# sqoop的简单概论
# sqoop产生的原因
- 多数使用hadoop技术的处理大数据业务的企业,有大量的数据存储在关系型数据中。
- 由于没有工具支持,对hadoop和关系型数据库之间数据传输是一个很困难的事。
依据以上的原因,sqoop应运而生。
# sqoop的介绍
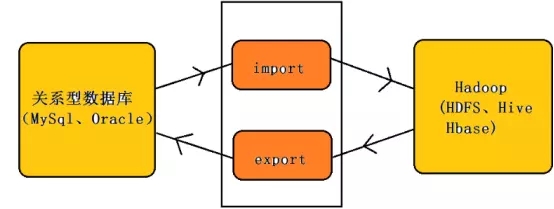
sqoop是连接关系型数据库和hadoop的桥梁,主要有两个方面(导入和导出):
- 将关系型数据库的数据导入到Hadoop 及其相关的系统中,如 Hive和HBase
- 将数据从Hadoop 系统里抽取并导出到关系型数据库
# Sqoop的优点
- 可以高效、可控的利用资源,可以通过调整任务数来控制任务的并发度。
- 可以自动的完成数据映射和转换。由于导入数据库是有类型的,它可以自动根据数据库中的类型转换到Hadoop 中,当然用户也可以自定义它们之间的映射关系。
- 支持多种数据库,如mysql,orcale等数据库
# sqoop工作的机制
将导入或导出命令翻译成MapReduce程序来实现在翻译出的,MapReduce 中主要是对InputFormat和OutputFormat进行定制
# sqoop版本介绍:sqoop1和sqoop2
sqoop的版本sqoop1和sqoop2是两个不同的版本,它们是完全不兼容的
版本划分方式: apache1.4.X之后的版本是1,1.99.0之上的版本是2
Sqoop2相比sqoop1的优势有:
- 它引入的sqoop Server,便于集中化的管理Connector或者其它的第三方插件;
- 多种访问方式:CLI、Web UI、REST API;
- 它引入了基于角色的安全机制,管理员可以在sqoop Server上配置不同的角色。
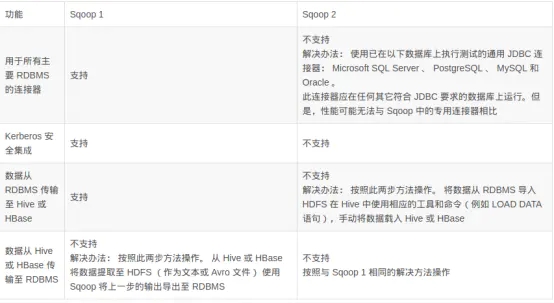
Sqoop2和sqoop1的功能性对比:
# sqoop1和sqoop2的架构区别
# sqoop1的架构图
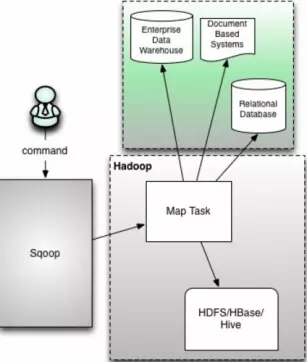
- 版本号:1.4.X以后的sqoop1
- 在架构上:sqoop1使用sqoop客户端直接提交代码方式
- 访问方式:CLI命令行控制台方式访问
- 安全性:命令或者脚本指定用户数据库名和密码
原理:Sqoop工具接收到客户端的shell命令或者Java api命令后,通过Sqoop中的任务翻译器(Task Translator)将命令转换为对应的MapReduce任务,而后将关系型数据库和Hadoop中的数据进行相互转移,进而完成数据的拷贝。
# sqoop2架构图
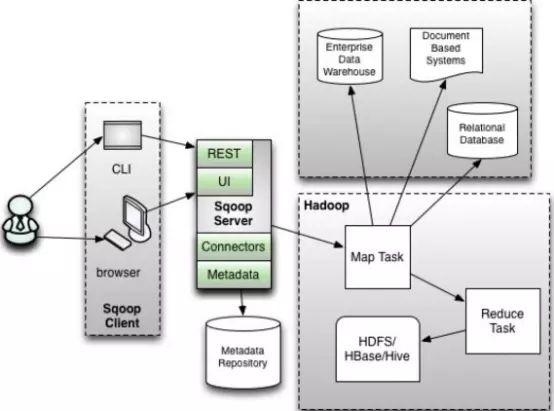
- 版本号:1.99.X以上的版本sqoop2
- 在架构上:sqoop2引入了 sqoop server,对对connector实现了集中的管理访问方式:REST API、 JAVA API、 WEB UI以及CLI控制台方式进行访问
- CLI方式访问,会通过交互过程界面 (opens new window),输入的密码信息会被看到,同时Sqoop2引入基亍角色的安全机制,Sqoop2比Sqoop多了一个Server端。
# Sqoop1和sqoop2优缺点
# sqoop1优点
架构部署简单
# sqoop1缺点
命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏,安装需要root权限,connector必须符合JDBC模型
# sqoop2优点
多种交互方式,命令行,web UI,rest API,conncetor集中化管理,所有的链接安装在sqoop server上,完善权限管理机制,connector规范化,仅仅负责数据的读写
# sqoop2缺点
sqoop2的缺点,架构稍复杂,配置部署更繁琐
# 安装sqoop1
# 安装前提
Sqoop需要安装在hive,hbase的服务器上,linux环境中必须有java和hadoop环境
Java 1.8.0_161
Hadoop 2.8.5
# 下载软件
# 软件下载地址:
http://mirrors.hust.edu.cn/apache/sqoop
此处下载的软件是sqoop1的软件包:sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
# 安装sqoop
tar -zvxf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mv sqoop-1.4.7.bin__hadoop-2.6.0 /opt/bigdata/
cd /opt/bigdata/
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.7
# 修改配置文件
cd /opt/bigdata/sqoop-1.4.7/conf
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/bigdata/hadoop-2.8.3-ha/hadoop-2.8.3
export HADOOP_MAPRED_HOME=/opt/bigdata/hadoop-2.8.3-ha/hadoop-2.8.3
export HIVE_HOME=/opt/bigdata/apache-hive-2.3.6
如果环境变量已经配置过hadoop和hive的配置,这里可以不用进行配置。
在apache的hadoop的安装中四大组件都是安装在同一个hadoop_home中的,但是在CDH, HDP中, 这些组件都是可选的。在安装hadoop的时候,可以选择性的只安装HDFS或者YARN。CDH,HDP在安装hadoop的时候,会把HDFS和MapReduce有可能分别安装在不同的地方。
CDH(Cloudera’s Distribution, including Apache Hadoop),是Hadoop众多分支中的一种,由Cloudera维护,基于稳定版本的Apache Hadoop构建,并集成了很多补丁,可直接用于生产环境。
HDP(Hortonworks Data Platform)是hortworks推出的100%开源的hadoop发行版本,以YARN 作为其架构中心,包含pig、hive、phoniex、hbase、storm、spark等大量组件,在最新的2.4版本,监控UI实现与grafana集成。
# 将mysql的驱动包放到sqoop的lib目录下
cp mysql-connector-java-5.1.48.jar /opt/bigdata/sqoop-1.4.7/lib
# 修改环境变量
vim /etc/profile
export SQOOP_HOME=/opt/bigdata/sqoop-1.4.7
export PATH=$PATH:$SQOOP_HOME/bin
source /etc/profile
# 安装显示
# Sqoop的使用
# 查看数据库的名称
sqoop list-databases --connect jdbc:mysql://ip:3306/ --username 用户名--password 密码
# 列举出数据库中的表名
sqoop list-tables --connect jdbc:mysql://ip:3306/数据库名称 --username 用户名 --password 密码
# 导入
sqoop import
--connect jdbc:mysql://ip:3306/databasename #指定JDBC的URL其中database指的是(Mysql或者Oracle)中的数据库名
--table tablename #要读取数据库database中的表名
--username root #用户名
--password 123456 #密码
--target-dir /path #指的是HDFS中导入表的存放目录(注意:是目录)
--fields-terminated-by '\t' #设定导入数据后每个字段的分隔符,默认;分隔
--lines-terminated-by '\n' #设定导入数据后每行的分隔符
--m 1 #并发的map数量1,如果不设置默认启动4个map task执行数据导入,则需要指定一个列来作为划分map task任务的依据
-- where '查询条件' #导入查询出来的内容,表的子集
--incremental append #增量导入
--check-column:column_id #指定增量导入时的参考列
--last-value:num #上一次导入column_id的最后一个值
--null-string '' #导入的字段为空时,用指定的字符进行替换
# 以上导入到hdfs中
--hive-import #导入到hive
--hive-overwrite #可以多次写入
--hive-database databasename #创建数据库,如果数据库不存在的必须写,默认存放在default中
--create-hive-table #sqoop默认自动创建hive表
--delete-target-dir #删除中间结果数据目录
--hive-table tablename #创建表名
# 导入所有的表放到hdfs中
sqoop import-all-tables --connect jdbc:mysql://ip:3306/库名 --username 用户名 --password 密码 --target-dir 导入存放的目录
# 导出(目标表必须在mysql数据库中已经建好,数据存放在hdfs中)
sqoop export
--connect jdbs:mysql://ip:3600/库名 #指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
--username用户名 #数据库的用户名
--password密码 #数据库的密码
--table表名 #需要导入到数据库中的表名
--export-dir导入数据的名称 #hdfs上的数据文件
--fields-terminated-by ‘\t’ #HDFS中被导出的文件字段之间的分隔符
--lines-terminated-by '\n' #设定导入数据后每行的分隔符
--m 1 #并发的map数量1,如果不设置默认启动4个map task执行数据导入,则需要指定一个列来作为划分map task任务的依据
--incremental append #增量导入
--check-column:column_id #指定增量导入时的参考列
--last-value:num #上一次导入column_id的最后一个值
--null-string '' #导出的字段为空时,用指定的字符进行替换
# 创建和维护sqoop作业:sqoop作业创建并保存导入和导出命令
# 创建作业
sqoop job --create作业名 -- import --connect jdbc:mysql://ip:3306/数据库 --username 用户名 --table 表名 --password 密码 --m 1 --target-dir 存放目录
# 验证作业(显示已经保存的作业)
sqoop job --list
# 显示作业详细信息
sqoop job --show作业名称
# 删除作业
sqoop job --delete作业名
# 执行作业
sqoop job --exec作业
# eval
它允许用户针对各自的数据库服务器执行用户定义的查询,并在控制台中预览结果,可以使用期望导入结果数据。
选择查询:
sqoop eval -connect jdbc:mysql://ip:3306/数据库 --username 用户名 --password 密码 --query "select * from emp limit 1" $CONDITIONS'
插入查询
sqoop eval jdbc:mysql://ip:3306/数据库 --username 用户名 --password 密码 --query "insert into emp values(4,'ceshi','hebei')" $CONDITIONS'
# codegen
从面向对象的应用程序的角度来看,每个数据库表都有一个DAO类,它包含用于初始化对象的'getter'和'setter'方法。该工具(-codegen)自动生成DAO类。
它根据表模式结构在Java中生成DAO类。Java定义被实例化为导入过程的一部分。这个工具的主要用途是检查Java是否丢失了Java代码。如果是这样,它将使用字段之间的默认分隔符创建Java的新版本,其实就是生成表名.java。
# 语法:sqoop codegen --connectjdbc:mysql://ip:3306/数据库 --username 用户名 --table 表名 --m 1 --password 密码
← Flume Centos7安装Scala →