFactoryBean的getObject()方法得到不同动态代理的类并为每个方法创建一个SynchronousMethodHandler对象; - 为每一个方法创建一个动态代理对象, 动态代理的实现是
ReflectiveFeign.FeignInvocationHanlder,代理被调用的时候,会根据当前调用的方法,转到对应的SynchronousMethodHandler。
这样我们发出的请求就能够被已经配置好各种参数的Feign handler进行处理,从而被Feign托管。
# 请求如何被Feign分发的?
上一个问题已经回答了Feign将每个方法都封装成为代理对象,那么当该方法被调用时,真正执行逻辑的是封装好的代理对象进行处理,执行对应的服务调用逻辑。
# hystrix 熔断的原理
https://www.cnblogs.com/rickiyang/p/11853315.html
Hystrix的作用就是处理服务依赖,帮助我们做服务治理和服务监控。
# Hystrix是如何解决依赖隔离呢?
- Hystrix使用命令模式
HystrixCommand(Command)包装依赖调用逻辑,每个命令在单独线程中/信号授权下执行。 - 可配置依赖调用超时时间,超时时间一般设为比99.5%平均时间略高即可。当调用超时时,直接返回或执行fallback逻辑。
- 为每个依赖提供一个小的线程池(或信号),如果线程池已满调用将被立即拒绝,默认不采用排队,加速失败判定时间。
- 依赖调用结果分:成功,失败(抛出异常),超时,线程拒绝,短路。 请求失败(异常,拒绝,超时,短路)时执行fallback(降级)逻辑。
- 提供熔断器组件,可以自动运行或手动调用,停止当前依赖一段时间(10秒),熔断器默认错误率阈值为50%,超过将自动运行。
Hystrix现在已经停止更新,意味着你在生产环境如果想使用的话就要考虑现有功能是否能够满足需求。另外开源界现在也有别的更优秀的服务治理组件:Resilience4j 和 Sentinel
# Hystrix如何实现依赖隔离
# 命令模式
将所有请求外部系统(或者叫依赖服务)的逻辑封装到 HystrixCommand 或者 HystrixObservableCommand 对象中。Run()方法为实现业务逻辑,这些逻辑将会在独立的线程中被执行当请求依赖服务时出现拒绝服务、超时或者短路(多个依赖服务顺序请求,前面的依赖服务请求失败,则后面的请求不会发出)时,执行该依赖服务的失败回退逻辑(Fallback)。
# 隔离策略
Hystrix 为每个依赖项维护一个小线程池(或信号量);如果它们达到设定值(触发隔离),则发往该依赖项的请求将立即被拒绝,执行失败回退逻辑(Fallback),而不是排队。
# 线程隔离
第三方客户端(执行Hystrix的run()方法)会在单独的线程执行,会与调用的该任务的线程进行隔离,以此来防止调用者调用依赖所消耗的时间过长而阻塞调用者的线程。使用线程隔离的好处:
- 应用程序可以不受失控的第三方客户端的威胁,如果第三方客户端出现问题,可以通过降级来隔离依赖。
- 当失败的客户端服务恢复时,线程池将会被清除,应用程序也会恢复,而不至于使整个Tomcat容器出现故障。
- 如果一个客户端库的配置错误,线程池可以很快的感知这一错误(通过增加错误比例,延迟,超时,拒绝等),并可以在不影响应用程序的功能情况下来处理这些问题(可以通过动态配置来进行实时的改变)。
- 如果一个客户端服务的性能变差,可以通过改变线程池的指标(错误、延迟、超时、拒绝)来进行属性的调整,并且这些调整可以不影响其他的客户端请求。
- 简而言之,由线程供的隔离功能可以使客户端和应用程序优雅的处理各种变化,而不会造成中断。
线程池的缺点
线程最主要的缺点就是增加了CPU的计算开销,每个command都会在单独的线程上执行,这样的执行方式会涉及到命令的排队、调度和上下文切换。Netflix在设计这个系统时,决定接受这个开销的代价,来换取它所提供的好处,并且认为这个开销是足够小的,不会有重大的成本或者是性能影响。
# 信号隔离
信号隔离是通过限制依赖服务的并发请求数,来控制隔离开关。信号隔离方式下,业务请求线程和执行依赖服务的线程是同一个线程(例如Tomcat容器线程)。
# 观察者模式
- Hystrix通过观察者模式对服务进行状态监听
- 每个任务都包含有一个对应的Metrics,所有Metrics都由一个ConcurrentHashMap来进行维护,Key是CommandKey.name()
- 在任务的不同阶段会往Metrics中写入不同的信息,Metrics会对统计到的历史信息进行统计汇总,供熔断器以及Dashboard监控时使用
# Metrics
- Metrics内部又包含了许多内部用来管理各种状态的类,所有的状态都是由这些类管理的
- 各种状态的内部也是用ConcurrentHashMap来进行维护的
Metrics在统计各种状态时,时运用滑动窗口思想进行统计的,在一个滑动窗口时间中又划分了若干个Bucket(滑动窗口时间与Bucket成整数倍关系),滑动窗口的移动是以Bucket为单位进行滑动的。
# 熔断机制
熔断机制是一种保护性机制,当系统中某个服务失败率过高时,将开启熔断器,对该服务的后续调用,直接拒绝,进行Fallback操作。熔断所依靠的数据即是Metrics中的HealthCount所统计的错误率。如何判断是否应该开启熔断器?必须同时满足两个条件:
- 请求数达到设定的阀值;
- 请求的失败数 / 总请求数 > 错误占比阀值%。
# 降级策略
当construct()或run()执行失败时,Hystrix调用fallback执行回退逻辑,回退逻辑包含了通用的响应信息,这些响应从内存缓存中或者其他固定逻辑中得到,而不应有任何的网络依赖。如果一定要在失败回退逻辑中包含网络请求,必须将这些网络请求包装在另一个 HystrixCommand 或 HystrixObservableCommand 中,即多次降级。
失败降级也有频率限时,如果同一fallback短时间请求过大,则会抛出拒绝异常。
# 缓存机制
同一对象的不同HystrixCommand实例,只执行一次底层的run()方法,并将第一个响应结果缓存起来,其后的请求都会从缓存返回相同的数据。
由于请求缓存位于construct()或run()方法调用之前,所以,它减少了线程的执行,消除了线程、上下文等开销。
# spring核心接口及作用
# BeanFactoryPostProcessor
postProcessBeanFactory:对工厂进行增强
# BeanDefinitionRegistryPostProcessor
BeanDefinitionRegistry增强:主要对BeanDifinition做增删改查操作
# BeanPostProcessor
postProcessBeforeInitialization:初始化之前执行
postProcessAfterInitialization:初始化之后执行
# InstantiationAwareBeanPostProcessor
postProcessBeforeInstantiation:实例化之前执行
postProcessAfterInstantiation:实例化之后执行
postProcessProperties:属性赋值时处理资源属性
# SmartInstantiationAwareBeanPostProcessor
getEarlyBeanReference:获取早期的Bean引用,用于解决循环依赖和代理对象
# DestructionAwareBeanPostProcessor
postProcessBeforeDestruction:对象销毁之前执行
requiresDestruction:是否小销毁,默认为true
# MergedBeanDefinitionPostProcessor
postProcessMergedBeanDefinition:处理BeanDefinition的合并问题(当有继承父类时)
resetBeanDefinition:重置Bean定义
# InitializingBean
在BeanPostProcessor的postProcessBeforeInitialization方法执行之后,自定义初始化方法执行之前执行的
# DisposableBean
对象销毁之前之前执行
# spring实例化过程

# spring生命周期
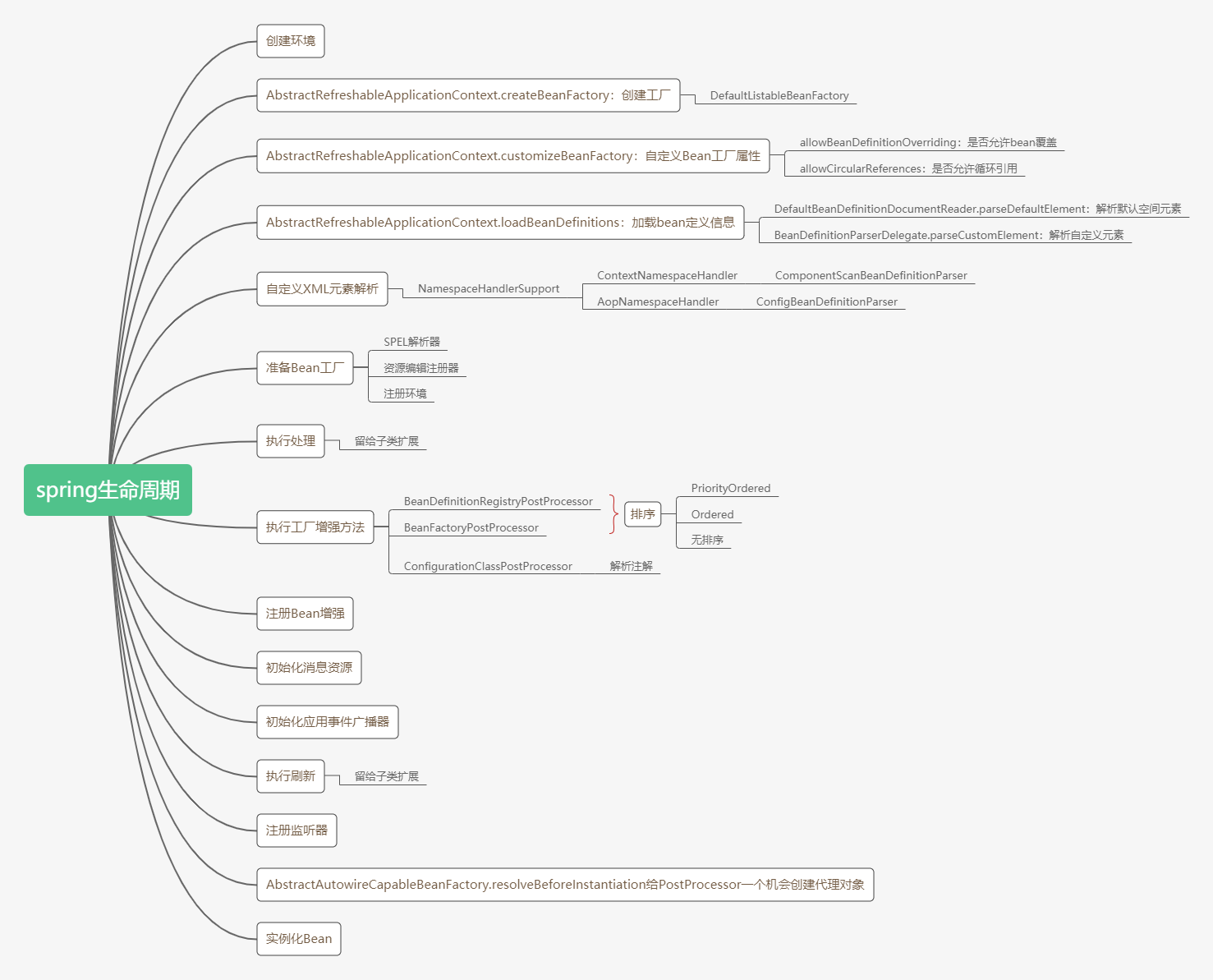
# ES
# es查询查过1024个元素报错
报错如下:
Caused by: org.elasticsearch.common.io.stream.NotSerializableExceptionWrapper: too_many_clauses: maxClauseCount is set to 1024
原因:
es的in查询,in中id大于1024个,导致es报错,es默认支持元素数量为1024个
解决办法:编辑elasticsearch.yml,添加如下配置:
# 旧版本
index.query.bool.max_clause_count: 10240
# 新版本
indices.query.bool.max_clause_count: 300000
注意yml 语法,:冒号后面有空格。