# CentOS7安装Hadoop
# 设置免密登录
ssh localhost
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# 秘钥拷贝
# bigdata01
scp ~/.ssh/id_dsa.pub bigdata02:~/.ssh/bigdata01.pub
scp ~/.ssh/id_dsa.pub bigdata03:~/.ssh/bigdata01.pub
scp ~/.ssh/id_dsa.pub bigdata04:~/.ssh/bigdata01.pub
# bigdata02
scp ~/.ssh/id_dsa.pub bigdata01:~/.ssh/bigdata02.pub
scp ~/.ssh/id_dsa.pub bigdata03:~/.ssh/bigdata02.pub
scp ~/.ssh/id_dsa.pub bigdata04:~/.ssh/bigdata02.pub
# bigdata03
scp ~/.ssh/id_dsa.pub bigdata01:~/.ssh/bigdata03.pub
scp ~/.ssh/id_dsa.pub bigdata02:~/.ssh/bigdata03.pub
scp ~/.ssh/id_dsa.pub bigdata04:~/.ssh/bigdata03.pub
# bigdata04
scp ~/.ssh/id_dsa.pub bigdata01:~/.ssh/bigdata04.pub
scp ~/.ssh/id_dsa.pub bigdata02:~/.ssh/bigdata04.pub
scp ~/.ssh/id_dsa.pub bigdata03:~/.ssh/bigdata04.pub
# 增加认证
# bigdata01
cat ~/.ssh/bigdata02.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/bigdata03.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/bigdata04.pub >> ~/.ssh/authorized_keys
# bigdata02
cat ~/.ssh/bigdata01.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/bigdata03.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/bigdata04.pub >> ~/.ssh/authorized_keys
# bigdata03
cat ~/.ssh/bigdata01.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/bigdata02.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/bigdata04.pub >> ~/.ssh/authorized_keys
# bigdata04
cat ~/.ssh/bigdata01.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/bigdata02.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/bigdata03.pub >> ~/.ssh/authorized_keys
# 安装jdk
# bigdata01上传jdk安装包
scp ~/jdk-8u231-linux-x64.rpm bigdata02:`pwd`
scp ~/jdk-8u231-linux-x64.rpm bigdata03:`pwd`
scp ~/jdk-8u231-linux-x64.rpm bigdata04:`pwd`
# 执行安装bigdata01-bigdata04
rpm -i jdk-8u231-linux-x64.rpm
# 设置环境变量
vim/etc/profile
export JAVA_HOME=/usr/java/default
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
# 单机部署
# 单机部署存在的角色
NameNode
管理节点
SecondaryNameNode
帮助namenode备份数据 但是接替不了namenode的工作
DataNode
数据节点
# 部署策略
| NameNode | SecondaryNameNode | DataNode | |
|---|---|---|---|
| bigdata01 | 是 | 是 | 是 |
| bigdata02 | |||
| bigdata03 | |||
| bigdata04 |
# 环境安装
# bigdata01上传安装包
cd
scp ~/hadoop-2.8.3.tar.gz bigdata02:`pwd`
scp ~/hadoop-2.8.3.tar.gz bigdata03:`pwd`
scp ~/hadoop-2.8.3.tar.gz bigdata04:`pwd`
# 解压到指定目录
mkdir -p /opt/bigdata/hadoop-2.8.3-local
tar -zxvf /root/hadoop-2.8.3.tar.gz -C /opt/bigdata/hadoop-2.8.3-local
cd /opt/bigdata/hadoop-2.8.3-local
# 设置环境变量
vim/etc/profileexport JAVA_HOME=/usr/java/default export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export HADOOP_HOME=/opt/bigdata/hadoop-2.8.3-local/hadoop-2.8.3 export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile
# 执行配置
vimhadoop-env.sh
export JAVA_HOME=/usr/java/default
vimcore-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://bigdata01:9000</value> </property>
vimhdfs-site.xml
<!-- 副本数量为1 --> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- NameNode的路径--> <property> <name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/local/dfs/name</value> </property> <!-- DataNode的路径--> <property> <name>dfs.datanode.data.dir</name> <value>/var/bigdata/hadoop/local/dfs/data</value> </property> <!-- SecondaryNameNode在哪个端口启动--> <property> <name>dfs.namenode.secondary.http-address</name> <value>bigdata01:50090</value> </property> <!-- SecondaryNameNode的路径--> <property> <name>dfs.namenode.checkpoint.dir</name> <value>/var/bigdata/hadoop/local/dfs/secondary</value> </property>
vimslaves
bigdata01
# 初始化
hdfs namenode -format
# 启动
start-dfs.sh
# 停止
stop-dfs.sh
# 访问地址
http://bigdata01:50070/
# 遇到的问题
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决方案:
wget http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.7.0.tar tar -xvf hadoop-native-64-2.7.0.tar -C /opt/bigdata/hadoop-2.8.3-ha/hadoop-2.8.3/lib/native tar -xvf hadoop-native-64-2.7.0.tar -C /opt/bigdata/hadoop-2.8.3-ha/hadoop-2.8.3/lib # 环境变量 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
# 简单命令使用
# 创建目录
hdfs dfs -mkdir /bigdata
# 查看根目录
hdfs dfs -ls /
# 完全分布式部署
# 部署策略
| NameNode | SecondaryNameNode | DataNode | |
|---|---|---|---|
| bigdata01 | 是 | ||
| bigdata02 | 是 | 是 | |
| bigdata03 | 是 | ||
| bigdata04 | 是 |
# 环境安装
# 解压到指定目录
mkdir -p /opt/bigdata/hadoop-2.8.3-full
tar -zxvf /root/hadoop-2.8.3.tar.gz -C /opt/bigdata/hadoop-2.8.3-full
cd /opt/bigdata/hadoop-2.8.3-full
# 设置环境变量
vim/etc/profileexport JAVA_HOME=/usr/java/default export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export HADOOP_HOME=/opt/bigdata/hadoop-2.8.3-full/hadoop-2.8.3 export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile
# 执行配置
cd $HADOOP_HOME/etc/hadoop
vimhadoop-env.sh
export JAVA_HOME=/usr/java/defaultvimcore-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://bigdata01:9000</value> </property>vimhdfs-site.xml
<!-- 副本数量为2 --> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- NameNode的路径--> <property> <name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/full/dfs/name</value> </property> <!-- DataNode的路径--> <property> <name>dfs.datanode.data.dir</name> <value>/var/bigdata/hadoop/full/dfs/data</value> </property> <!-- SecondaryNameNode在哪个端口启动--> <property> <name>dfs.namenode.secondary.http-address</name> <value>bigdata02:50090</value> </property> <!-- SecondaryNameNode的路径--> <property> <name>dfs.namenode.checkpoint.dir</name> <value>/var/bigdata/hadoop/full/dfs/secondary</value> </property>vimslaves
bigdata02 bigdata03 bigdata04
# 配置分发
cd $HADOOP_HOME/etc/hadoop
scp -r hadoop-env.sh core-site.xml hdfs-site.xml slaves bigdata02:`pwd`
scp -r hadoop-env.sh core-site.xml hdfs-site.xml slaves bigdata03:`pwd`
scp -r hadoop-env.sh core-site.xml hdfs-site.xml slaves bigdata04:`pwd`
# 初始化
hdfs namenode -format
# 启动
start-dfs.sh
# 停止
stop-dfs.sh
# 访问地址
http://bigdata01:50070/
# 简单命令使用
# 创建目录
hdfs dfs -mkdir /bigdata
# 查看根目录
hdfs dfs -ls /
# 高可用 HA 配置
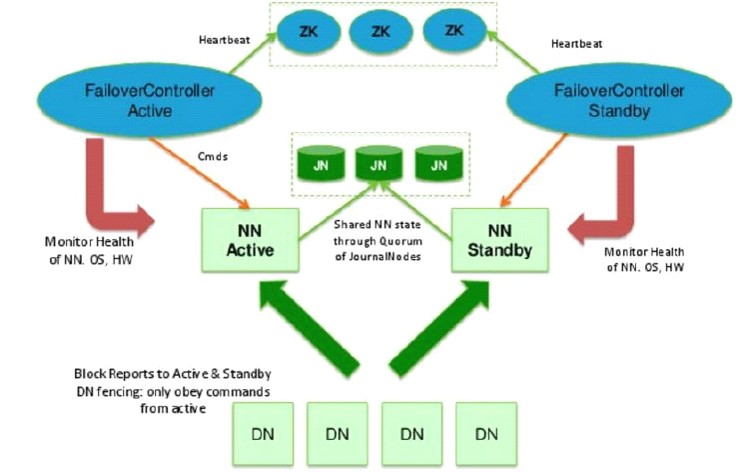
# 部署策略
| NameNode | ZKFC | JournalNode | Zookeeper | DataNode | |
|---|---|---|---|---|---|
| bigdata01 | 是 | 是 | 是 | 是 | |
| bigdata02 | 是 | 是 | 是 | 是 | 是 |
| bigdata03 | 是 | 是 | 是 | ||
| bigdata04 | 是 | 是 |
# 环境安装
# 安装包分发
cd
scp -r ~/hadoop-2.8.3.tar.gz bigdata02:`pwd`
scp -r ~/hadoop-2.8.3.tar.gz bigdata03:`pwd`
scp -r ~/hadoop-2.8.3.tar.gz bigdata04:`pwd`
scp -r ~/zookeeper-3.4.9.tar.gz bigdata02:`pwd`
scp -r ~/zookeeper-3.4.9.tar.gz bigdata03:`pwd`
scp -r ~/zookeeper-3.4.9.tar.gz bigdata04:`pwd`
# hadoop解压到指定目录
mkdir -p /opt/bigdata/hadoop-2.8.3-ha
tar -zxvf /root/hadoop-2.8.3.tar.gz -C /opt/bigdata/hadoop-2.8.3-ha
cd /opt/bigdata/hadoop-2.8.3-ha
# Zookeeper解压到指定目录
tar -zxvf /root/zookeeper-3.4.9.tar.gz -C /opt/bigdata
# 设置环境变量
vim/etc/profileexport JAVA_HOME=/usr/java/default export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export HADOOP_HOME=/opt/bigdata/hadoop-2.8.3-ha/hadoop-2.8.3 export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.9 export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/binsource /etc/profile
# 设置完环境变量之后需要重启
reboot
# Zookeeper配置
# 执行配置
cd /opt/bigdata/zookeeper-3.4.9/conf
cp zoo_sample.cfg zoo.cfg
vimzoo.cfg
dataDir=/var/bigdata/hadoop/zk server.1=bigdata01:2888:3888 server.2=bigdata02:2888:3888 server.3=bigdata03:2888:3888 server.4=bigdata04:2888:3888
# 分发配置后的zookeeper
scp -r zoo.cfg bigdata02:`pwd`
scp -r zoo.cfg bigdata03:`pwd`
scp -r zoo.cfg bigdata04:`pwd`
# 配置myid
# bigdata01
mkdir /var/bigdata/hadoop/zk
echo 1 > /var/bigdata/hadoop/zk/myid
cat /var/bigdata/hadoop/zk/myid
# bigdata02
mkdir /var/bigdata/hadoop/zk
echo 2 > /var/bigdata/hadoop/zk/myid
cat /var/bigdata/hadoop/zk/myid
# bigdata03
mkdir /var/bigdata/hadoop/zk
echo 3 > /var/bigdata/hadoop/zk/myid
cat /var/bigdata/hadoop/zk/myid
# bigdata04
mkdir /var/bigdata/hadoop/zk
echo 4 > /var/bigdata/hadoop/zk/myid
cat /var/bigdata/hadoop/zk/myid
# 启动Zookeeper
bigdata01-bigdata04
zkServer.sh start zkServer.sh status zkServer.sh stop
# 执行配置
cd $HADOOP_HOME/etc/hadoop
vimhadoop-env.sh
export JAVA_HOME=/usr/java/defaultvimcore-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>bigdata02:2181,bigdata03:2181,bigdata04:2181</value> </property>vimhdfs-site.xml
<!-- 副本数量为3 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- NameNode的路径--> <property> <name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/ha/dfs/name</value> </property> <!-- DataNode的路径--> <property> <name>dfs.datanode.data.dir</name> <value>/var/bigdata/hadoop/ha/dfs/data</value> </property> <!-- 以下是 一对多,逻辑到物理节点的映射--> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>bigdata01:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>bigdata02:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>bigdata01:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>bigdata02:50070</value> </property> <!-- 以下是JN在哪里启动,数据存那个磁盘--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://bigdata01:8485;bigdata02:8485;bigdata03:8485/mycluster</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/var/bigdata/hadoop/ha/dfs/jn</value> </property> <!-- HA角色切换的代理类和实现方法,我们用的ssh免密--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider </value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa</value> </property> <!-- 开启自动化: 启动zkfc--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>vimslaves
bigdata02 bigdata03 bigdata04
# 配置分发
cd $HADOOP_HOME/etc/hadoop
scp -r hadoop-env.sh core-site.xml hdfs-site.xml slaves bigdata02:`pwd`
scp -r hadoop-env.sh core-site.xml hdfs-site.xml slaves bigdata03:`pwd`
scp -r hadoop-env.sh core-site.xml hdfs-site.xml slaves bigdata04:`pwd`
# 第一次启动顺序
# 开启1,2,3台的journalnode
hadoop-daemon.sh start journalnode
# 选择一个NN 做格式化
hdfs namenode -format
hadoop-daemon.sh start namenode
# 在另一台NN进行同步
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
# 在bigdata01下格式化zk
hdfs zkfc -formatZK
# 启动
start-dfs.sh
# 停止
stop-dfs.sh
# 再次启动时的启动顺序
# bigdata01-04启动Zookeeper
zkServer.sh start
# 启动hadoop
start-dfs.sh
# 停止HA
# 停止hadoop
stop-dfs.sh
# 停止Zookeeper
zkServer.sh stop
# 访问地址
http://bigdata01:50070
http://bigdata02:50070
# Yarn安装
# 部署策略
| NameNode | ZKFC | JournalNode | Zookeeper | DataNode | ResourceManager | NodeManager | |
|---|---|---|---|---|---|---|---|
| bigdata01 | 是 | 是 | 是 | 是 | |||
| bigdata02 | 是 | 是 | 是 | 是 | 是 | 是 | |
| bigdata03 | 是 | 是 | 是 | 是 | 是 | ||
| bigdata04 | 是 | 是 | 是 | 是 |
# 修改配置
cd $HADOOP_HOME/etc/hadoop
cp mapred-site.xml.template mapred-site.xmlvimmapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>vimyarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>bigdata01:2181,bigdata02:2181,bigdata03:2181,bigdata04:2181</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>tiankafei</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>bigdata03</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>bigdata04</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>bigdata03:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>bigdata04:8088</value> </property>
# 配置分发
scp -r mapred-site.xml yarn-site.xml bigdata02:`pwd`
scp -r mapred-site.xml yarn-site.xml bigdata03:`pwd`
scp -r mapred-site.xml yarn-site.xml bigdata04:`pwd`
# 启动resourcemanager
yarn-daemons.sh start resourcemanager
# 启动yarn
start-yarn.sh
# 访问地址
http://bigdata03:8088/cluster
http://bigdata04:8088/cluster
# 高可用集群停止服务
yarn-daemons.sh stop resourcemanager
stop-yarn.sh
stop-dfs.sh
zkServer.sh stop
# 高可用集群再次启动
zkServer.sh start
yarn-daemons.sh start resourcemanager
start-dfs.sh
start-yarn.sh
# Hive安装配置
# 单机部署
| mysql | hive服务端 | hive客户端 | |
|---|---|---|---|
| bigdata01 | 是 | 是 | |
| bigdata02 | |||
| bigdata03 | |||
| bigdata04 |
# 安装包分发
cd
scp -r ~/apache-hive-2.3.6-bin.tar.gz bigdata02:`pwd`
scp -r ~/apache-hive-2.3.6-bin.tar.gz bigdata03:`pwd`
scp -r ~/apache-hive-2.3.6-bin.tar.gz bigdata04:`pwd`
# 解压到指定目录
tar -zxvf /root/apache-hive-2.3.6-bin.tar.gz -C /opt/bigdata
cd /opt/bigdata
mv apache-hive-2.3.6-bin/ apache-hive-2.3.6
# 设置环境变量
vim/etc/profileexport JAVA_HOME=/usr/java/default export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export HADOOP_HOME=/opt/bigdata/hadoop-2.8.3-ha/hadoop-2.8.3 export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.9 export HIVE_HOME=/opt/bigdata/apache-hive-2.3.6 export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/binsource /etc/profile
# 执行配置
cd $HIVE_HOME/conf
cp hive-default.xml.template hive-site.xmlvimhive-site.xml
#删除 :.,$-1d<property> <name>hive.metastore.warehouse.dir</name> <value>/var/bigdata/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://software:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>tiankafei</value> </property>
# 分发配置
scp -r hive-site.xml bigdata02:`pwd`
scp -r hive-site.xml bigdata03:`pwd`
scp -r hive-site.xml bigdata04:`pwd`
# 上传mysql依赖的jar包
cd /opt/bigdata/apache-hive-2.3.6/lib
scp -r mysql-connector-java-8.0.18.jar bigdata02:`pwd`
scp -r mysql-connector-java-8.0.18.jar bigdata03:`pwd`
scp -r mysql-connector-java-8.0.18.jar bigdata04:`pwd`
# 在bigdata01上初始化数据库
schematool -dbType mysql -initSchema
# 启动hive
hive
# 服务元数据分离配置
| mysql | hive服务端 | hive客户端 | |
|---|---|---|---|
| bigdata01 | |||
| bigdata02 | |||
| bigdata03 | 是 | ||
| bigdata04 | 是 |
# bigdata02配置
cd $HIVE_HOME/conf
vimhive-site.xml
<property> <name>hive.metastore.warehouse.dir</name> <value>/var/bigdata/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://software:3306/hive_remote?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>tiankafei</value> </property>
bigdata03-04配置
vimhive-site.xml
<property> <name>hive.metastore.warehouse.dir</name> <value>/var/bigdata/hive/warehouse</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://bigdata02:9083</value> </property>
# 在bigdata02上初始化数据库
schematool -dbType mysql -initSchema
# 在bigdata02上阻塞式启动hive服务端
hive --service metastore
# 在bigdata03-04上启动Hive客户端
hive
# 解决root用户不能登录的问题,其他用户登录需要配置各种权限
cd $HADOOP_HOME/etc/hadoop
vimcore-site.xml
<property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property>配置完成之后重新启动集群,或者在namenode的节点上执行如下命令
hdfs dfsadmin -fs hdfs://bigdata01:8020 -refreshSuperUserGroupsConfiguration hdfs dfsadmin -fs hdfs://bigdata02:8020 -refreshSuperUserGroupsConfiguration
# 独立hiveserver2模式
将现有的所有hive的服务停止,不需要修改任何服务,在bigdata03机器上执行hiveserver2或者hive --service hiveserver2的命令,开始启动hiveserver2的服务,hiveserver2的服务也是一个阻塞式窗口,当开启服务后,会开启一个10000的端口,对外提供服务。
# bigdata02上启动服务
hiveserver2
或
hive --service hiveserver2
# bigdata03-04上执行
#1。直接在命令行执行
# beeline -u jdbc:hive2://<host>:<port>/<db> -n name
beeline -u jdbc:hive2://bigdata02:10000/default -n root tiankafei
#2。先通过beeline进入交互式窗口,然后再执行下面的命令
beeline
# !connect jdbc:hive2://<host>:<port>/<db> root 123
!connect jdbc:hive2://bigdata02:10000/default root tiankafei
# 共享metastore server的hiveserver2模式搭建
# 在bigdata02上执行hive --service metastore启动元数据服务
hive --service metastore
# 在bigdata03上执行hiveserver2或者hive --service hiveserver2两个命令其中一个都可以
hiveserver2
或
hive --service hiveserver2
# 在任意一台包含beeline脚本的虚拟机中执行beeline的命令进行连接
#1。直接在命令行执行
# beeline -u jdbc:hive2://<host>:<port>/<db> -n name
beeline -u jdbc:hive2://bigdata03:10000/default -n root tiankafei
#2。先通过beeline进入交互式窗口,然后再执行下面的命令
beeline
# !connect jdbc:hive2://<host>:<port>/<db> root 123
!connect jdbc:hive2://bigdata03:10000/default root tiankafei
大数据启蒙 →