# HBase学习笔记
英文文档:http://hbase.apache.org/book.html (opens new window)
中文文档:http://abloz.com/hbase/book.html (opens new window)
# HBase简介
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBASE是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable使用GFS作为其文件存储系统,HBASE利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBASE利用Zookeeper作为协同服务。
# 与传统数据库的对比
# 传统数据库遇到的问题
- 数据量很大的时候无法存储;
- 没有很好的备份机制;
- 数据达到一定数量开始缓慢,很大的话基本无法支撑;
# HBASE优势
- 线性扩展,随着数据量增多可以通过节点扩展进行支撑;
- 数据存储在hdfs上,备份机制健全;
- 通过zookeeper协调查找数据,访问速度快。
# HBase数据模型
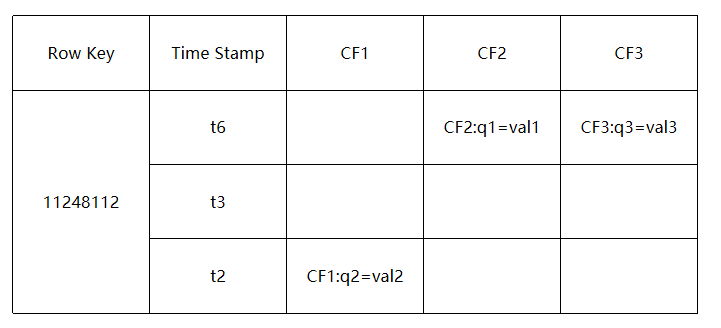
# rowkey
- 决定一行数据,每行记录的唯一标识
- 按照字典序排序
- RowKey只能存储64K的字节数据
# Column Family & Qualifier
- HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema)定义的一部分预先给出。如 create ‘test’, ‘course’;
- 列名以列族作为前缀,每个“列族”都可以有多个列成员(column);如course:math, course:english, 新的列族成员(列)可以随后按需、动态加入;
- 权限控制、存储以及调优都是在列族层面进行的;
- HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
# TimeStamp时间戳
- 在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
- 时间戳的类型是 64位整型。
- 时间戳可以由HBase(在数据写入时自动)赋值,此时间戳是精确到毫秒的当前系统时间。
- 时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
# Cell
- 由行和列的坐标交叉决定;
- 单元格是有版本的;
- 单元格的内容是未解析的字节数组;
由{row key, column( =
+ ), version} 唯一确定的单元。 cell中的数据是没有类型的,全部是字节数组形式存贮。
# HBase架构
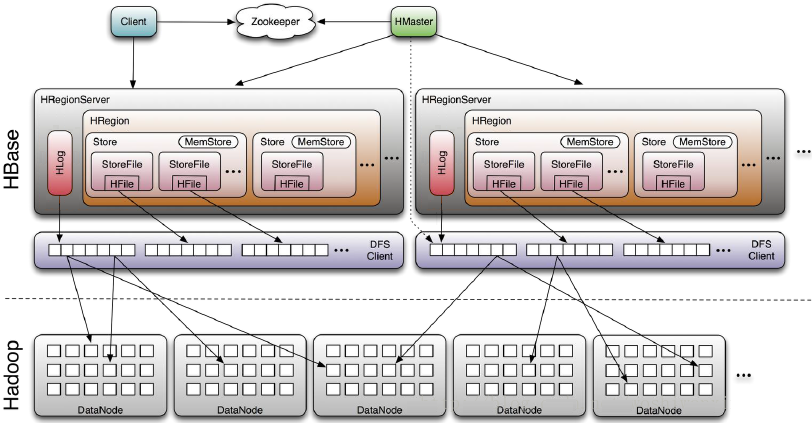
# 角色介绍
# Client
- 使用HBase RPC机制与HMaster和HRegionServer进行通信
- Client与HMaster进行管理类操作
- Client与HRegionServer进行数据读写类操作
# Zookeeper
- Zookeeper避免HMaster单点问题
- HRegionServer把自己注册到Zookeeper中,HMaster随时感知各个HRegionServer的健康状况
- 存储HBase的schema和table元数据(Zookeeper Quorum存储-ROOT-表地址、HMaster地址)
# HMaster
HMaster没有单点问题,HBase可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master在运行。主要负责Table和Region的管理工作:
- 管理用户对表的增删改查操作
- 管理HRegionServer的负载均衡,调整Region分布
- Region Split后,负责新Region的分布
- 在HRegionServer停机后,负责失效HRegionServer上Region迁移
# HRegionServer
HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写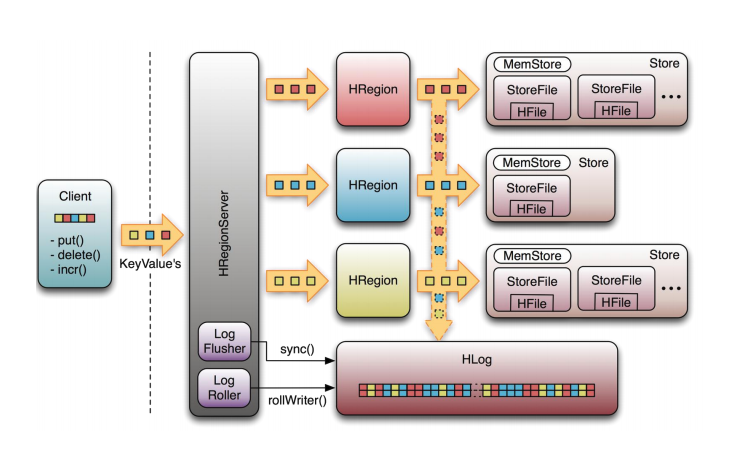
- HRegionServer管理一系列HRegion对象
- 每个HRegion对应Table中一个Region,HRegion由多个HStore组成
- 每个HStore对应Table中一个Column Family的存储
- Column Family就是一个集中的存储单元,故将具有相同IO特性的Column放在一个Column Family会更高效
# HRegion
- HBase自动把表水平划分成多个区域(region),每个region会保存一个表里某段连续的数据
- 每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阈值的时候,region就会等分会两个新的region(裂变)
- 当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver 上。
# Memstore与storefile
- 一个region由多个store组成,一个store对应一个CF(列族)
- store包括位于内存中的memstore和位于磁盘的storefile写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile
- 当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major ),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
- 当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡
- 客户端检索数据,先在memstore找,找不到去blockcache,找不到再找storefile
# 注意问题
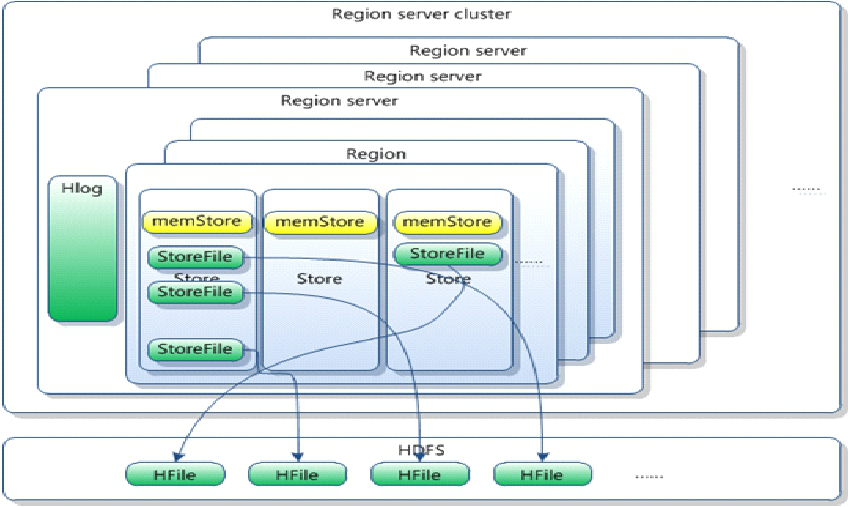
- HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。
- HRegion由一个或者多个Store组成,每个store保存一个columns family。
- 每个Strore又由一个memStore和0至多个StoreFile组成。如图:StoreFile以HFile格式保存在HDFS上。
# HBase读写流程
# 读流程
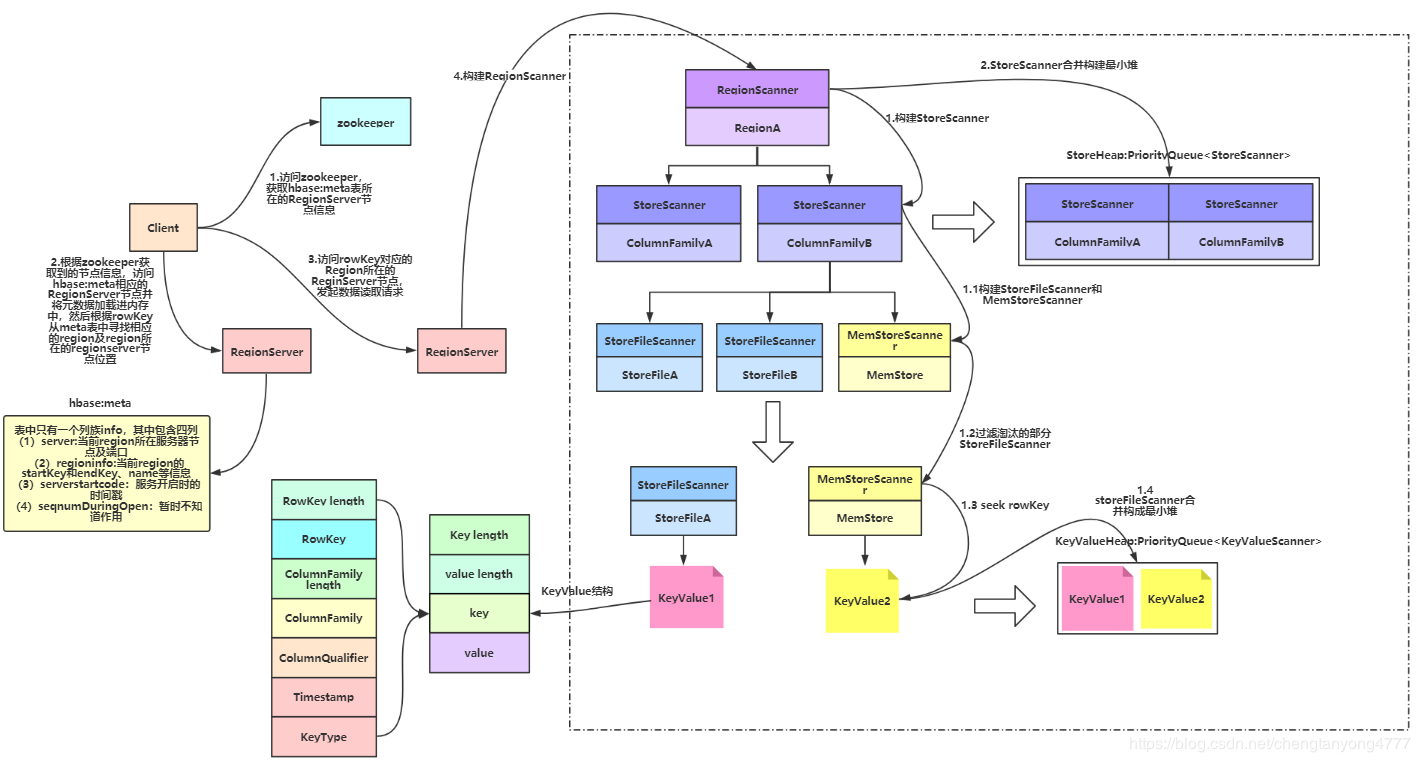
- Client访问zookeeper,获取hbase:meta所在RegionServer的节点信息
- Client访问hbase:meta所在的RegionServer,获取hbase:meta记录的元数据后先加载到内存中,然后再从内存中根据需要查询的RowKey查询出RowKey所在的Region的相关信息(Region所在RegionServer)
- Client访问RowKey所在Region对应的RegionServer,发起数据读取请求
- RegionServer构建RegionScanner(需要查询的RowKey分布在多少个Region中就需要构建多少个RegionScanner),用于对该Region的数据检索
- RegionScanner构建StoreScanner(Region中有多少个Store就需要构建多少个StoreScanner,Store的数量取决于Table的ColumnFamily的数量),用于对该列族的数据检索
- 多个StoreScanner合并构建最小堆(已排序的完全二叉树)StoreHeap:PriorityQueue
- StoreScanner构建一个MemStoreScanner和一个或多个StoreFileScanner(数量取决于StoreFile数量)
- 过滤掉某些能够确定所要查询的RowKey一定不在StoreFile内的对应的StoreFileScanner或MemStoreScanner
- 经过筛选后留下的Scanner开始做读取数据的准备,将对应的StoreFile定位到满足的RowKey的起始位置
- 将所有的StoreFileScanner和MemStoreScanner合并构建最小堆KeyValueHeap:PriorityQueue
,排序的规则按照KeyValue从小到大排序 - 从KeyValueHeap:PriorityQueue
中经过一系列筛选后一行行的得到需要查询的KeyValue。
# 步骤答疑解释
# 1. 为什么Scanner需要有小到大排序?
最直接的解释是scan的结果需要由小到大输出给用户,当然,这并不全面,最合理的解释是只有由小到大排序才能使得scan效率最高。举个简单的例子,HBase支持数据多版本,假设用户只想获取最新版本,那只需要将这些数据由最新到最旧进行排序,然后取队首元素返回就可以。那么,如果不排序,就只能遍历所有元素,查看符不符合用户查询条件。
# 2. HBase中KeyValue是什么样的结构?
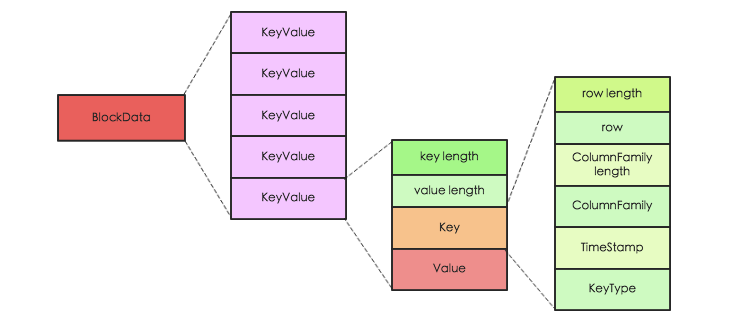
- KeyValue由Key length、value length、key、value组成
- 其中key又由RowKey length、RowKey、ColumnFamily length、ColumnFamily、ColumnQualifier、TimeStamp、KeyType组成
- RowKey length:RowKey长度
- RowKey:RowKey内容
- ColumnFamily length:列族长度
- ColumnFamily:列族
- ColumnQualifier:列名
- Timestamp:时间戳
- KeyType:表示类型,取值有Put/Delete/Delete Column/Delete Family
# 3. 不同KeyValue之间如何进行大小比较?
key的内容包括RowKey、ColumnFamuly、ColumnQualifier、Timestamp、KeyType。所以keyValue的大小比较规则如下:
- 比较RowKey,RowKey越小则KeyValue越小
- RowKey相同情况下,比较ColumnFamily,ColumnFamily越小,KeyValue越小
- ColumnFamily相同情况下,比较ColumnQualifier,ColumnQualifier越小,KeyValue越小
- ColumnQualifier相同情况下,比较Timestamp越大,KeyValue越小
- Timestamp相同情况下,比较KeyType(DeleteFamily -> DeleteColumn -> Delete -> Put),KeyType级别从左到右对应的KeyValue从小到大
# 4. 数据是如何从最小堆中一行行获取的?
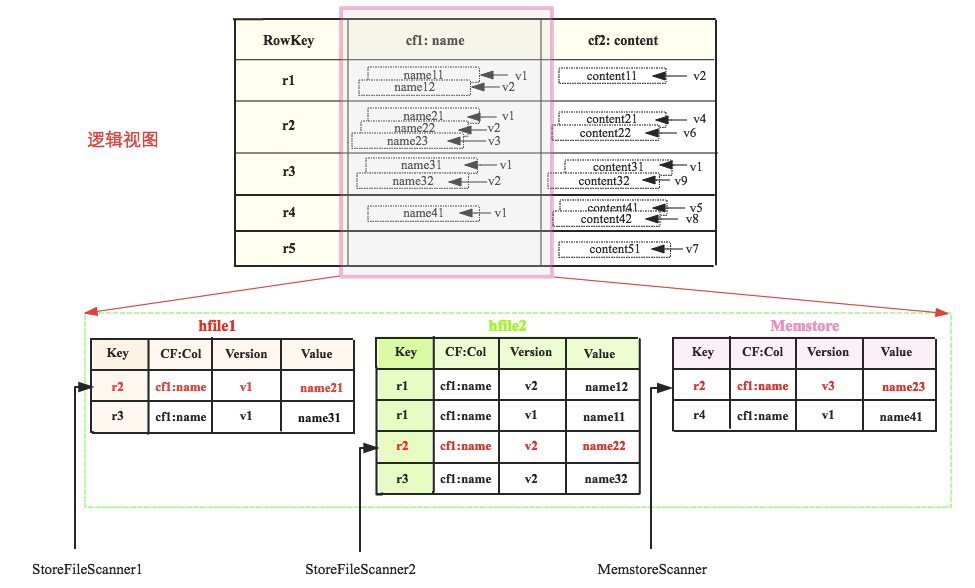
这三个Scanner组成的heap为<MemstoreScanner,StoreFileScanner2, StoreFileScanner1>,Scanner由小到大排列。查询的时候首先pop出heap的堆顶元素,即MemstoreScanner,得到keyvalue = r2:cf1:name:v3:name23的数据,拿到这个keyvalue之后,需要进行如下判定:
- 检查该KeyValue的KeyType是否是Deleted/DeletedCol等,如果是就直接忽略该列所有其他版本,跳到下列(列族)
- 检查该KeyValue的Timestamp是否在用户设定的Timestamp Range范围,如果不在该范围,忽略
- 检查该KeyValue是否满足用户设置的各种filter过滤器,如果不满足,忽略
- 检查该KeyValue是否满足用户查询中设定的版本数,比如用户只查询最新版本,则忽略该cell的其他版本;反正如果用户查询所有版本,则还需要查询该cell的其他版本
现在假设用户查询所有版本而且该keyvalue检查通过,此时当前的堆顶元素需要执行next方法去检索下一个值,并重新组织最小堆。即图中MemstoreScanner将会指向r4,重新组织最小堆之后最小堆将会变为<StoreFileScanner2, StoreFileScanner1, MemstoreScanner>,堆顶元素变为StoreFileScanner2,得到keyvalue=r2:cf1:name:v2:name22,进行一系列判定,再next,再重新组织最小堆…
不断重复这个过程,直至一行数据全部被检索得到。继续下一行…
# 写流程
- Client访问zookeeper,获取hbase:meta所在RegionServer的节点信息
- Client访问hbase:meta所在的RegionServer,获取hbase:meta记录的元数据后先加载到内存中,获取将要写入region所在的regionserver的位置信息(Region所在RegionServer)
- 客户端访问具体的region所在的regionserver,找到对应的region及store,发起数据写入请求,在Region中写数据
- 开始写数据,写数据的时候会先向hlog中写一份数据(预写日志,Write Ahead Log,WAL)。目的:方便memstore中数据丢失后能够根据hlog恢复数据。向hlog中写数据的时候也是优先写入内存,后台会有一个线程定期(每隔1秒)异步刷写数据到hdfs,如果hlog的数据也写入失败,那么数据就会发生丢失
- Hlog写数据完成之后,会先将数据写入到MemStore,MemStore默认大小是64M,当MemStore满了之后,数据被Flush成一个StoreFile(将MemStore中的数据持久化到hdfs中)
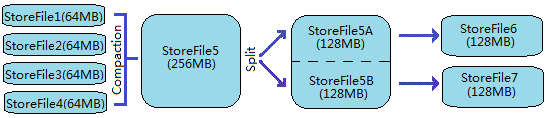
- 随着StoreFile文件的不断增多,当其数量增长到一定阀值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除
- StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile
- 单个StoreFile大小超过一定阀值后,触发Split操作,把当前Region Split成2个新的Region。父Region会下线,新Split出的2个子Region会被HMaster分配到相应的RegionServer上,使得原先1个Region的压力得以分流到2个Region上
可以看出HBase只有增添数据,所有的更新和删除操作都是在后续的Compact历程中举行的,使得用户的写操作只要进入内存就可以立刻返回,实现了HBase I/O的高性能。
# HBase基本操作
# 通用命令
//展示regionserver的task列表
processlist
//展示集群的状态
status
//table命令的帮助手册
table_help
//显示hbase的版本
version
//展示当前hbase的用户
whoami
# namespace操作(相当于数据库的概念)
//创建命名空间
create_namespace 'my_ns'
//修改命名空间的属性
alter_namespace 'my_ns', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}
//删除命名空间
drop_namespace 'my_ns'
//获取命名空间的描述信息
describe_namespace 'hbase'
//展示所有的命名空间
list_namespace
//展示某个命名空间下的所有表
list_namespace_tables 'hbase'
//扫描表的全部数据
scan 'hbase:meta'
# DDL操作
//修改表的属性
alter 't1', NAME => 'f1', VERSIONS => 5
//创建表
create 'test', 'cf'
//查看表描述,只会展示列族的详细信息
describe 'test'
//禁用表
disable 'test'
//禁用所有表
disable_all
//删除表
drop 'test'
//删除所有表
drop_all
//启用表
enable 'test'
//启用所有表
enable_all
//判断表是否存在
exists 'test'
//获取表
get_table 'test'
//判断表是否被禁用
is_disabled 'test'
//判断表是否被启用
is_enabled 'test'
//展示所有表
list
//展示表占用的region
list_regions 'test'
//定位某个rowkey所在的行在哪一个region
locate_region 'test'
//展示所有的过滤器
show_filters
# dml操作
//向表中的某一个列插入值
put 'test', 'key1', 'cf:name', 'zhangsan'
put 'test', 'key1', 'cf:age', '13'
put 'test', 'key2', 'cf:name', 'lisi'
put 'test', 'key2', 'cf:age', '12'
put 'test', 'key2', 'cf:sex', 'man'
put 'test', 'key3', 'cf:name', 'wagnwu'
put 'test', 'key3', 'cf:age', '10'
//扫描表的全部数据
scan 'test'
//统计表的记录条数,默认一千条输出一次
count 'test'
//获取表的一行记录
get 'test', 'key1'
//删除表的某一个值
delete 'test', 'key2', 'cf:sex'
//向表中追加一个具体的值
append 'test', 'key1', 'cf:name', '111'
//删除指定行的所有元素值
deleteall 'test', 'key3'
//清空表的所有数据
truncate 'test'
//获取表的切片
get_splits 'test'
// 手动落磁盘命令
flush 'test'
// 查看hbase文件内容命令
hbase hfile -p -f /hbase/data/default/test/cdf8d76af8eaef52133fb6c95d28fe60/cf/ba154563be134c52a75586f204b3dc68
# HBase与Hive整合
# 单节点hbase与hive整合
$HIVE_HOME/bin/hive \
--auxpath \
$HIVE_HOME/lib/hive-hbase-handler-2.3.6.jar,\
$HIVE_HOME/lib/hbase-server-1.1.1.jar,\
$HIVE_HOME/lib/zookeeper-3.4.6.jar,\
$HIVE_HOME/lib/guava-14.0.1.jar \
--hiveconf hbase.master=bigdata01:60000
# 集群HBase与Hive整合
$HIVE_HOME/bin/hive \
--auxpath \
$HIVE_HOME/lib/hive-hbase-handler-2.3.6.jar,\
$HIVE_HOME/lib/hbase-server-1.1.1.jar,\
$HIVE_HOME/lib/zookeeper-3.4.6.jar,\
$HIVE_HOME/lib/guava-14.0.1.jar \
--hiveconf hbase.zookeeper.quorum=bigdata01,bigdata02,bigdata03,bigdata04
# 修改集群配置文件
cd $HIVE_HOME/conf
vim hive-site.xml
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata01,bigdata02,bigdata03,bigdata04</value>
</property>
# hive创建与HBase的关联表(内部表)
CREATE TABLE hbase_table_1(key int, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
TBLPROPERTIES ("hbase.table.name" = "xyz", "hbase.mapred.output.outputtable" = "xyz");
# hive创建与HBase的关联表(外部表)
-- 外部表需要先在HBase创建对应的表
create 'some_existing_table', 'cf1'
-- 创建外部表时关联HBase中已经存在的表
CREATE EXTERNAL TABLE hbase_table_2(key int, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = "cf1:val")
TBLPROPERTIES("hbase.table.name" = "some_existing_table", "hbase.mapred.output.outputtable" = "some_existing_table");
# HBase Java API
# 初始化系统环境
Configuration conf = null;
Connection conn = null;
//表的管理对象
Admin admin = null;
Table table = null;
//创建表的对象
TableName tableName = TableName.valueOf("phone");
@Before
public void init() throws IOException {
//创建配置文件对象
conf = HBaseConfiguration.create();
//加载zookeeper的配置
conf.set("hbase.zookeeper.quorum","bigdata01,bigdata02,bigdata03,bigdata04");
//获取连接
conn = ConnectionFactory.createConnection(conf);
//获取对象
admin = conn.getAdmin();
//获取数据操作对象
table = conn.getTable(tableName);
}
# 创建表
@Test
public void createTable() throws IOException {
//定义表描述对象
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(tableName);
//定义列族描述对象
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder("cf".getBytes());
//添加列族信息给表
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptorBuilder.build());
if(admin.tableExists(tableName)){
//禁用表
admin.disableTable(tableName);
admin.deleteTable(tableName);
}
//创建表
admin.createTable(tableDescriptorBuilder.build());
}
# 插入数据
@Test
public void insert() throws IOException {
Put put = new Put(Bytes.toBytes("2222"));
put.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("name"),Bytes.toBytes("lisi"));
put.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("age"),Bytes.toBytes("341"));
put.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("sex"),Bytes.toBytes("women"));
table.put(put);
}
# 通过get获取数据
@Test
public void get() throws IOException {
Get get = new Get(Bytes.toBytes("2222"));
//在服务端做数据过滤,挑选出符合需求的列
get.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("name"));
get.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("age"));
get.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("sex"));
Result result = table.get(get);
Cell cell1 = result.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("name"));
Cell cell2 = result.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("age"));
Cell cell3 = result.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("sex"));
String name = Bytes.toString(CellUtil.cloneValue(cell1));
String age = Bytes.toString(CellUtil.cloneValue(cell2));
String sex = Bytes.toString(CellUtil.cloneValue(cell3));
System.out.println(name);
System.out.println(age);
System.out.println(sex);
}
# 获取表中所有的记录
@Test
public void scan() throws IOException {
Scan scan = new Scan();
// scan.withStartRow();
// scan.withStopRow();
ResultScanner rss = table.getScanner(scan);
for (Result rs: rss) {
Cell cell1 = rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("name"));
Cell cell2 = rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("age"));
Cell cell3 = rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("sex"));
String name = Bytes.toString(CellUtil.cloneValue(cell1));
String age = Bytes.toString(CellUtil.cloneValue(cell2));
String sex = Bytes.toString(CellUtil.cloneValue(cell3));
System.out.println(name);
System.out.println(age);
System.out.println(sex);
}
}
# 假设有10个用户,每个用户一年产生10000条记录
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss");
private String getDate(String s) {
return s+String.format("%02d%02d%02d%02d%02d",random.nextInt(12)+1,random.nextInt(31),random.nextInt(24),random.nextInt(60),random.nextInt(60));
}
Random random = new Random();
public String getNumber(String str){
return str+String.format("%08d",random.nextInt(99999999));
}
@Test
public void insertMangData() throws Exception {
for(int i = 0;i<10;i++){
List<Put> puts = new ArrayList<>();
String phoneNumber = getNumber("158");
for(int j = 0 ;j<10000;j++){
String dnum = getNumber("177");
String length = String.valueOf(random.nextInt(100));
String date = getDate("2019");
String type = String.valueOf(random.nextInt(2));
//rowkey
String rowkey = phoneNumber+"_"+(Long.MAX_VALUE-sdf.parse(date).getTime());
Put put = new Put(Bytes.toBytes(rowkey));
put.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("dnum"),Bytes.toBytes(dnum));
put.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("length"),Bytes.toBytes(length));
put.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("date"),Bytes.toBytes(date));
put.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("type"),Bytes.toBytes(type));
puts.add(put);
}
table.put(puts);
}
}
# 查询某一个用户3月份的通话记录
@Test
public void scanByCondition() throws Exception {
Scan scan = new Scan();
String startRow = "15895704016_"+(Long.MAX_VALUE-sdf.parse("20190331000000").getTime());
String stopRow = "15895704016_"+(Long.MAX_VALUE-sdf.parse("20190301000000").getTime());
scan.withStartRow(Bytes.toBytes(startRow));
scan.withStopRow(Bytes.toBytes(stopRow));
ResultScanner rss = table.getScanner(scan);
for (Result rs:rss) {
System.out.print(Bytes.toString(CellUtil.cloneValue(rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("dnum")))));
System.out.print("--"+Bytes.toString(CellUtil.cloneValue(rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("type")))));
System.out.print("--"+Bytes.toString(CellUtil.cloneValue(rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("length")))));
System.out.println("--"+Bytes.toString(CellUtil.cloneValue(rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("date")))));
}
}
# 查询某个用户所有的主叫电话(type=1)
@Test
public void getType() throws IOException {
Scan scan = new Scan();
//创建过滤器集合
FilterList filters = new FilterList(FilterList.Operator.MUST_PASS_ALL);
//创建过滤器
SingleColumnValueFilter filter1 = new SingleColumnValueFilter(Bytes.toBytes("cf"),Bytes.toBytes("type"),CompareOperator.EQUAL,Bytes.toBytes("1"));
filters.addFilter(filter1);
//前缀过滤器
PrefixFilter filter2 = new PrefixFilter(Bytes.toBytes("15895704016"));
filters.addFilter(filter2);
scan.setFilter(filters);
ResultScanner rss = table.getScanner(scan);
for (Result rs:rss) {
System.out.print(Bytes.toString(CellUtil.cloneValue(rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("dnum")))));
System.out.print("--"+Bytes.toString(CellUtil.cloneValue(rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("type")))));
System.out.print("--"+Bytes.toString(CellUtil.cloneValue(rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("length")))));
System.out.println("--"+Bytes.toString(CellUtil.cloneValue(rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("date")))));
}
}
# 使用ProtoBuf插入
@Test
public void insertByProtoBuf() throws ParseException, IOException {
List<Put> puts = new ArrayList<>();
for(int i = 0;i<10;i++){
String phoneNumber = getNumber("158");
for(int j = 0 ;j<10000;j++){
String dnum = getNumber("177");
String length = String.valueOf(random.nextInt(100));
String date = getDate("2019");
String type = String.valueOf(random.nextInt(2));
//rowkey
String rowkey = phoneNumber+"_"+(Long.MAX_VALUE-sdf.parse(date).getTime());
Phone.PhoneDetail.Builder builder = Phone.PhoneDetail.newBuilder();
builder.setDate(date);
builder.setDnum(dnum);
builder.setLength(length);
builder.setType(type);
Put put = new Put(Bytes.toBytes(rowkey));
put.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("phone"),builder.build().toByteArray());
puts.add(put);
}
}
table.put(puts);
}
# 获取protoBuf存储的数据
@Test
public void getByProtoBuf() throws IOException {
Get get = new Get("15899309685_9223370490668224807".getBytes());
Result rs = table.get(get);
byte[] b = CellUtil.cloneValue(rs.getColumnLatestCell(Bytes.toBytes("cf"),Bytes.toBytes("phone")));
Phone.PhoneDetail phoneDetail = Phone.PhoneDetail.parseFrom(b);
System.out.println(phoneDetail);
}
# Protobuf序列化
**简介:**Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python 三种语言的 API。
关于Protobuf序列化的只是,自行搜索学习,这里不做过多介绍
# HBase与MapReduce整合:读hdfs,写hbase
http://hbase.apache.org/book.html#mapreduce (opens new window)
# 运行主类
package cn.tiankafei.bigdata.hbase.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
/**
* @author tiankafei
* @since 1.0
**/
public class HBaseWordCountLocal {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(true);
System.setProperty("HADOOP_USER_NAME", "root");
conf.set("hbase.zookeeper.quorum","bigdata01,bigdata02,bigdata03,bigdata04");
// 让框架知道在windows上执行,需要设置为true
conf.set("mapreduce.app-submission.cross-platform", "true");
// 让框架在本地运行
conf.set("mapreduce.framework.name", "local");
Job job = Job.getInstance(conf);
job.setJarByClass(HBaseWordCountLocal.class);
// 指定job的名称
job.setJobName("tiankafei-hbase");
// 指定输入文件的路径
Path inFile = new Path("/data/wc/input");
TextInputFormat.addInputPath(job, inFile);
// 指定Map处理类
job.setMapperClass(HBaseWordCountMapper.class);
// 指定map的输出key类型
job.setMapOutputKeyClass(Text.class);
// 指定map的输出value类型
job.setMapOutputValueClass(IntWritable.class);
// 指定reduce处理类
TableMapReduceUtil.initTableReducerJob("wc", HBaseWordCountReduce.class, job, null, null, null, null, false);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Put.class);
job.waitForCompletion(true);
}
}
# Mapper
package cn.tiankafei.bigdata.hbase.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* @author tiankafei
* @since 1.0
**/
public class HBaseWordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer stringTokenizer = new StringTokenizer(value.toString());
while (stringTokenizer.hasMoreTokens()) {
word.set(stringTokenizer.nextToken());
context.write(word, one);
}
}
}
# Reduce
package cn.tiankafei.bigdata.hbase.wordcount;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import java.io.IOException;
import java.util.Iterator;
/**
* @author tiankafei
* @since 1.0
**/
public class HBaseWordCountReduce extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
Iterator<IntWritable> iterator = values.iterator();
if(iterator.hasNext()){
IntWritable next = iterator.next();
sum += next.get();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("word"), Bytes.toBytes(sum+""));
context.write(null, put);
}
}
# HBase与MapReduce整合:读hbase,写hdfs
# 运行主类
# Mapper
# Reduce
# HBase表设计
# 案例1:人员-角色(多对多)
人员有多个角色 角色有优先级
角色有多个人员
人员 添加删除角色
角色 添加删除人员
数据
人员编号
001
002
003
角色编号
100
200
300
# HBase表结构设计
# 人员表:person
disable 'person'
drop 'person'
create 'person', 'cf1', 'cf2'
put 'person', '001', 'cf1:name', '张三'
put 'person', '001', 'cf1:age', '12'
put 'person', '001', 'cf1:sex', 'man'
put 'person', '002', 'cf1:name', '李四'
put 'person', '002', 'cf1:age', '21'
put 'person', '002', 'cf1:sex', 'mv'
put 'person', '003', 'cf1:name', '王五'
put 'person', '003', 'cf1:age', '31'
put 'person', '003', 'cf1:sex', 'man'
put 'person', '001', 'cf2:100', '1'
put 'person', '001', 'cf2:200', '2'
put 'person', '002', 'cf2:200', '1'
put 'person', '003', 'cf2:300', '2'
scan 'person'
| rowkey(pid) | cf1(基本属性) | cf2(角色列表) |
|---|---|---|
| 001 | cf1:name='',cf:age=‘’,cf1:sex='' | cf2:rid=优先级,cf3:rid=优先级 |
| 002 | ||
| 003 |
# 角色表:rule
disable 'rule'
drop 'rule'
create 'rule', 'cf1', 'cf2'
put 'rule', '100', 'cf1:name', '教授'
put 'rule', '100', 'cf1:description', '教授的描述'
put 'rule', '200', 'cf1:name', '老师'
put 'rule', '200', 'cf1:description', '老师的描述'
put 'rule', '300', 'cf1:name', '学生'
put 'rule', '300', 'cf1:description', '学生的描述'
put 'rule', '100', 'cf2:001', '张三'
put 'rule', '200', 'cf2:001', '张三'
put 'rule', '200', 'cf2:002', '李四'
put 'rule', '300', 'cf2:003', '王五'
scan 'rule'
| rowkey(rid) | cf1(角色属性) | cf2(人员列表) |
|---|---|---|
| 100 | cf1:name='',cf2:description='' | cf2:pid=人员名称;cf2:pid=人员名称 |
| 200 | ||
| 300 |
# 删除人员的逻辑
根据人员id可以去cf2中找到所有的key值集合,
get 'person', '001'遍历得到的key值集合,能够拿到角色id,然后去角色表中,删除cf2指定key值等于当前人员id的数据
delete 'rule', '100', 'cf2:001' delete 'rule', '200', 'cf2:001'根据人员id删除人员信息
deleteall 'person', '001' scan 'person' scan 'rule'
# 删除角色的逻辑
根据角色id可以去cf2中找到所有的key值集合
get 'rule', '200'遍历得到的key值集合,能够拿到人员id,然后去人员表中,删除cf2指定key值等于当前角色id的数据
delete 'person', '002', 'cf2:200'根据角色id删除角色信息
deleteall 'rule', '200' scan 'person' scan 'rule'
# 案例2:部门-子部门(一对多)
查询 顶级部门
查询 每个部门的所有子部门
部门 添加、删除子部门
部门 添加、删除
# HBase表结构设计
disable 'dept'
drop 'dept'
create 'dept', 'cf1', 'cf2'
put 'dept', '0_000', 'cf1:name', 'CEO'
put 'dept', '0_000', 'cf2:1_001', '开发部'
put 'dept', '0_000', 'cf2:1_002', '前端'
put 'dept', '1_001', 'cf1:name', '开发部'
put 'dept', '1_001', 'cf1:pid', '0_000'
put 'dept', '1_001', 'cf2:2_001_001', '开发部1'
put 'dept', '1_001', 'cf2:2_001_002', '开发部2'
put 'dept', '2_001_001', 'cf1:name', '开发部1'
put 'dept', '2_001_001', 'cf1:pid', '1_001'
put 'dept', '2_001_002', 'cf1:name', '开发部2'
put 'dept', '2_001_002', 'cf1:pid', '1_001'
put 'dept', '1_002', 'cf1:name', '前端'
put 'dept', '1_002', 'cf1:pid', '0_000'
put 'dept', '1_002', 'cf2:2_002_001', '前端1'
put 'dept', '2_002_001', 'cf1:name', '前端1'
put 'dept', '2_002_001', 'cf1:pid', '1_002'
scan 'dept'
| rowkey(层级id_部门id) | cf1(部门基本信息) | cf2(子部门列表) |
|---|---|---|
| 0_000 | cf1:name='',,,,cf1:pid='父部门id' | cf2:子部门id=子部门名称 |
| 1_001 | ||
| 2_001_001 | ||
| 2_001_002 | ||
| 1_002 | ||
| 2_002_001 |
# 删除部门逻辑:如果有子部门也允许删除
- 根据部门id从cf1中查询pid,从cf2中查询子部门列表
- 根据pid查询父记录的子部门列表,把当前部门id,从父部门的子部门列表中删除
- 遍历当前部门的子部门列表,获取到其中一个子部门,再根据当前子部门id重复第3步,直到没有子部门为止,然后进行删除子部门,
- 最后根据当前部门id,删除本部门
# 案例3:微博表设计
添加删除关注
粉丝列表
写微博
查看首页,所有关注过的好友发布的最新微博
查看某个用户发布的所有微博,降序排序
# HBase表结构设计
# 粉丝和关注表
| rowkey(pid) | cf1(关注列表) | cf2(粉丝列表) |
|---|---|---|
| 001(小红) | cf1:002=小黑, | cf2:002=小黑,cf2:003=小白 |
| 002(小黑) | cf1:001=小红,cf1:003=小白 | cf2:001=小红,cf2:003=小白 |
| 003(小白) | cf1:001=小红,cf1:002=小黑 | cf2:002=小黑 |
# 微博表
| rowkey(pid_(long.maxValue-时间戳))->wid | cf1(微博信息) |
|---|---|
| pid_1561231321001213 | cf1:name='',cf1:context='',cf1:timestamp='' |
# 微博收取表
当前用户pid发了微博,就根据pid查询粉丝列表,给列表中的每一个用户的cf1增加一列,key为wid,值顺序自增。
disable 'wbsq'
drop 'wbsq'
//创建表
create 'wbsq', NAME => 'cf1', VERSIONS => 10000
describe 'wbsq'
put 'wbsq', '000', 'cf1:sq', '001'
put 'wbsq', '000', 'cf1:sq', '002'
put 'wbsq', '000', 'cf1:sq', '003'
put 'wbsq', '000', 'cf1:sq', '004'
put 'wbsq', '000', 'cf1:sq', '005'
put 'wbsq', '000', 'cf1:sq', '006'
-- 查看指定表,指定rowkey,指定列簇,指定列的所有版本的历史数据
get 'wbsq', '000', {COLUMN=>'cf1:sq', VERSIONS=>10000}
版本会自动根据时间戳排序
| rowkey(pid) | cf1(所有关注人发布微博的排序)(设置version=10000) |
|---|---|
| pid | cf1:sq=wid,cf1:sq=wid,cf1:sq=wid,cf1:sq=wid |
| pid | |
| pid |
# HBase优化
# 1. Pre-Creating Regions:预分区
默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。
//第一种实现方式是使用admin对象的切分策略
byte[] startKey = ...; // your lowest key
byte[] endKey = ...; // your highest key
int numberOfRegions = ...; // # of regions to create
admin.createTable(table, startKey, endKey, numberOfRegions);
//第二种实现方式是用户自定义切片
byte[][] splits = ...; // create your own splits
/*
byte[][] splits = new byte[][] { Bytes.toBytes("100"),
Bytes.toBytes("200"), Bytes.toBytes("400"),
Bytes.toBytes("500") };
*/
admin.createTable(table, splits);
# 2. Rowkey设计
# row key用来检索记录的三种方式
- 通过单个row key访问:即按照某个row key键值进行get操作;
- 通过row key的range进行scan:即通过设置startRowKey和endRowKey,在这个范围内进行扫描;
- 全表扫描:即直接扫描整张表中所有行记录。
在HBase中,rowkey可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,存为byte[]字节数组,一般设计成定长的。rowkey是按照字典序存储,因此,设计row key时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
# Rowkey设计原则
# 越短越好,提高效率
- 数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如操作100字节,1000万行数据,单单是存储rowkey的数据就要占用10亿个字节,将近1G数据,这样会影响HFile的存储效率。
- HBase中包含缓存机制,每次会将查询的结果暂时缓存到HBase的内存中,如果rowkey字段过长,内存的利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
# 散列原则--实现负载均衡
如果Rowkey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个 RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
- 加盐:添加随机值
- hash:采用md5散列算法取前4位做前缀
- 反转:将手机号反转
# 唯一原则--字典序排序存储
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
# 3. 列族的设计
# 不要在一张表里定义太多的column family
目前Hbase并不能很好的处理超过2~3个column family的表。因为某个column family在flush的时候,它邻近的column family也会因关联效应被触发flush,最终导致系统产生更多的I/O。
# 原因
- 当开始向hbase中插入数据的时候,数据会首先写入到memstore,而memstore是一个内存结构,每个列族对应一个memstore,当包含更多的列族的时候,会导致存在多个memstore,每一个memstore在flush的时候会对应一个hfile的文件,因此会产生很多的hfile文件,更加严重的是,flush操作是region级别,当region中的某个memstore被flush的时候,同一个region的其他memstore也会进行flush操作,当某一张表拥有很多列族的时候,且列族之间的数据分布不均匀的时候,会产生更多的磁盘文件。
- 当hbase表的某个region过大,会被拆分成两个,如果我们有多个列族,且这些列族之间的数据量相差悬殊的时候,region的split操作会导致原本数据量小的文件被进一步的拆分,而产生更多的小文件
- 与 Flush 操作一样,目前 HBase 的 Compaction (合并)操作也是 Region 级别的,过多的列族也会产生不必要的 IO。
- HDFS 其实对一个目录下的文件数有限制的(
dfs.namenode.fs-limits.max-directory-items)。如果我们有 N 个列族,M 个 Region,那么我们持久化到 HDFS 至少会产生 NM 个文件;而每个列族对应底层的 HFile 文件往往不止一个,我们假设为 K 个,那么最终表在 HDFS 目录下的文件数将是 NMK,这可能会操作 HDFS 的限制。
# 4. in memory:查询缓存
hbase在LRU缓存基础之上采用了分层设计,整个blockcache分成了三个部分,分别是single、multi和inMemory。
三者区别如下
- single:如果一个block第一次被访问,放在该优先队列中;
- multi:如果一个block被多次访问,则从single队列转移到multi队列
- inMemory:优先级最高,常驻cache,因此一般只有hbase系统的元数据,如meta表之类的才会放到inMemory队列中。
# 5. Max Version:最大版本
创建表的时候,可以通过ColumnFamilyDescriptorBuilder.setMaxVersions(int maxVersions)设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置setMaxVersions(1),保留更多的版本信息会占用更多的存储空间。
- 命令行方式:create 'wbsq', NAME => 'cf1', VERSIONS => 10000
- javaAPI方式:ColumnFamilyDescriptorBuilder.setMaxVersions(int maxVersions)
# 6. Time to Live:声明周期
创建表的时候,可以通过ColumnFamilyDescriptorBuilder.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么可以设置setTimeToLive(2 * 24 * 60 * 60)。
# 7. Compaction:合并操作
在HBase中,数据在更新时首先写入WAL 日志(HLog)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。于此同时, 系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了**(minor compact)**。
- StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并**(major compact),将对同一个key的修改合并到一起,形成一个大的StoreFile,当StoreFile的大小达到一定阈值后,又会对 StoreFile进行分割(split)**,等分为两个StoreFile。
- 由于对表的更新是不断追加的,处理读请求时,需要访问Store中全部的StoreFile和MemStore,将它们按照row key进行合并,由于StoreFile和MemStore都是经过排序的,并且StoreFile带有内存中索引,通常合并过程还是比较快的。
实际应用中,可以考虑必要时手动进行major compact,将同一个row key的修改进行合并形成一个大的StoreFile。同时,可以将StoreFile设置大些,减少split的发生。
- hbase为了防止小文件(被刷到磁盘的menstore)过多,以保证保证查询效率,hbase需要在必要的时候将这些小的store file合并成相对较大的store file,这个过程就称之为compaction。在hbase中,主要存在两种类型的compaction:minor compaction和major compaction。
# minor compaction:较小、很少文件的合并
minor compaction的运行机制要复杂一些,它由一下几个参数共同决定:
- hbase.hstore.compaction.min :默认值为 3,表示至少需要三个满足条件的store file时,minor compaction才会启动
- hbase.hstore.compaction.max 默认值为10,表示一次minor compaction中最多选取10个store file
- hbase.hstore.compaction.min.size 表示文件大小小于该值的store file 一定会加入到minor compaction的store file中
- hbase.hstore.compaction.max.size 表示文件大小大于该值的store file 一定不会被添加到minor compaction
hbase.hstore.compaction.ratio :将 StoreFile 按照文件年龄排序,minor compaction 总是从 older store file 开始选择,如果该文件的 size 小于后面 hbase.hstore.compaction.max 个 store file size 之和乘以 ratio 的值,那么该 store file 将加入到 minor compaction 中。如果满足 minor compaction 条件的文件数量大于 hbase.hstore.compaction.min,才会启动。
# major compaction:将所有的store file合并成一个
触发major compaction的可能条件有:
- major_compact 命令
- majorCompact() API
- region server自动运行
- hbase.hregion.majorcompaction 默认为24 小时
- hbase.hregion.majorcompaction.jetter 默认值为0.2 防止region server 在同一时间进行major compaction)
hbase.hregion.majorcompaction.jetter参数的作用是:对参数hbase.hregion.majorcompaction 规定的值起到浮动的作用,假如两个参数都为默认值24和0,2,那么major compact最终使用的数值为:19.2~28.8 这个范围。
# hbase写表操作
# 1. 是否需要写WAL?WAL是否需要同步写入?
# 优化原理
数据写入流程可以理解为一次顺序写WAL+一次写缓存,通常情况下写缓存延迟很低,因此提升写性能就只能从WAL入手。WAL机制一方面是为了确保数据即使写入缓存丢失也可以恢复,另一方面是为了集群之间异步复制。默认WAL机制开启且使用同步机制写入WAL。首先考虑业务是否需要写WAL,通常情况下大多数业务都会开启WAL机制(默认),但是对于部分业务可能并不特别关心异常情况下部分数据的丢失,而更关心数据写入吞吐量,比如某些推荐业务,这类业务即使丢失一部分用户行为数据可能对推荐结果并不构成很大影响,但是对于写入吞吐量要求很高,不能造成数据队列阻塞。这种场景下可以考虑关闭WAL写入,写入吞吐量可以提升2x~3x。退而求其次,有些业务不能接受不写WAL,但可以接受WAL异步写入,也是可以考虑优化的,通常也会带来1x~2x的性能提升。
# 优化推荐
根据业务关注点在WAL机制与写入吞吐量之间做出选择
# 2. Put是否可以同步批量提交?
# 优化原理
HBase分别提供了单条put以及批量put的API接口,使用批量put接口可以减少客户端到RegionServer之间的RPC连接数,提高写入性能。另外需要注意的是,批量put请求要么全部成功返回,要么抛出异常。
# 优化推荐
使用批量put进行写入请求
# 3. Put是否可以异步批量提交?
# 优化原理
业务如果可以接受异常情况下少量数据丢失的话,还可以使用异步批量提交的方式提交请求。提交分为两阶段执行:用户提交写请求之后,数据会写入客户端缓存,并返回用户写入成功;当客户端缓存达到阈值(默认2M)之后批量提交给RegionServer。需要注意的是,在某些情况下客户端异常的情况下缓存数据有可能丢失。
# 优化推荐
在业务可以接受的情况下开启异步批量提交
# 使用方式
setAutoFlush(false)
# 4. Region是否太少?
# 优化原理
当前集群中表的Region个数如果小于RegionServer个数,即Num(Region of Table) < Num(RegionServer),可以考虑切分Region并尽可能分布到不同RegionServer来提高系统请求并发度,如果Num(Region of Table) > Num(RegionServer),再增加Region个数效果并不明显。
# 优化建议
在Num(Region of Table) < Num(RegionServer)的场景下切分部分请求负载高的Region并迁移到其他RegionServer;
# 5. 写入请求是否不均衡?
# 优化原理
另一个需要考虑的问题是写入请求是否均衡,如果不均衡,一方面会导致系统并发度较低,另一方面也有可能造成部分节点负载很高,进而影响其他业务。分布式系统中特别害怕一个节点负载很高的情况,一个节点负载很高可能会拖慢整个集群,这是因为很多业务会使用Mutli批量提交读写请求,一旦其中一部分请求落到该节点无法得到及时响应,就会导致整个批量请求超时。因此不怕节点宕掉,就怕节点奄奄一息!
# 优化建议
检查RowKey设计以及预分区策略,保证写入请求均衡。
# 6. 写入KeyValue数据是否太大?
KeyValue大小对写入性能的影响巨大,一旦遇到写入性能比较差的情况,需要考虑是否由于写入KeyValue数据太大导致。
# 7. Utilize Flash storage for WAL(HBASE-12848)
这个特性意味着可以将WAL单独置于SSD上,这样即使在默认情况下(WALSync),写性能也会有很大的提升。需要注意的是,该特性建立在HDFS 2.6.0+的基础上,HDFS以前版本不支持该特性。具体可以参考官方jira:https://issues.apache.org/jira/browse/HBASE-12848
# 8. Multiple WALs(HBASE-14457)
该特性也是对WAL进行改造,当前WAL设计为一个RegionServer上所有Region共享一个WAL,可以想象在写入吞吐量较高的时候必然存在资源竞争,降低整体性能。针对这个问题,社区小伙伴(阿里巴巴大神)提出Multiple WALs机制,管理员可以为每个Namespace下的所有表设置一个共享WAL,通过这种方式,写性能大约可以提升20%~40%左右。具体可以参考官方jira:https://issues.apache.org/jira/browse/HBASE-14457
# hbase读表优化
# 1. scan缓存是否设置合理?
# 优化原理
在解释这个问题之前,首先需要解释什么是scan缓存,通常来讲一次scan会返回大量数据,因此客户端发起一次scan请求,实际并不会一次就将所有数据加载到本地,而是分成多次RPC请求进行加载,这样设计一方面是因为大量数据请求可能会导致网络带宽严重消耗进而影响其他业务,另一方面也有可能因为数据量太大导致本地客户端发生OOM。在这样的设计体系下用户会首先加载一部分数据到本地,然后遍历处理,再加载下一部分数据到本地处理,如此往复,直至所有数据都加载完成。数据加载到本地就存放在scan缓存中,默认100条数据大小。
通常情况下,默认的scan缓存设置就可以正常工作的。但是在一些大scan(一次scan可能需要查询几万甚至几十万行数据)来说,每次请求100条数据意味着一次scan需要几百甚至几千次RPC请求,这种交互的代价无疑是很大的。因此可以考虑将scan缓存设置增大,比如设为500或者1000就可能更加合适。笔者之前做过一次试验,在一次scan扫描10w+条数据量的条件下,将scan缓存从100增加到1000,可以有效降低scan请求的总体延迟,延迟基本降低了25%左右。
# 优化建议
大scan场景下将scan缓存从100增大到500或者1000,用以减少RPC次数
# 2. get请求是否可以使用批量请求?
# 优化原理
HBase分别提供了单条get以及批量get的API接口,使用批量get接口可以减少客户端到RegionServer之间的RPC连接数,提高读取性能。另外需要注意的是,批量get请求要么成功返回所有请求数据,要么抛出异常。
# 优化建议
使用批量get进行读取请求
# 3. 请求是否可以显示指定列族或者列?
# 优化原理
HBase是典型的列族数据库,意味着同一列族的数据存储在一起,不同列族的数据分开存储在不同的目录下。如果一个表有多个列族,只是根据Rowkey而不指定列族进行检索的话不同列族的数据需要独立进行检索,性能必然会比指定列族的查询差很多,很多情况下甚至会有2倍~3倍的性能损失。
# 优化建议
可以指定列族或者列进行精确查找的尽量指定查找
# 4. 离线批量读取请求是否设置禁止缓存?
# 优化原理
通常离线批量读取数据会进行一次性全表扫描,一方面数据量很大,另一方面请求只会执行一次。这种场景下如果使用scan默认设置,就会将数据从HDFS加载出来之后放到缓存。可想而知,大量数据进入缓存必将其他实时业务热点数据挤出,其他业务不得不从HDFS加载,进而会造成明显的读延迟。
# 优化建议
离线批量读取请求设置禁用缓存,scan.setBlockCache(false)
# 5. 读请求是否均衡?
# 优化原理
极端情况下假如所有的读请求都落在一台RegionServer的某几个Region上,这一方面不能发挥整个集群的并发处理能力,另一方面势必造成此台RegionServer资源严重消耗(比如IO耗尽、handler耗尽等),落在该台RegionServer上的其他业务会因此受到很大的波及。可见,读请求不均衡不仅会造成本身业务性能很差,还会严重影响其他业务。当然,写请求不均衡也会造成类似的问题,可见负载不均衡是HBase的大忌。
# 观察确认
观察所有RegionServer的读请求QPS曲线,确认是否存在读请求不均衡现象
# 优化建议
RowKey必须进行散列化处理(比如MD5散列),同时建表必须进行预分区处理
# 6. BlockCache是否设置合理?
# 优化原理
BlockCache作为读缓存,对于读性能来说至关重要。默认情况下BlockCache和Memstore的配置相对比较均衡(各占40%),可以根据集群业务进行修正,比如读多写少业务可以将BlockCache占比调大。另一方面,BlockCache的策略选择也很重要,不同策略对读性能来说影响并不是很大,但是对GC的影响却相当显著,尤其BucketCache的offheap模式下GC表现很优越。另外,HBase 2.0对offheap的改造(HBASE-11425)将会使HBase的读性能得到2~4倍的提升,同时GC表现会更好!
# 观察确认
观察所有RegionServer的缓存未命中率、配置文件相关配置项一级GC日志,确认BlockCache是否可以优化。
# 优化建议
JVM内存配置量 < 20G,BlockCache策略选择LRUBlockCache;否则选择BucketCache策略的offheap模式。
# 7. HFile文件是否太多?
# 优化原理
HBase读取数据通常首先会到Memstore和BlockCache中检索(读取最近写入数据&热点数据),如果查找不到就会到文件中检索。HBase的类LSM结构会导致每个store包含多数HFile文件,文件越多,检索所需的IO次数必然越多,读取延迟也就越高。文件数量通常取决于Compaction的执行策略,一般和两个配置参数有关:hbase.hstore.compaction.min和hbase.hstore.compaction.max.size,前者表示一个store中的文件数超过多少就应该进行合并,后者表示参数合并的文件大小最大是多少,超过此大小的文件不能参与合并。这两个参数不能设置太’松’(前者不能设置太大,后者不能设置太小),导致Compaction合并文件的实际效果不明显,进而很多文件得不到合并。这样就会导致HFile文件数变多。
# 观察确认
观察RegionServer级别以及Region级别的storefile数,确认HFile文件是否过多
# 优化建议
hbase.hstore.compaction.min设置不能太大,默认是3个;设置需要根据Region大小确定,通常可以简单的认为hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compaction.min
# 8. Compaction是否消耗系统资源过多?
# 优化原理
Compaction是将小文件合并为大文件,提高后续业务随机读性能,但是也会带来IO放大以及带宽消耗问题(数据远程读取以及三副本写入都会消耗系统带宽)。正常配置情况下Minor Compaction并不会带来很大的系统资源消耗,除非因为配置不合理导致Minor Compaction太过频繁,或者Region设置太大情况下发生Major Compaction。
# 观察确认
观察系统IO资源以及带宽资源使用情况,再观察Compaction队列长度,确认是否由于Compaction导致系统资源消耗过多。
# 优化建议
- Minor Compaction设置:hbase.hstore.compaction.min设置不能太小,又不能设置太大,因此建议设置为5~6;hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compaction.min
- Major Compaction设置:大Region读延迟敏感业务( 100G以上)通常不建议开启自动Major Compaction,手动低峰期触发。小Region或者延迟不敏感业务可以开启Major Compaction,但建议限制流量;
# 9. 数据本地率是否太低?
数据本地率:HDFS数据通常存储三份,假如当前RegionA处于Node1上,数据a写入的时候三副本为(Node1,Node2,Node3),数据b写入三副本是(Node1,Node4,Node5),数据c写入三副本(Node1,Node3,Node5),可以看出来所有数据写入本地Node1肯定会写一份,数据都在本地可以读到,因此数据本地率是100%。现在假设RegionA被迁移到了Node2上,只有数据a在该节点上,其他数据(b和c)读取只能远程跨节点读,本地率就为33%(假设a,b和c的数据大小相同)。
# 优化原理
数据本地率太低很显然会产生大量的跨网络IO请求,必然会导致读请求延迟较高,因此提高数据本地率可以有效优化随机读性能。数据本地率低的原因一般是因为Region迁移(自动balance开启、RegionServer宕机迁移、手动迁移等),因此一方面可以通过避免Region无故迁移来保持数据本地率,另一方面如果数据本地率很低,也可以通过执行major_compact提升数据本地率到100%。
# 优化建议
避免Region无故迁移,比如关闭自动balance、RS宕机及时拉起并迁回飘走的Region等;在业务低峰期执行major_compact提升数据本地率。